History News:
> +- [2024-08-09] We propose Img-Diff, which enhances the performance of multimodal large language models through *contrastive data synthesis*, achieving a score that is 12 points higher than GPT-4V on the [MMVP benchmark](https://tsb0601.github.io/mmvp_blog/). See more details in our [paper](https://arxiv.org/abs/2408.04594), and download the dataset from [huggingface](https://huggingface.co/datasets/datajuicer/Img-Diff) and [modelscope](https://modelscope.cn/datasets/Data-Juicer/Img-Diff). +- [2024-07-24] "Tianchi Better Synth Data Synthesis Competition for Multimodal Large Models" — Our 4th data-centric LLM competition has kicked off! Please visit the competition's [official website](https://tianchi.aliyun.com/competition/entrance/532251) for more information. +- [2024-07-17] We utilized the Data-Juicer [Sandbox Laboratory Suite](https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox.md) to systematically optimize data and models through a co-development workflow between data and models, achieving a new top spot on the [VBench](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard) text-to-video leaderboard. The related achievements have been compiled and published in a [paper](http://arxiv.org/abs/2407.11784), and the model has been released on the [ModelScope](https://modelscope.cn/models/Data-Juicer/Data-Juicer-T2V) and [HuggingFace](https://huggingface.co/datajuicer/Data-Juicer-T2V) platforms. +- [2024-07-12] Our *awesome list of MLLM-Data* has evolved into a systemic [survey](https://arxiv.org/abs/2407.08583) from model-data co-development perspective. Welcome to [explore](docs/awesome_llm_data.md) and contribute! +- [2024-06-01] ModelScope-Sora "Data Directors" creative sprint—Our third data-centric LLM competition has kicked off! Please visit the competition's [official website](https://tianchi.aliyun.com/competition/entrance/532219) for more information. - [2024-03-07] We release **Data-Juicer [v0.2.0](https://github.com/alibaba/data-juicer/releases/tag/v0.2.0)** now! In this new version, we support more features for **multimodal data (including video now)**, and introduce **[DJ-SORA](docs/DJ_SORA.md)** to provide open large-scale, high-quality datasets for SORA-like models. - [2024-02-20] We have actively maintained an *awesome list of LLM-Data*, welcome to [visit](docs/awesome_llm_data.md) and contribute! @@ -67,83 +70,87 @@ Besides, our paper is also updated to [v3](https://arxiv.org/abs/2309.02033). Table of Contents ================= -- [Data-Juicer: A One-Stop Data Processing System for Large Language Models](#data-juicer--a-one-stop-data-processing-system-for-large-language-models) - - [News](#news) -- [Table of Contents](#table-of-contents) - - [Features](#features) - - [Documentation Index ](#documentation-index-) - - [Demos](#demos) +- [News](#news) +- [Why Data-Juicer?](#why-data-juicer) +- [DJ-Cookbook](#dj-cookbook) + - [Curated Resources](#curated-resources) + - [Coding with Data-Juicer (DJ)](#coding-with-data-juicer-dj) + - [Use Cases \& Data Recipes](#use-cases--data-recipes) + - [Interactive Examples](#interactive-examples) +- [Installation](#installation) - [Prerequisites](#prerequisites) - - [Installation](#installation) - - [From Source](#from-source) - - [Using pip](#using-pip) - - [Using Docker](#using-docker) - - [Installation check](#installation-check) - - [Quick Start](#quick-start) - - [Data Processing](#data-processing) - - [Distributed Data Processing](#distributed-data-processing) - - [Data Analysis](#data-analysis) - - [Data Visualization](#data-visualization) - - [Build