The source code for our paper
"Self-Supervised Temporal-Discriminative Representation Learning for Video Action Recognition" paper
Without one label available, our method learn to focus on motion region powerful!

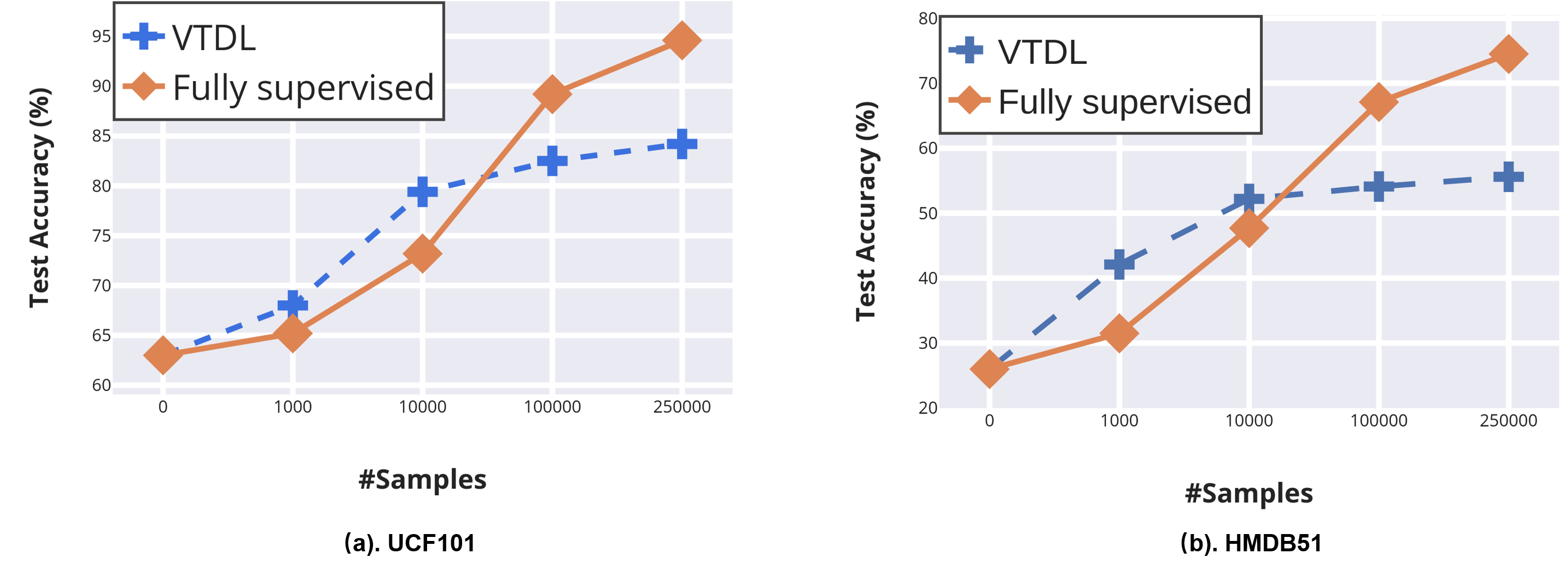
Our self-supervised VTDL signifcantly outperforms existing self-supervised learning method in video action recognition, even achieve better result than fully-supervised methods on UCF101 and HMDB51 when a small-scale video dataset (with only thousands of videos) is used for pre-training!
- Python3
- pytorch1.1+
- PIL
- datasets
- list
- hmdb51: the train/val lists of HMDB51
- ucf101: the train/val lists of UCF101
- kinetics-400: the train/val lists of kinetics-400
- list
- experiments
- logs: experiments record in detials
- TemporalDis
- hmdb51
- ucf101
- kinetics
- gradientes:
- visualization
- src
- data: load data
- loss: the loss evluate in this paper
- model: network architectures
- scripts: train/eval scripts
- TC: detail implementation of Spatio-temporal consistency
- utils
- feature_extract.py
- main.py
- trainer.py
- option.py
Look dataset.md. Prepare dataset in txt file, and each row of txt is as below: The split of hmdb51/ucf101/kinetics-400 can be download from google driver.
