ContinueAsNew in Temporal (or Cadence) workflow
Based on Long's Medium article. This version focuses on using Temporal/Candence with GoSDK, just like iWF does.
NOTE: the term “Temporal” is used here to represent both Cadence and Temporal to make it easier to read.
Temporal has a 50K history event length limit and 50MB size limit for each execution. If the workflows reach the limit, the Temporal server will immediately terminate them.
In fact, server and worker performance will be significantly degraded if the workflow history length is over ~10K events, or even earlier (especially for workflows built by Java SDK, however, iWF uses Go SDK). This is because the replay mechanism requires a full history to be downloaded to the worker locally. Replaying a long history will consume a lot of network IO, memory and CPU.
As a result, continue as new is needed to avoid running into the history scalability issue.
Also, continueAsNew will help reduce costs if you are using Temporal Cloud. The open storage will be smaller after a continueAsNew, and the old events will be deleted after a retention period.
This page is to provide some guidance to implement “Continue As New” in a Temporal workflow. We start with some basic concepts and then explore different aspects of implementing “continueAsNew” in a safe, scalable, and reliable way.
The goal is to provide a comprehensive guide for implementing continueAsNew. It’s not for providing a lot of details of all the basics of Temporal workflow. It assumes you are already familiar with the basic concepts and APIs, and the key concept — workflow task in Temporal.
iWF as a Temporal abstraction/framework, has already implemented continueAsNew underneath. This article uses iWF as example to show how to implement it and provide a summary of how it’s implemented so that people can better understand iWF.
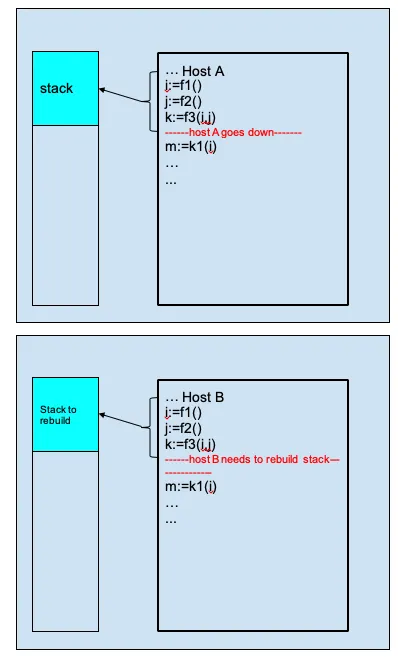
This “unique” concept only exists for replay-based programming models like Temporal. (It also exists in other replay-based workflow engines like SWF and Azure Durable Function).
In a replay-based workflow definition, a user workflow is defined as a single or “monolithic” function to run. Based on the history events, the function is required to be ready to be “replayed” anytime.
The replay will happen in many situations — for example, when worker goes down, and another worker will pick up the workflow to execute.
(source: Cadence docs)
As a result, replay requires user workflow code to be “replay-safe”, which is often said as “deterministic”.
As another result, replay also requires “continueAsNew” to get a freshly new & short history:
In this case, the user workflow decides to
- pause making progress in current workflow function execution
- pack all the stack states into a variable as a “snapshot”
- call the continueAsNew API with the snapshot, which in essence, the workflow function will be called with this snapshot by the server
- the workflow function must be able to rebuild all the states with the snapshot passed in before continuing to run
- resume the workflow to make progress
class MyWorkflowImpl implements MyWorkflow{
void start(Input input){
if(input.isFromContinueAsNew()){
rebuildEverything(input);
}
...
if(shouldContinueAsNew(...)){
// it's time to do a continueAsNew
Input snapshot = collectCurrentStatesAsSnapshot(...);
throw Workflow.newContinueAsNewError(snapshot);
}
...
}
}
It looks simple but raises questions like:
- What if the workflow is being blocked at something — timer, activity, signal, child workflow, etc?
- What about the other threads running in parallel other than this main thread?
- What about the signals that haven’t been processed yet?
- What if the data being passed as snapshot is too big?
- How to test the code?
Without figuring out the details, it’s impossible to safely/reliably implement continueAsNew.