Up Config Files](#build-up-config-files) - - [Sandbox](#sandbox) - - [Preprocess Raw Data (Optional)](#preprocess-raw-data-optional) - - [For Docker Users](#for-docker-users) - - [Data Recipes](#data-recipes) - - [License](#license) - - [Contributing](#contributing) - - [Acknowledgement](#acknowledgement) - - [References](#references) - - -## Features - - + - [From Source](#from-source) + - [Using pip](#using-pip) + - [Using Docker](#using-docker) + - [Installation check](#installation-check) + - [For Video-related Operators](#for-video-related-operators) +- [Quick Start](#quick-start) + - [Data Processing](#data-processing) + - [Distributed Data Processing](#distributed-data-processing) + - [Data Analysis](#data-analysis) + - [Data Visualization](#data-visualization) + - [Build Up Config Files](#build-up-config-files) + - [Sandbox](#sandbox) + - [Preprocess Raw Data (Optional)](#preprocess-raw-data-optional) + - [For Docker Users](#for-docker-users) +- [License](#license) +- [Contributing](#contributing) +- [Acknowledgement](#acknowledgement) +- [References](#references) + + +## Why Data-Juicer? + + - **Systematic & Reusable**: - Empowering users with a systematic library of 80+ core [OPs](docs/Operators.md), 20+ reusable [config recipes](configs), and 20+ feature-rich - dedicated [toolkits](#documentation), designed to - function independently of specific multimodal LLM datasets and processing pipelines. - -- **Data-in-the-loop & Sandbox**: Supporting one-stop data-model collaborative development, enabling rapid iteration - through the [sandbox laboratory](docs/Sandbox.md), and providing features such as feedback loops based on data and model, - visualization, and multidimensional automatic evaluation, so that you can better understand and improve your data and models. -  - -- **Towards production environment**: Providing efficient and parallel data processing pipelines (Aliyun-PAI\Ray\Slurm\CUDA\OP Fusion) - requiring less memory and CPU usage, optimized with automatic fault-toleration. - 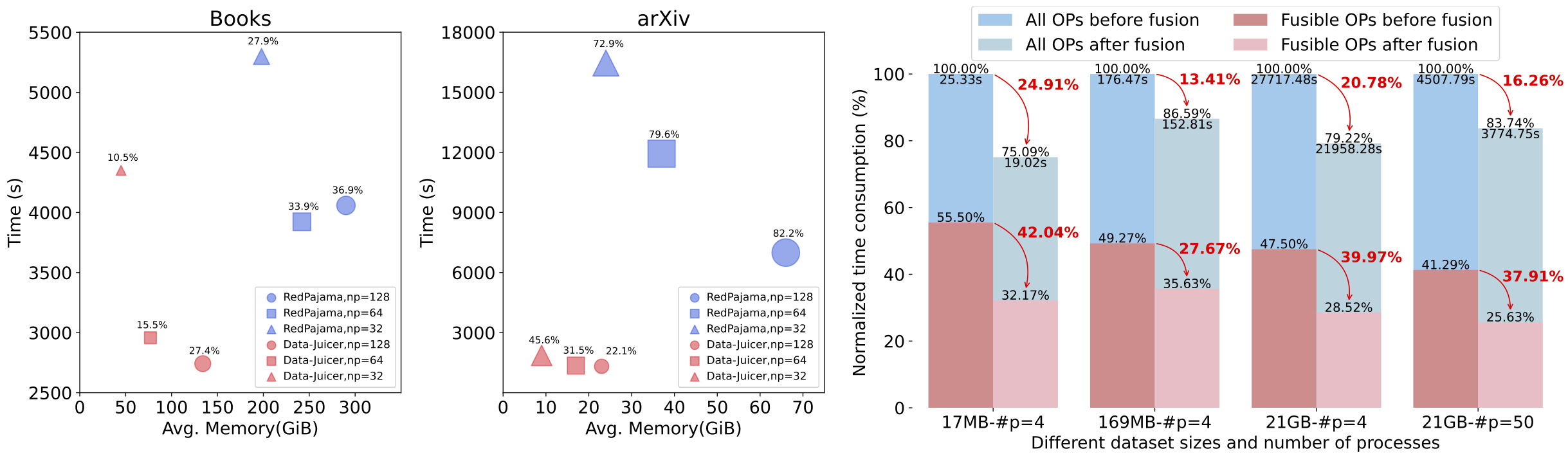 + Empowering users with a systematic library of 100+ core [OPs](docs/Operators.md), and 50+ reusable config recipes and + dedicated toolkits, designed to + function independently of specific multimodal LLM datasets and processing pipelines. Supporting data analysis, cleaning, and synthesis in pre-training, post-tuning, en, zh, and more scenarios. -- **Comprehensive Data Processing Recipes**: Offering tens of [pre-built data - processing recipes](configs/data_juicer_recipes/README.md) for pre-training, fine-tuning, en, zh, and more scenarios. Validated on - reference LLaMA and LLaVA models. -  +- **User-Friendly & Extensible**: + Designed for simplicity and flexibility, with easy-start [guides](#quick-start), and [DJ-Cookbook](#dj-cookbook) containing fruitful demo usages. Feel free to [implement your own OPs](docs/DeveloperGuide.md#build-your-own-ops) for customizable data processing. -- **Flexible & Extensible**: Accommodating most types of data formats (e.g., jsonl, parquet, csv, ...) and allowing flexible combinations of OPs. Feel free to [implement your own OPs](docs/DeveloperGuide.md#build-your-own-ops) for customizable data processing. +- **Efficient & Robust**: Providing performance-optimized [parallel data processing](docs/Distributed.md) (Aliyun-PAI\Ray\CUDA\OP Fusion), + faster with less resource usage, verified in large-scale production environments. -- **User-Friendly Experience**: Designed for simplicity, with [comprehensive documentation](#documents), [easy