SubprocVecEnv speedup does not scale linearly compared with DummyVecEnv
#608
Comments
|
I think the most important factor for speedup is ratio of compute time (simulator step time) to the communication time (time it takes to send observations and actions through the pipes); the larger this ratio - the better speedup one can achieve. |
|
Similar discussion here: #600 |
|
@pzhokhov Thanks a lot for your detailed explanation, on my local server, it seems another potential factor is many simulators are quite fast enough e.g. classic control environments CartPole, Pendulum, the By the way, I have a very dump question, is there a reason why in VecEnv the parallelization is done by Python multiprocessing package and in some algorithms like TRPO, PPO1, HER they use MPI instead ? To my understanding, MPI can be used for distributed systems (multiple computing nodes) but Multiprocessing and MPI considered to be lower level so might be potentially faster than the latter ? |
|
@pzhokhov Given the case that some simulators And since different environments might have different complexity on |
|
@pzhokhov Also if it could be beneficial for further speedup by using asyncio (Python 3.7+) for I/O concurrency combined with multiprocessing ? |
|
chunks of sub-environments per process instead of one per process is a great idea! I'd be very interested to see the results of that (how much faster does venv.step() method become with different types of sub-environments. asyncio - also a good one, although I'd rather keep things compatible with python 3.6 and below. Anyways, if you feel like implementing any of these - do not let me stop you from submitting a PR :) |
|
@pzhokhov Thanks a lot for your detailed comments. For the chunk-based parallel VecEnv, I quickly made an implementation and a benchmark on my laptop (4-cores) on CartPole-v1, showing as attached image
For this preliminary benchmark results, it seems the 'chunk' idea works quite reasonably, tomorrow I'll try out on the server (DGX-1) for more number of environment and different environment types. |


|
There is an additional benchmark on some Mujoco environments (tested on DGX-1)
|










|
Here is the benchmark code Firstly, one should copy and paste the code from #620 to single file named from functools import partial
import gym
from time import time
import numpy as np
env_id = 'Ant-v2'
def make_env(seed):
env = gym.make(env_id)
env.seed(seed)
return env
list_ori_time = []
list_chunk_time1 = []
list_chunk_time2 = []
list_chunk_time4 = []
list_chunk_time6 = []
list_chunk_time8 = []
num_envs = [8, 20, 32, 45, 64, 80, 100, 128]
for n in num_envs:
make_fns = [partial(make_env, seed=i) for i in range(n)]
list_ori_time.append(get_ori_time(make_fns))
list_chunk_time1.append(get_chunk_time(make_fns, 1))
list_chunk_time2.append(get_chunk_time(make_fns, 2))
list_chunk_time4.append(get_chunk_time(make_fns, 4))
list_chunk_time6.append(get_chunk_time(make_fns, 6))
list_chunk_time8.append(get_chunk_time(make_fns, 8))from chunk_version import SubprocChunkVecEnv
from original_version import SubprocVecEnv
def get_chunk_time(make_fns, size=1):
chunk_times = []
for _ in range(10):
t = time()
env = SubprocChunkVecEnv(make_fns, size)
env.reset()
env.step([env.action_space.sample()]*len(make_fns))
chunk_times.append(time() - t)
env.close()
del env
return np.mean(chunk_times)
def get_ori_time(make_fns):
ori_times = []
for _ in range(10):
t = time()
env = SubprocVecEnv(make_fns)
env.reset()
env.step([env.action_space.sample()]*len(make_fns))
ori_times.append(time() - t)
env.close()
del env
return np.mean(ori_times)Plotting the benchmark import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
plt.plot(num_envs, list_ori_time, label='SubprocVecEnv')
plt.plot(num_envs, list_chunk_time1, label='Chunk-1')
plt.plot(num_envs, list_chunk_time2, label='Chunk-2')
plt.plot(num_envs, list_chunk_time4, label='Chunk-4')
plt.plot(num_envs, list_chunk_time6, label='Chunk-6')
plt.plot(num_envs, list_chunk_time8, label='Chunk-8')
plt.legend(loc='upper left')
plt.xlabel('Number of sub-environments')
plt.ylabel('Mean (30) time duration for single `step`')
plt.title(f'Benchmark of chunk-based VecEnv in {env_id}')
plt.xticks(num_envs)
plt.show() |
|
Thanks for the thorough investigation, @zuoxingdong! Looks like the mujoco envs behave very similarly to each other. Could you also benchmark it on one or two atari envs (since that's where we mostly use SubprocVecEnv presently)? We can then include the plots in the docs - something like step() time as a function of number of subenvs for cartpole, for mujoco ant, and for some atari game. If you have extra time, it would be interesting to put DummyVecEnv and ShmemVecEnv on the same plots :) Also, let's merge the PR |
|
Here is the benchmark in two Atari games |


|
@pzhokhov Here are some benchmark adding
|

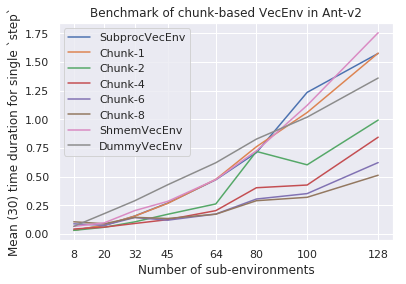

|
@pzhokhov I did some experiment, it seems batched environment for Mujoco does not work well as single one, just wondering if there might be some grounding reasons why Atari games can benefits from batched data but Mujoco. |
|
In |


… tree (openai#608) * Parallelized sampling from the replay buffer and building the segment tree.
I made some toy benchmark by creating 16 environments for both
SubprocVecEnvandDummyVecEnv. And collect 1000 time steps by firstly reset the environment and feed random action sampled from action space within a for loop.It turns out the speed of the simulator step is quite crucial for total speedup. For example,
HalfCheetah-v2is roughly 1.5-2x faster and 'FetchPush-v1' could be 7-9x faster. I guess it depends on the dynamics where cheetah is simpler.For classic control environments like
CartPole-v1, it seems usingDummyVecEnvis much better, since the speedup is ~0.2x, i.e. 5x slower thanDummyVecEnv.I am considering that if it is feasible to scale up the speedup further to be approximately linear with the number of environments ? Or the main reason is coming from computing overhead in the
Process?The text was updated successfully, but these errors were encountered: