This repository contains the MIVS dataset and codes to train our BiRGAT model in the paper A BiRGAT Model for Multi-intent Spoken Language Understanding with Hierarchical Semantic Frames.
The required python packages is listed in "requirements.txt". You can install them by
pip install -r requirements.txt
or
conda install --file requirements.txt
The multi-intent MIVS dataset contains 5 different domains, namely map, weather, phone, in-vehicle control and music. The entire dataset can be split into two parts: single-domain and multi-domain. Single-domain examples contain both single-intent and multi-intent cases, which are collected and manually annotated from a realistic industrial in-vehicle environment. For cross-domain samples, we automatically synthesize them following MixATIS. Concretely, we extract two utterances from two different domains and concatenate them by conjunction words such as and.

MIVS dataset contains
| Domains | # Intents | # Slots | # Train | # Valid | # Test |
|---|---|---|---|---|---|
| in-vehicle control | 3 | 18 | 16000 | 2000 | 2000 |
| map | 6 | 16 | 4000 | 500 | 500 |
| music | 7 | 27 | 4000 | 500 | 500 |
| weather | 18 | 24 | 4000 | 500 | 500 |
| phone | 8 | 13 | 3249 | 500 | 491 |
| total | 42 | 98 | 31249 | 4000 | 3991 |
For the multi-domain partition, we synthesize examples for all
| Domains | avg. domain | avg. intent | avg. slot |
|---|---|---|---|
| TOPv2 | 1 | 1.1 | 1.8 |
| MIVS | 1.6 | 2.3 | 6.3 |
Preventing leakage of personal identifiable information (PII) is one major concern in practical deployment. To handle privacy constraints, we carry out a slot-based manual check followed by automatic substitution. For example, we discover that the sensitive information mainly lies in two slots "contact person" and "phone number" in domain phone. For anonymity consideration, we replace the person name with one placeholder from a pool of popular names. Similarly, the phone number is also substituted with a randomly sampled digit sequence of the equivalent length.
The original outputs in TOPv2 is organized as a token sequence, including raw question words and ontology items, exemplified in following table. We convert the target semantic representation into the same format as MIVS based on the following criterion:
- Names of intents and slots are simplified into meaningful lowercased English words. The prefix
IN:orSL:is removed, and the underscore_is replaced with a whitespace. - Only question words bounded with slots are preserved and treated as slot values, while words wrapped by intents are ignored. Notice that in TOPv2, intents can also be children of slots~(the second example in the following table). In this case, the word
tomorrowsin the scope of this child intentIN:GET_TIMEis part of the slot valuetomorrows alarmsfor the outer slotSL:ALARM_NAME. - The nested intent and its children slots are extracted and treated as the right sibling of the current intent. For example, in the second case of the below table, the inner intent
IN:GET_TIMEand its child slot-value pairSL:DATE_TIME=tomorrowsare treated as a separate sub-tree under the domainalarm. - In total,
$23$ data samples are removed which contain slots without slot values.

Please unzip the file in the data folder, i.e., data/aispeech.zip and data/topv2.zip, which correspond to our proposed MIVS dataset and the converted TOPV2 dataset, respectively.
After unzipping the data files, you will get the following folder structure:
- train:
- cross_data: Each file in this directory contains samples from two domains
- one_domain_data: Each file in this directory contains samples from a single domain
- null_data: Contains only one file, null.json, with empty parsing results
- cross_data_multi: An enhanced version of cross_data, where "车载控制_multi" is more challenging than "车载控制," and "车载控制_multi_5_10" is too complex and is not considered for now
- valid: Same structure as the train directory
- test: Same structure as the train directory
- ontology.json: Entire ontology file of the whole dataset
First, we need to do preprocessing and aggregate all ontology information, then build the relationship matrix between different ontologies:
./run/run_preprocessing.sh
By running different scripts, we can train different models and evaluate on the validation and test sets during training. swv, small, and base indicate using only static word vectors from pre-trained models, using small-series pre-trained models, and using base-series pre-trained models, respectively.
