-
Notifications
You must be signed in to change notification settings - Fork 840
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
4 changed files
with
405 additions
and
106 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -9,7 +9,7 @@ | |
| "\n", | ||
| "Speaker diarization is the process of partitioning an audio stream containing human speech into homogeneous segments according to the identity of each speaker. It can enhance the readability of an automatic speech transcription by structuring the audio stream into speaker turns and, when used together with speaker recognition systems, by providing the speaker’s true identity. It is used to answer the question \"who spoke when?\"\n", | ||
| "\n", | ||
| "\n", | ||
| "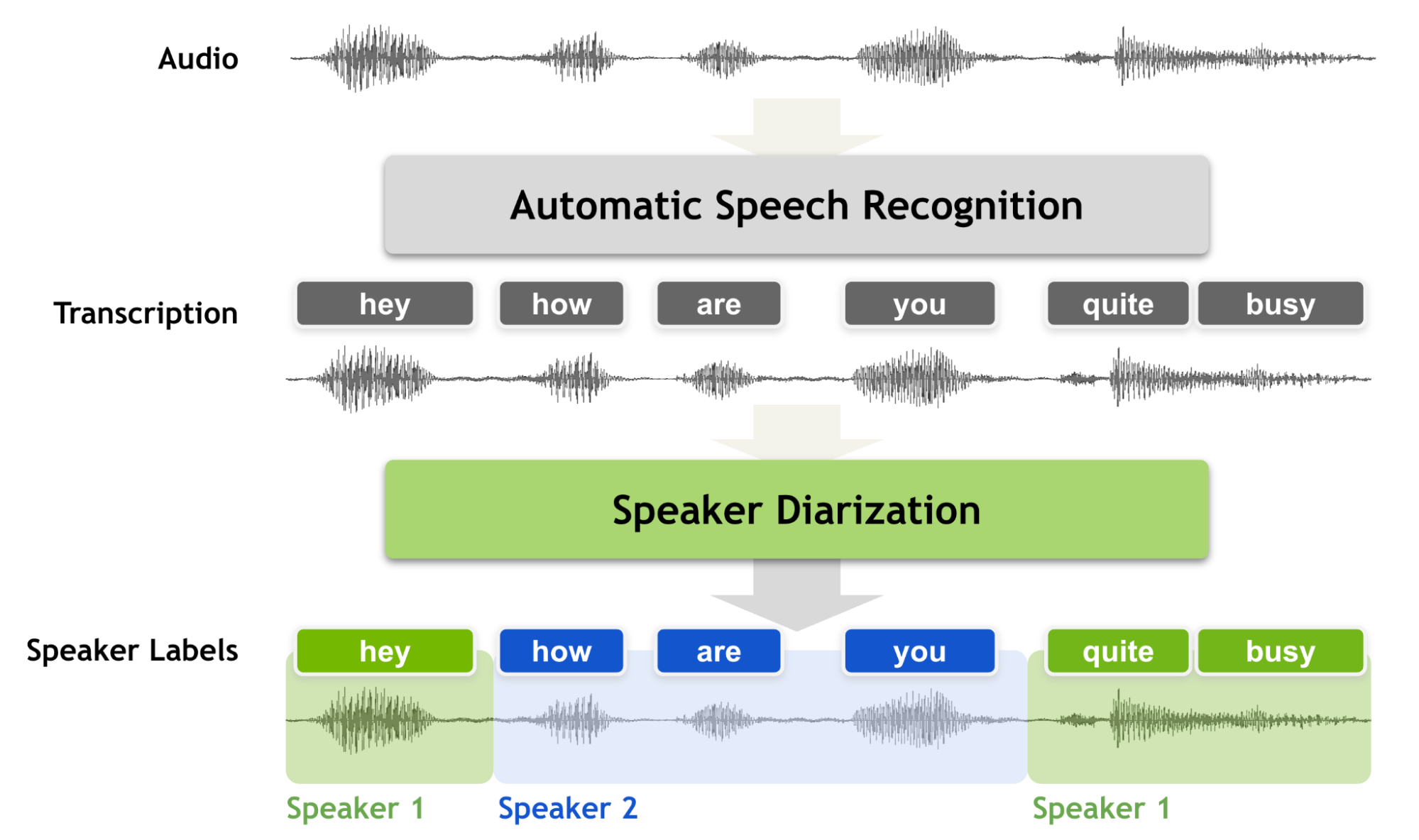\n", | ||
| "\n", | ||
| "With the increasing number of broadcasts, meeting recordings and voice mail collected every year, speaker diarization has received much attention by the speech community. Speaker diarization is an essential feature for a speech recognition system to enrich the transcription with speaker labels.\n", | ||
| "\n", | ||
|
|
@@ -49,7 +49,7 @@ | |
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "%pip install -q librosa>=0.8.1 \"ruamel.yaml>=0.17.8,<0.17.29\" --extra-index-url https://download.pytorch.org/whl/cpu torch torchvision torchaudio git+https://github.com/eaidova/[email protected] openvino>=2023.1.0" | ||
| "%pip install -q \"librosa>=0.8.1\" \"matplotlib<3.8\" \"ruamel.yaml>=0.17.8,<0.17.29\" --extra-index-url https://download.pytorch.org/whl/cpu torch torchvision torchaudio git+https://github.com/eaidova/[email protected] openvino>=2023.1.0" | ||
| ] | ||
| }, | ||
| { | ||
|
|
@@ -98,7 +98,6 @@ | |
| "```python\n", | ||
| "\n", | ||
| "## login to huggingfacehub to get access to pre-trained model\n", | ||
| "[back to top ⬆️](#Table-of-contents:)\n", | ||
| "from huggingface_hub import notebook_login, whoami\n", | ||
| "\n", | ||
| "try:\n", | ||
|
|