ContinueAsNew is a “workaround” for limitation rather than a “feature”. Ideally, users shouldn’t need to know about it. Could replay-based workflow do this automatically underneath?
Only in theory or very long future.
The root problem is that user workflow code is written in native programming languages. It’s nearly impossible for the workflow engines to collect the “snapshot”, and rebuild automatically.
Doing this in a naive way essentially means that Temporal SDKs will have to create a snapshot of all the process states (heap, off-heap, thread stacks), and then rebuild the process state which is not feasible.
- Everything in iWF becomes “explicit” instead of “implicit”. The state transition, data storage, etc. Everything is clearly explicit between the user workflow code and server by the API contract.
- Or simply put, iWF doesn’t “replay” user workflow code at all.
It’s always recommended to avoid long history, which will avoid continueAsNew, if possible.
That's because implementing continueAsNew is not trivial, no matter how simple a workflow is. Even with the most simple form, further maintenance would also be a lot of overhead.
As stated earlier, replaying a workflow execution with just a few thousand events shouldn't be a problem. Limiting the workflow history size within that number makes it safe enough.
Here are some tips for designing the workflows:
- Break workflow into smaller ones, rather than building a giant workflow to do everything
- Use ChildWorkflow, or separate workflows
- Use long-running activity with heartbeats instead of a loop of activities
- Set a limit on how many signals a workflow can accept
In essence, try to limit the number of “steps” a workflow can execute to a reasonable number, which may depend on the product requirements.
Although this is not always possible, especially since product decisions can change all the time. It’s also important that to prepare and design for it as early as possible if you know that the workflow needs continueAsNew.
No one wants to drop a received signal.
The main issue is a possible misunderstanding of “received” signals. You may think your workflow has processed all “received” signals, but in fact, it has not.
On a high level, signals are delivered with workflow task. If workflow code proactively receiving signals, then it needs to make sure all the signals in the workflow task has been processed by calling the API until all signals are received — which is called “drained” here.
Implementing continueAsNew for the Golang SDK is a common mistake because the SDK requires the user to proactively receive signals in the code.
Therefore, if using APIs to proactively receive signals like Golang ReceiveChanel, you need to do drainAllSignalsInOneWorkflowTask like below:
...
if(shouldContinueAsNew(...)){
// it's time to do a continueAsNew
// drain all signals, or will may lose some data during continueAsNew
drainAllSignalsInOneWorkflowTask();
Input snapshot = collectCurrentStatesAsSnapshot(...);
throw Workflow.newContinueAsNewError(snapshot);
}
...
Give a thought here for “InOneWorkflowTask”. This is extremely important.
If the draining cannot be done within a single workflow task, it won’t guarantee anything. For example, if it executes an activity inside, it will schedule and complete in a different workflow task. During a different workflow task, there could be a new signal received, and then continueAsNew will then lose the new signals.
Therefore, make sure you don’t have any “blocking workflow API calls” in the drainAllSignalsInOneWorkflowTask implementation — like execute activities, creating and waiting for timers, childWorkflow, etc.
Mostly, drainAllSignalsInOneWorkflowTask can:
- Store the signal values in the snapshot that is to be built
- Process the signal in a non-blocking way — upsertSearchAttribute or complete or fail the workflow
So here is the implementation of the iWF for draining all signals, which is called before continueAsNew API is called.
In draining the signals, it only mutates the workflow in-memory variables without making any blocking API calls.
Before actually calling the continueAsNew API, it may fail the workflow early, but won’t make another other blocking API call.
When proactively receiving and processing all the signals received, if you know all the signal names:
- use Temporal’s “Len()” API to check if any un-processed signals
- use selector “Default” method to set a flag to indicate that all signals are received from the channel.
However, in a very dynamic workflow like iWF, the workflow doesn’t know all the signal names beforehand. In that case, iWF uses a special API from Cadence/Temporal called GetUnhandledSignalNames.
This racing condition is a popular question.
When the workflow task is completed and the response is returned to the server, another signal could arrive that needs to be processed.
This signal is also considered “received” from the application’s point of view. If the workflow doesn’t process it, the signal will be lost.
The answer is that Cadence/Temporal will handle this case nicely for you!