start guides](#quick-start) and [demo configs](configs/README.md), and intuitive configuration with simple adding/removing OPs from [existing configs](configs/config_all.yaml). +- **Effect-Proven & Sandbox**: Supporting data-model co-development, enabling rapid iteration + through the [sandbox laboratory](docs/Sandbox.md), and providing features such as feedback loops and visualization, so that you can better understand and improve your data and models. Many effect-proven datasets and models have been derived from DJ, in scenarios such as pre-training, text-to-video and image-to-text generation. +  -## Documentation Index +## DJ-Cookbook +### Curated Resources +- [KDD-Tutorial](https://modelscope.github.io/data-juicer/_static/tutorial_kdd24.html) +- [Awesome LLM-Data](docs/awesome_llm_data.md) +- ["Bad" Data Exhibition](docs/BadDataExhibition.md) -- [Overview](README.md) +### Coding with Data-Juicer (DJ) +- [Overview of DJ](README.md) - [Operator Zoo](docs/Operators.md) -- [Configs](configs/README.md) +- [Quick Start](#quick-start) +- [Configuration](configs/README.md) - [Developer Guide](docs/DeveloperGuide.md) - [API references](https://modelscope.github.io/data-juicer/) -- [KDD-Tutorial](https://modelscope.github.io/data-juicer/_static/tutorial_kdd24.html) -- ["Bad" Data Exhibition](docs/BadDataExhibition.md) -- [Awesome LLM-Data](docs/awesome_llm_data.md) -- Dedicated Toolkits - - [Quality Classifier](tools/quality_classifier/README.md) - - [Auto Evaluation](tools/evaluator/README.md) - - [Preprocess](tools/preprocess/README.md) - - [Postprocess](tools/postprocess/README.md) +- [Preprocess Tools](tools/preprocess/README.md) +- [Postprocess Tools](tools/postprocess/README.md) +- [Format Conversion](tools/fmt_conversion/README.md) +- [Sandbox](docs/Sandbox.md) +- [Quality Classifier](tools/quality_classifier/README.md) +- [Auto Evaluation](tools/evaluator/README.md) +- [Third-parties Integration](thirdparty/LLM_ecosystems/README.md) + +### Use Cases & Data Recipes +- [Recipes for data process in BLOOM](configs/reproduced_bloom/README.md) +- [Recipes for data process in RedPajama](configs/reproduced_redpajama/README.md) +- [Refined recipes for pre-training text data](configs/data_juicer_recipes/README.md) +- [Refined recipes for fine-tuning text data](configs/data_juicer_recipes/README.md#before-and-after-refining-for-alpaca-cot-dataset) +- [Refined recipes for pre-training multi-modal data](configs/data_juicer_recipes/README.md#before-and-after-refining-for-multimodal-dataset) - [DJ-SORA](docs/DJ_SORA.md) -- [Third-parties (LLM Ecosystems)](thirdparty/README.md) -## Demos +### Interactive Examples - Introduction to Data-Juicer [[ModelScope](https://modelscope.cn/studios/Data-Juicer/overview_scan/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/overview_scan)] - Data Visualization: - Basic Statistics [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_visulization_statistics/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_visualization_statistics)] @@ -161,13 +168,13 @@ Table of Contents - Data Sampling and Mixture [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_mixture/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_mixture)] - Data Processing Loop [[ModelScope](https://modelscope.cn/studios/Data-Juicer/data_process_loop/summary)] [[HuggingFace](https://huggingface.co/spaces/datajuicer/data_process_loop)] -## Prerequisites +## Installation + +### Prerequisites - Recommend Python>=3.9,<=3.10 - gcc >= 5 (at least C++14 support) -## Installation - ### From Source - Run the following commands to install the latest basic `data_juicer` version in @@ -181,8 +188,8 @@ pip install -v -e . ```shell cd