./run/run_train_and_eval_swv.sh
./run/run_train_and_eval_small.sh
./run/run_train_and_eval_base.sh
Evaluate the model on the validation and test sets: (Specify the directory of the saved model)
./run/run_eval.sh [dir_to_saved_model]
--files: Used to specify input file names (excluding the .json extension) to be recursively searched for and read from the data directory, e.g.,--files 地图 天气 地图_cross_天气means reading three files from the respective data directories:地图.json,天气.json, and地图_cross_天气.json. Additionally, there are special values such asall(read all data),single_domain(read all single-domain data), andcross_domain(read all cross-domain data) (seeprocess/dataset_utils.pyfor more details).--src_filesand--tgt_files: Similar to--files, but with higher priority.srcrepresents data files used for training, andtgtrepresents files used for testing. Both can be used for transfer learning experiments. If neither parameter is specified, it defaults to using the data files specified by--files.--domains: Used to specify input domains, e.g.,--domains 地图 天气means that all read data will use the two domains地图and天气, even if a data sample only involves the地图domain. If this parameter is not specified (default isNone), the default domain for each sample will be automatically used (which could be one or two domains). If this parameter is specified, please ensure that it includes all the domains of the data being read (the program also checks this when reading data files).--init_method [swv|plm]: Indicates the initialization method for embedding vectors, either initializing from static word vectors of pre-trained models (swv) or using the complete pre-trained model (plm).--ontology_encoding: Specifies whether to use ontology encoding. If not used, all ontology items are initialized directly from the embedding matrix. Otherwise, semantic encoding initialization is done using text descriptions, such as the intent播放音乐. Furthermore, it can be combined with the--use_valueparameter to enhance the encoding of semantic slots with additional sampled slot values.
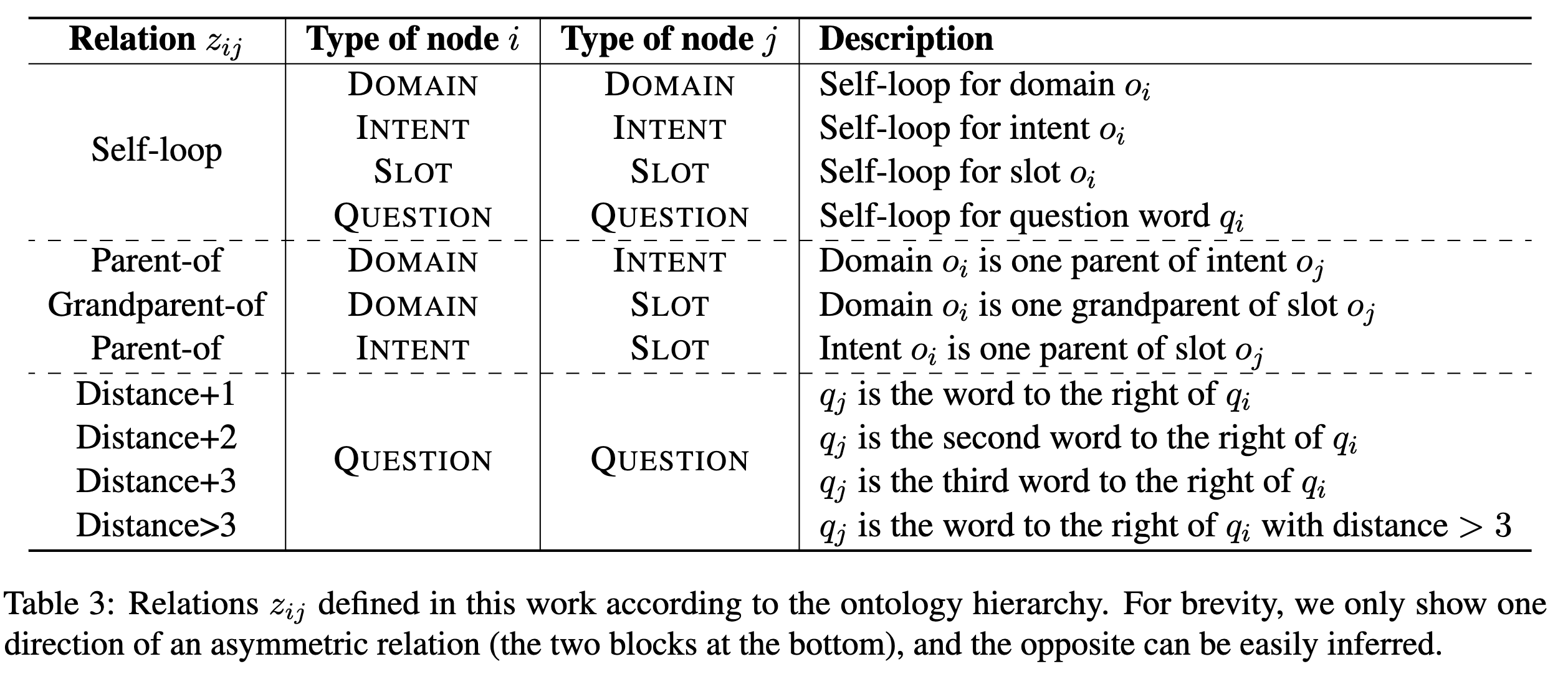
The relation in our proposed BIRGAT enocder is defined according to the hierarchy of ontology items, namely domain→intent→slot. We show the checklist of all relation types in the below table.