Basically, the server can either reject the workflow task completion response or carry over the signals automatically to the next run.
The first one is the existing behavior. Temporal is working on the latter behavior for a better experience — but either way, to your workflow code, it’s the same that this edge case won’t be a problem without doing anything.
ContinueAsNew got a lot more complicated if you use “multiple-threading” in a workflow.
First, the continueAsNew API has to be called in the main thread. But what happens to the other threads running in parallel?
Because they are running in parallel, suddenly calling the continueAsNew API in the main thread will cause some unexpected behaviors to the workflow:
- The activity/timer in the sub-threads could be started but not completed
- The activity could just completed with results but not processed properly
- Etc.
The safest way is to merge all the threads, just like calling “Join” API in some multi-threading world (like Java/Python).
A workflow code can start a new thread explicitly.
In Golang SDK, it’s
workflow.Go(ctx, fn(...)
Or implicitly — signal to handle threads
It’s important not to forget the signal handling threads for SDKs that use signal handlers to receive/process signals (ex. Java SDK).
The SDK automatically creates/starts the threads. The implicitness of the sub-threads makes it easier to forget, but they are still different threads.
For example, if the signal handling function executes an activity, it will have race conditions with continueAsNew, like above.
There are some options when merging the sub-threads:
- Wait for the sub-threads to complete
- Let the sub-thread return early
- Make the signal handling threads “non-blocking”
Either way, the main thread must be able to wait for the return of the sub-thread.
In Golang SDK, you could use workflow.Await(...) API to do that.
Or make the signal handling threads “non-blocking”
If the signal-handling threads are “non-blocking”, then you don’t have to drain the threads. Since they are invoked before other threads, it won’t lose any signals.
The best way to implement this, is to use the “signalQueue” patten to process the signal, and process the signal in the main thread or other threads.
However, as the signalQueue pattern stores the received signals in a queue, your workflow has to make sure to process all the signals in the queue or carry over to the next run with continueAsNew.
iWF took a slightly more advanced approach to wait for the sub-threads. This is because there could be unbounded sub-threads in iWF.
iWF has a wrapper of the workflow.Go(...) API, which track the thread started and completed.
type workflowProvider struct {
threadCount int
pendingThreadNames map[string]int
}
func (w *workflowProvider) GoNamed(ctx interpreter.UnifiedContext, name string, f func(ctx interpreter.UnifiedContext)) {
wfCtx, ok := ctx.GetContext().(workflow.Context)
if !ok {
panic("cannot convert to temporal workflow context")
}
f2 := func(ctx workflow.Context) {
ctx2 := interpreter.NewUnifiedContext(ctx)
w.pendingThreadNames[name]++
w.threadCount++
f(ctx2)
w.pendingThreadNames[name]--
if w.pendingThreadNames[name] == 0 {
delete(w.pendingThreadNames, name)
}
w.threadCount--
}
workflow.GoNamed(wfCtx, name, f2)
}
func (w *workflowProvider) GetPendingThreadNames() map[string]int {
return w.pendingThreadNames
}
func (w *workflowProvider) GetThreadCount() int {
The wrapper is also related to the fact that iWF has to support both Cadence and Temporal without any duplicate code.
Therefore, the workflow code can just check the sub-thread count in a workflow.Await(…) API call.
It’s also important to ensure the ordering: draining sub-threads before draining signals.
This is because draining sub-threads could involve some “blocking API calls.” If draining signals first, then new signals could arrive during the draining of sub-threads, and as a result, the newly arrived signals could be lost.
Until now, your workflow code may be like this to drain threads and signals.
...
if(shouldContinueAsNew(...)){
// it's time to do a continueAsNew
drainAllSubThreads();
drainAllSignalsInOneWorkflowTask();
Input snapshot = collectCurrentStatesAsSnapshot(...);
throw Workflow.newContinueAsNewError(snapshot);
}
...
This is a base of the real production iWF code to drain the threads. The implementation is more complicated because we also have to optimize the workflow, so that if a workflow can fail/complete early, and let it fail/complete before continueAsNew, but this should give enough understand to the feature and its implementation. To understand it fully please study the production code.