@@ -336,7 +335,7 @@ | |
| "## Convert model to OpenVINO Intermediate Representation format\n", | ||
| "[back to top ⬆️](#Table-of-contents:)\n", | ||
| "\n", | ||
| "For best results with OpenVINO, it is recommended to convert the model to OpenVINO IR format. OpenVINO supports PyTorch via ONNX conversion. We will use `torch.onnx.export` for exporting the ONNX model from PyTorch. We need to provide initialized model's instance and example of inputs for shape inference. We will use `mo.convert_model` functionality to convert the ONNX models. The `mo.convert_model` Python function returns an OpenVINO model ready to load on the device and start making predictions. We can save it on disk for the next usage with `openvino.runtime.serialize`." | ||
| "For best results with OpenVINO, it is recommended to convert the model to OpenVINO IR format. OpenVINO supports PyTorch via ONNX conversion. We will use `torch.onnx.export` for exporting the ONNX model from PyTorch. We need to provide initialized model's instance and example of inputs for shape inference. We will use `ov.convert_model` functionality to convert the ONNX models. The `mo.convert_model` Python function returns an OpenVINO model ready to load on the device and start making predictions. We can save it on disk for the next usage with `ov.save_model`." | ||
| ] | ||
| }, | ||
| { | ||
|
|
@@ -567,7 +566,7 @@ | |
| ], | ||
| "metadata": { | ||
| "kernelspec": { | ||
| "display_name": "Python 3", | ||
| "display_name": "Python 3 (ipykernel)", | ||
| "language": "python", | ||
| "name": "python3" | ||
| }, | ||
|
|
@@ -581,7 +580,7 @@ | |
| "name": "python", | ||
| "nbconvert_exporter": "python", | ||
| "pygments_lexer": "ipython3", | ||
| "version": "3.11.5" | ||
| "version": "3.8.10" | ||
| }, | ||
| "vscode": { | ||
| "interpreter": { | ||
|
|
@@ -598,4 +597,4 @@ | |
| }, | ||
| "nbformat": 4, | ||
| "nbformat_minor": 5 | ||
| } | ||
| } | ||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.