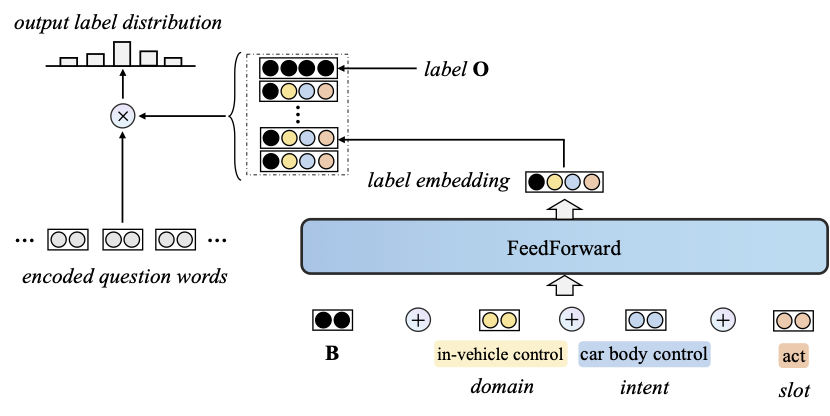
This part introduces the implementation details of baselines SL, SL+CLF and LLM+ICL.
Traditional sequence labeling tags each word in the utterance with label B-slot_name, I-slot_name or O. Slot value pairs can be easily extracted from the output labeling sequence. However, this strategy can not recover the hierarchical semantic tree on the proposed MIVS dataset. That is, it is unable to determine what the superior intent and domain are for each slot, since some common slots can be shared across different intents or domains. To deal with the complicated output structure, we extend the original label from B-slot_name to B-domain_name-intent_name-slot_name. For fair comparison, we also utilize the ontology encoding module to construct the features for each extended label. Given the encoded representation B- series label embedding I- series can be easily inferred) B, which is randomly initialized. Note that the construction of the extended labels should obey the hierarchy of ontology items. In other words, the intent O, we initialize it with a random trainable vector of the same dimension as
Traditional SL method fails to tackle the unaligned slot value problem. To compensate for this deficiency, we extract a set of frequently occurred quadruples (domain, intent, slot, value) from the training set. These quadruples are treated as a reserved label memory. Apart from the sequence labeling task, we also conduct a multi-label classification for each entry in the reserved label memory. If the prediction for a specific entry is ``1'', we also append this quadruple to the output list of the primary SL model.
Notice that, both SL and SL+CLF methods obtain a list of quadruples like (domain, intent, slot, value), which requires further post-processing to recover the hierarchical tree structure. We follow the left-to-right order in the original utterance during reconstruction. If a slot-value contradiction exists, we will resolve it by creating a new intent sub-tree. For example, when encountering the quadruple (in-vehicle control, car body control, act, close), since the path in-vehicle control -> car body control ->act already exists but with different value turn on, we will create a new intent node which also denotes car body control as the parent of the slot-value pair act=close.