Each item include
video_path class frames_num
The network is in the folder src/model/[backbone].py
| Method | #logits_channel |
|---|---|
| C3D | 512 |
| R2P1D | 2048 |
| I3D | 1024 |
| R3D | 2048 |
bash scripts/TemporalDisc/hmdb51.shbash scripts/TemporalDisc/ucf101.shbash scripts/TemporalDisc/kinetics.shNotice: More Training Options and ablation study Can be find in scripts
#!/usr/bin/env bash
python main.py \
--method ft \
--train_list ../datasets/lists/hmdb51/hmdb51_rgb_train_split_1.txt \
--val_list ../datasets/lists/hmdb51/hmdb51_rgb_val_split_1.txt \
--dataset hmdb51 \
--arch i3d \
--mode rgb \
--lr 0.001 \
--lr_steps 10 20 25 30 35 40 \
--epochs 45 \
--batch_size 4 \
--data_length 64 \
--workers 8 \
--dropout 0.5 \
--gpus 2 \
--logs_path ../experiments/logs/hmdb51_i3d_ft \
--print-freq 100 \
--weights ../experiments/TemporalDis/hmdb51/models/04-16-2328_aug_CJ/ckpt_epoch_48.pth#!/usr/bin/env bash
python main.py \
--method ft \
--train_list ../datasets/lists/ucf101/ucf101_rgb_train_split_1.txt \
--val_list ../datasets/lists/ucf101/ucf101_rgb_val_split_1.txt \
--dataset ucf101 \
--arch i3d \
--mode rgb \
--lr 0.0005 \
--lr_steps 10 20 25 30 35 40 \
--epochs 45 \
--batch_size 4 \
--data_length 64 \
--workers 8 \
--dropout 0.5 \
--gpus 2 \
--logs_path ../experiments/logs/ucf101_i3d_ft \
--print-freq 100 \
