Home

![]()
toaster aims at combining powers of Aster parallel and distributed database, its analytical engines with versatility of R. toaster functions accomplish this in 2 steps:
- compute results in Aster database
- use results to analyze and create visualizations in R
The latest released version of toaster is available from CRAN here. Install this version in R with:
install.packages("toaster")For the latest development version from GitHub repository use commands:
## install devtools, if you don’t already have the package
install.packages(‘devtools’)
## install toaster from github
install_github(‘teradata-aster-field/toaster’)In R to use the package functions without name prefix like toaster:: first run command
## load the namespace of toaster and attach it on the search list
library(toaster)toaster depends on package RODBC to connect to Aster. It uses its connection object:
dsn = "MyAsterDbDSN"
conn = odbcConnect(dsn)Or connect without defining an ODBC data source (Aster ODBC driver must still be installed):
conn = odbcDriverConnect(connection="driver={Aster ODBC Driver};server=xx.xx.xx.xx;port=2406;database=beehive;uid=beehive;pwd=beehive",
interpretDot=TRUE)Either method creates valid ODBC connection object:
odbcGetInfo(conn)
#> RODBC Connection 1
#> Details:
#> case=nochange
#> DRIVER={Aster ODBC Driver}
#> DATABASE=beehive
#> PORT=2406
#> PWD=******
#> SERVER=xx.xx.xx.xx
#> UID=beehiveDemo data sets to run examples
Intro to toaster with examples
K-means with Aster and toaster
Fast Track to Aster Graph Database with R and toaster
Scripting Parallel Jobs on Aster in R
Intro to toaster (work in progress)
Scripting Jobs in R to Run in Parallel on Aster
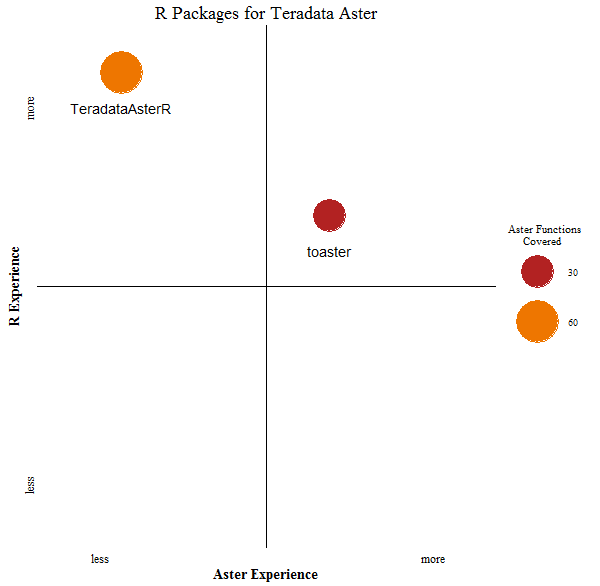
Teradata offers official package TeradataAsterR that works with Aster. The goals and philosophy behind it and toaster are different and in many ways are complimentary.
TeradataAsterR strives to project Aster functionality onto R environment using Aster Virtual Objects (virtual data frame, virtual list, etc.) as an intermediary form. The goal is to minimize or eliminate all together overhead of learning and manipulating Aster database artifacts (tables, SQL, SQL/MR, etc.) by offering data scientist familiar R objects and functions.
toaster aims at elevating Aster functionality to higher level functions that are reusable, general and delivering immediate value. It’s not about compatibility with conventional R objects and functions (but tries to look familiar if it doesn't create overhead). toaster brings dependencies from variety of other CRAN packages embracing best of breed approach.
It was a matter of taste (and practical choice) to use R – it could have been Python or Julia instead – and it would still contain similar set of functions albeit different syntax and conventions. Yes, and toaster is open-source project hosted on github so it's available for cloning, forking, pull requests, etc.
Lastly, picture below illustrates some of the points and, of course, it’s neither precise nor complete and shouldn’t be taken literally.
How to contribute to toaster and other developer resources
toAster icon is courtesy of Madison Clarke