The below table reports the successful conversion rate for each method on datasets MIVS and TOPv2, assuming that the golden annotation are available. According to the percentages, we can find: 1) traditional SL-based methods both fail to successfully recover the entire dataset~(
| Method | SL | SL+CLF | Ours |
|---|---|---|---|
| TOPv2 | 75.3 | 84.3 | 99.6 |
| MIVS | 48.1 | 80.6 | 100.0 |
It is a baseline in zero- and few-shot transfer learning settings. We adopt the advanced text-davinci-003 as the backbone to fulfill the text completion task. The temperature is set to
The prompt consists of three parts apart from the test utterance: 1) A specification of all ontology items which will be used in both the demonstration exemplars and the test case. 2) A brief task description. 3) Demonstration exemplars that characterize the input-output format. We randomly sample

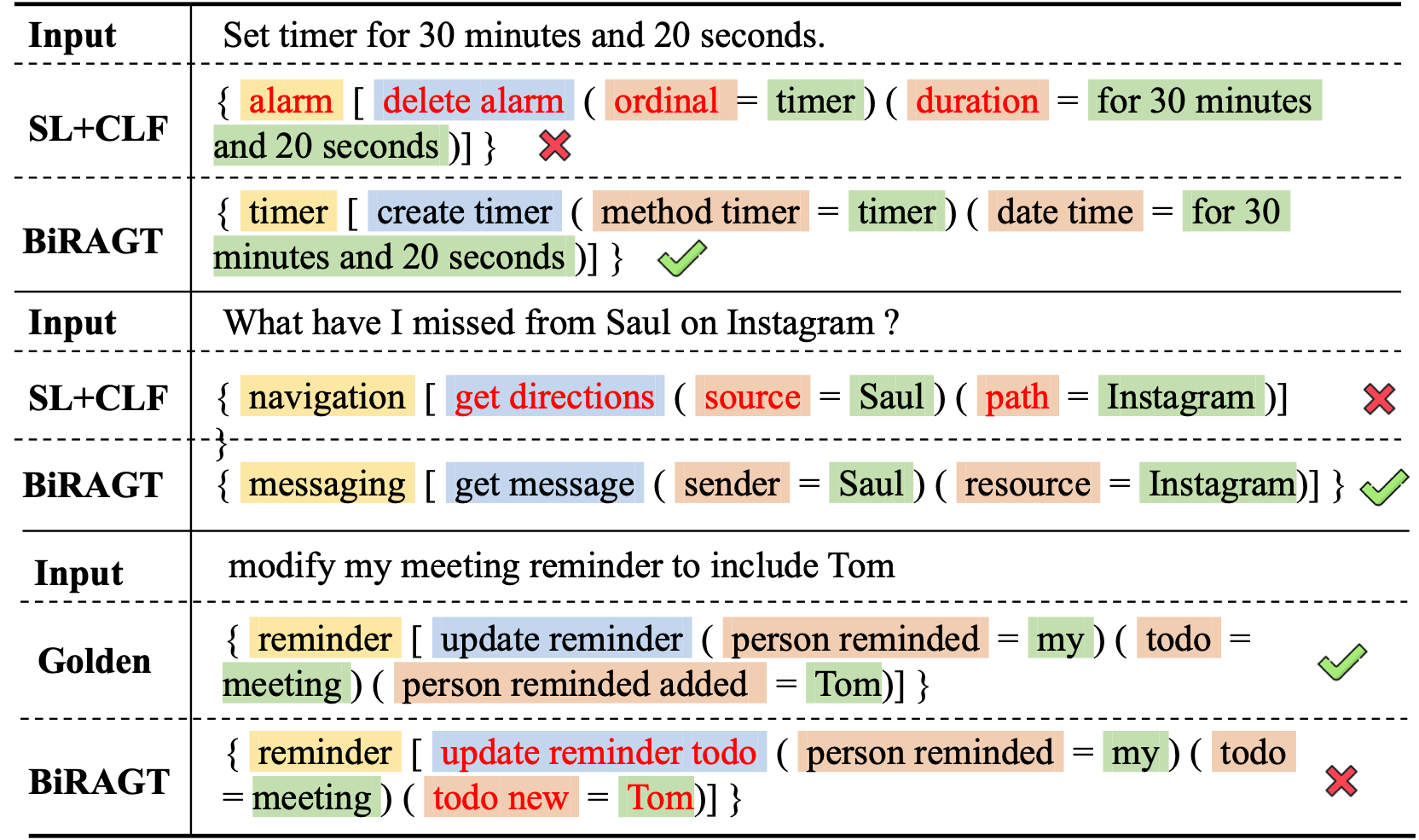
We present several cases from TOPv2 dataset for case study. The first two cases show the effectiveness of our proposed BiRGAT method. We observe that through the encoding of hierarchical ontology our model give more precise prediction especially on domains and intents detection while the baseline always made mistake. However, the third case indicates that our model will also made mistake on those intents with high semantic similarity.