--weights ../experiments/TemporalDis/ucf101/models/04-18-2208_aug_CJ/ckpt_epoch_45.pthNotice: More Training Options and ablation study Can be find in scripts
With same experiment setting, the result is reported below:
| Method | UCF101 | HMDB51 |
|---|---|---|
| Baseline | 60.3 | 22.6 |
| + BA | 63.3 | 26.2 |
| + Temporal Discriminative | 72.7 | 41.2 |
| + TCA | 82.3 | 52.9 |
We provided trained models/logs/performance in google driver.
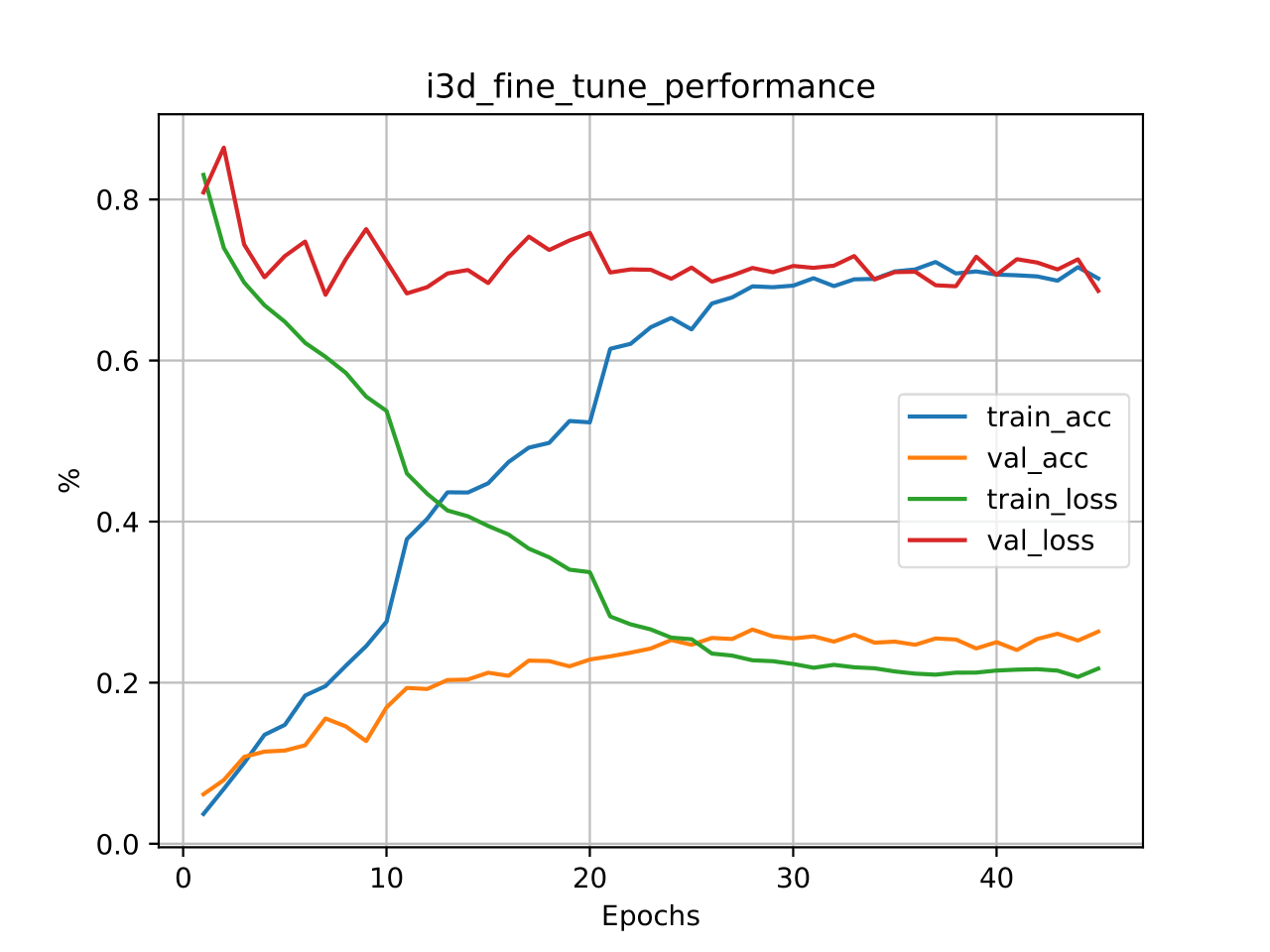
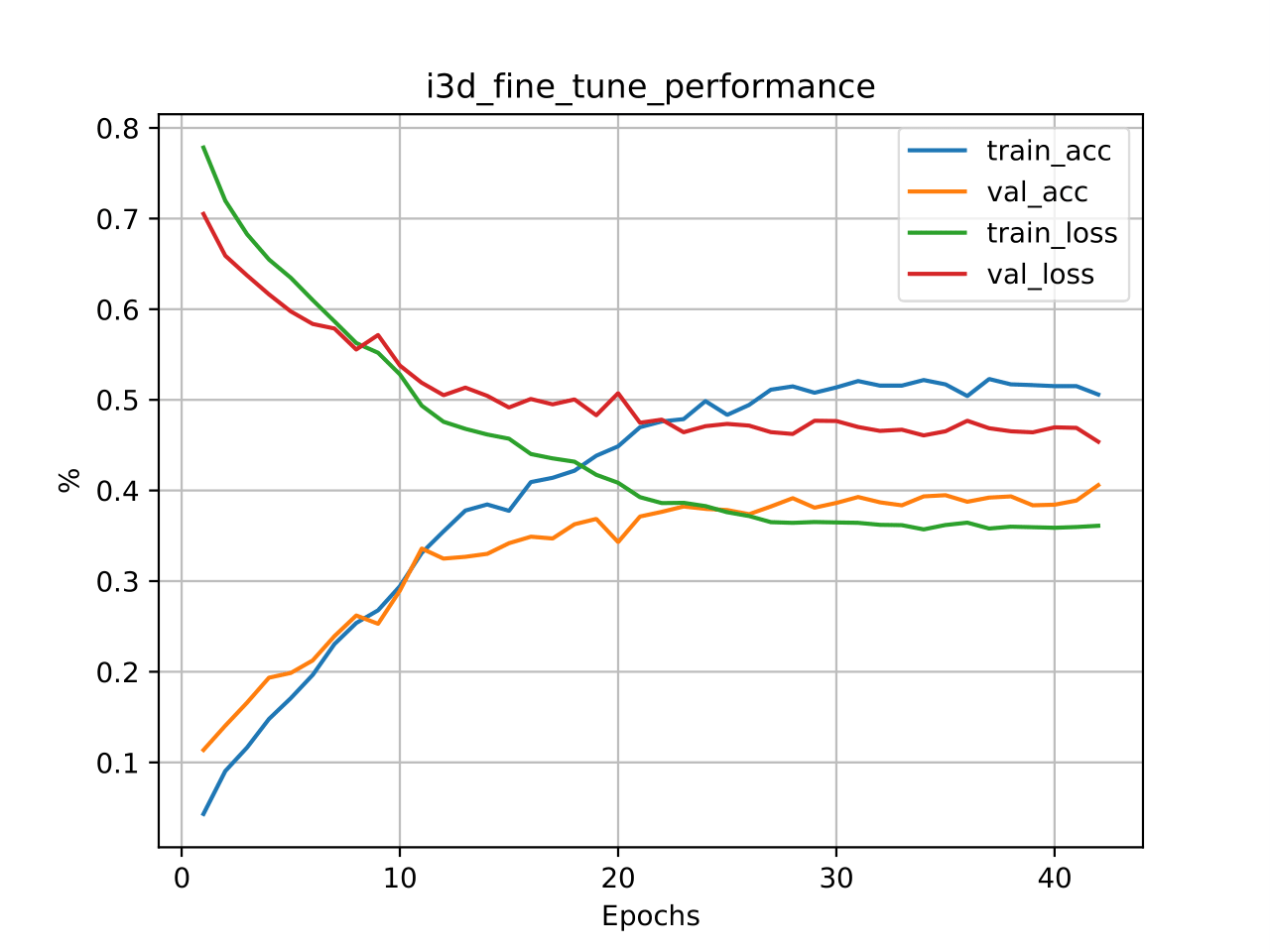
(a). Pretrain
Loss curve:
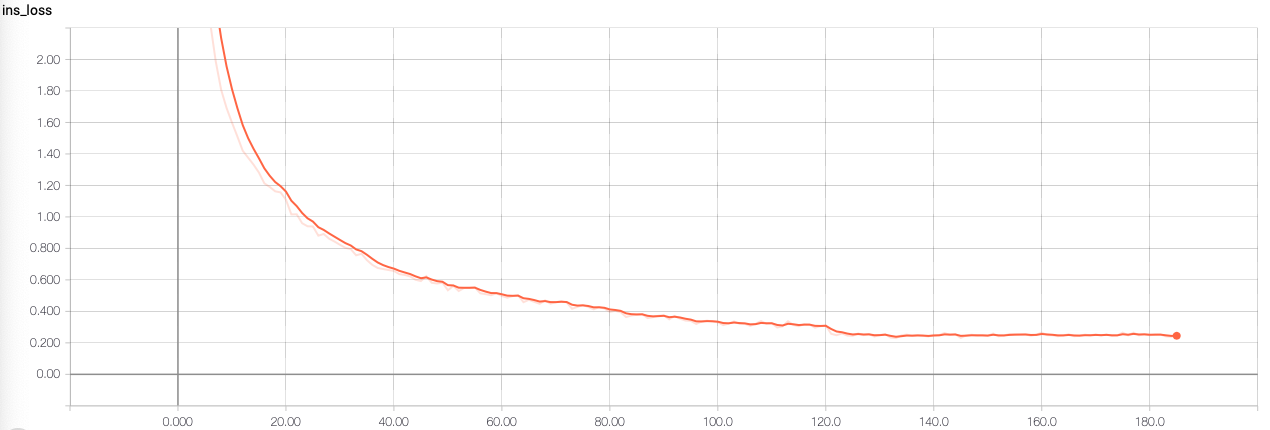
Ins Prob:
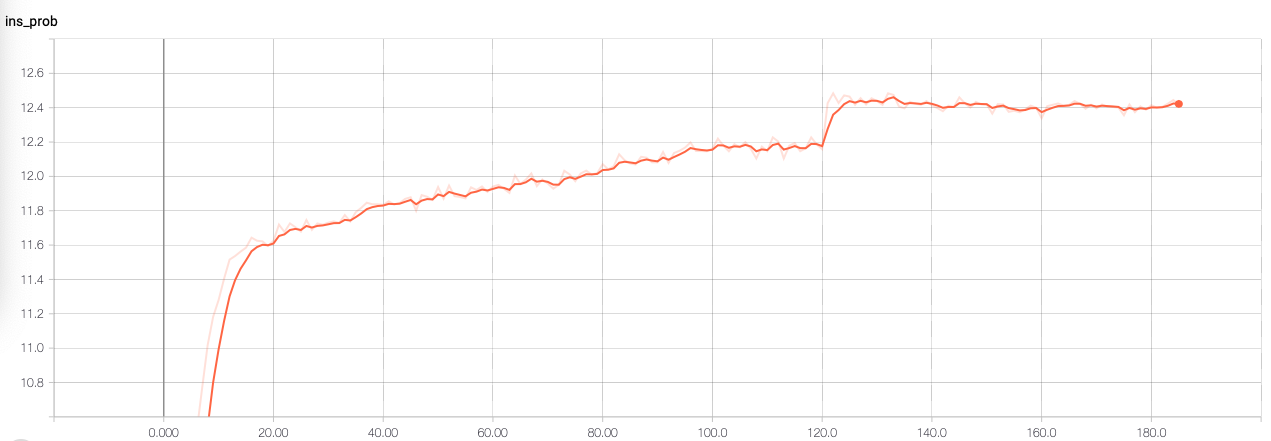
This pretrained model can achieve 52.7% on HMDB51.
(b). Finetune
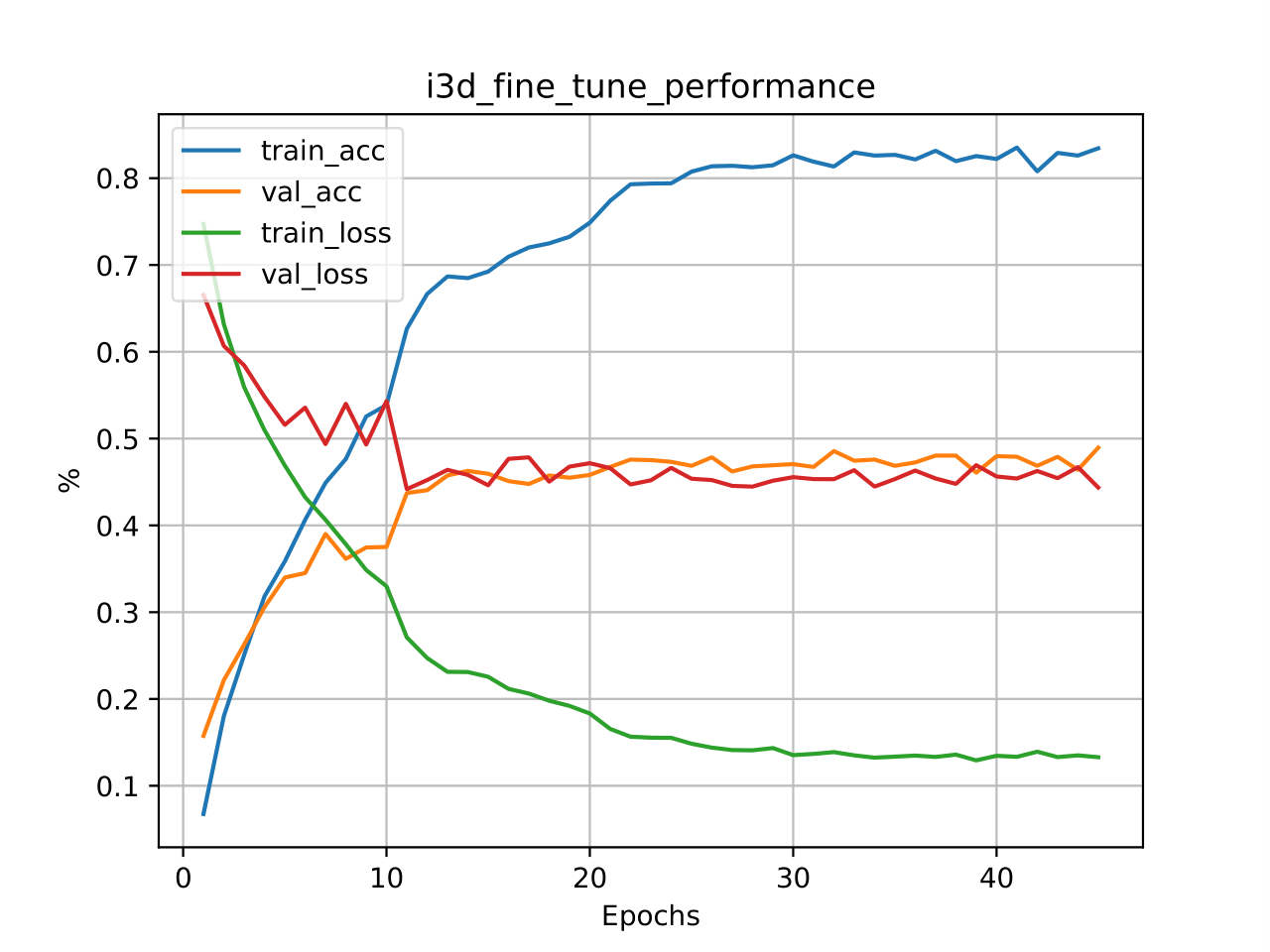
The result is report with single video clip. In the test, we will average ten clips as final predictions. Will lead to around 2-3% improvement.
python test.pyAs STCR can be easily extend to other video representation task, we offer the scripts to perform feature extract.
python feature_extractor.pyThe feature will be saved as a single numpy file in the format [video_nums,features_dim]
Please cite our paper if you find this code useful for your research.
@Article{wang2020self,
author = {Jinpeng Wang and Yiqi Lin and Andy J. Ma and Pong C. Yuen},
title = {Self-supervised Temporal Discriminative Learning for Video Representation Learning},
journal = {arXiv preprint arXiv:2008.02129},
year = {2020},
}
The project is partly based on Unsupervised Embedding Learning and MOCO.