- More related papers from Data-Juicer Team:
+
@@ -501,3 +501,4 @@ If you find our work useful for your research or development, please kindly cite
+
diff --git a/README_ZH.md b/README_ZH.md
index 27bcb72f2..9b1fa7f52 100644
--- a/README_ZH.md
+++ b/README_ZH.md
@@ -1,53 +1,58 @@
-[[English Page]](README.md) | [[文档索引]](#documents) | [[API]](https://modelscope.github.io/data-juicer) | [[DJ-SORA]](docs/DJ_SORA_ZH.md) | [[Awesome List]](docs/awesome_llm_data.md)
+[[英文主页]](README.md) | [[DJ-Cookbook]](#dj-cookbook) | [[算子池]](docs/Operators.md) | [[API]](https://modelscope.github.io/data-juicer) | [[Awesome LLM Data]](docs/awesome_llm_data.md)
-# Data-Juicer: 为大模型提供更高质量、更丰富、更易“消化”的数据
+# Data Processing for and with Foundation Models
- More related papers from Data-Juicer Team:
+ More related papers from the Data-Juicer Team:
>
+- [Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/data_juicer/DJ2.0_arXiv_preview.pdf)
+
- [Data-Juicer Sandbox: A Comprehensive Suite for Multimodal Data-Model Co-development](https://arxiv.org/abs/2407.11784)
- [The Synergy between Data and Multi-Modal Large Language Models: A Survey from Co-Development Perspective](https://arxiv.org/abs/2407.08583)
- [ImgDiff: Contrastive Data Synthesis for Vision Large Language Models](https://arxiv.org/abs/2408.04594)
+- [HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data](https://arxiv.org/abs/2412.17574)
+
- [Data Mixing Made Efficient: A Bivariate Scaling Law for Language Model Pretraining](https://arxiv.org/abs/2405.14908)
 +
+  

[](https://pypi.org/project/py-data-juicer)
[](https://hub.docker.com/r/datajuicer/data-juicer)
-[](docs/DeveloperGuide_ZH.md)
-[](docs/DeveloperGuide_ZH.md)
+[](#dj-cookbook)
+[](#dj-cookbook)
[](https://modelscope.cn/studios?name=Data-Jiucer&page=1&sort=latest&type=1)
[](https://huggingface.co/spaces?&search=datajuicer)
-[](README.md#documents)
-[](#documents)
-[](https://modelscope.github.io/data-juicer/)
-[](https://arxiv.org/abs/2309.02033)
+[](#dj-cookbook)
+[](README_ZH.md#dj-cookbook)
+[](docs/Operators.md)
+[-B31B1B?logo=arxiv&logoColor=red)](https://arxiv.org/abs/2309.02033)
+[](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/data_juicer/DJ2.0_arXiv_preview.pdf)
-Data-Juicer 是一个一站式**多模态**数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。
+Data-Juicer 是一个一站式系统,面向大模型的文本及多模态数据处理。我们提供了一个基于 JupyterLab 的 [Playground](http://8.138.149.181/),您可以从浏览器中在线试用 Data-Juicer。 如果Data-Juicer对您的研发有帮助,请支持加星(自动订阅我们的新发布)、以及引用我们的[工作](#参考文献) 。
-我们提供了一个基于 JupyterLab 的 [Playground](http://8.138.149.181/),您可以从浏览器中在线试用 Data-Juicer。 如果Data-Juicer对您的研发有帮助,请引用我们的[工作](#参考文献) 。
+[阿里云人工智能平台 PAI](https://www.aliyun.com/product/bigdata/learn) 已引用Data-Juicer并将其能力集成到PAI的数据处理产品中。PAI提供包含数据集管理、算力管理、模型工具链、模型开发、模型训练、模型部署、AI资产管理在内的功能模块,为用户提供高性能、高稳定、企业级的大模型工程化能力。数据处理的使用文档请参考:[PAI-大模型数据处理](https://help.aliyun.com/zh/pai/user-guide/components-related-to-data-processing-for-foundation-models/?spm=a2c4g.11186623.0.0.3e9821a69kWdvX)。
-[阿里云人工智能平台 PAI](https://www.aliyun.com/product/bigdata/learn) 已引用我们的工作,将Data-Juicer的能力集成到PAI的数据处理产品中。PAI提供包含数据集管理、算力管理、模型工具链、模型开发、模型训练、模型部署、AI资产管理在内的功能模块,为用户提供高性能、高稳定、企业级的大模型工程化能力。数据处理的使用文档请参考:[PAI-大模型数据处理](https://help.aliyun.com/zh/pai/user-guide/components-related-to-data-processing-for-foundation-models/?spm=a2c4g.11186623.0.0.3e9821a69kWdvX)。
-
-Data-Juicer正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们(issues/PRs/[Slack频道](https://join.slack.com/t/data-juicer/shared_invite/zt-23zxltg9d-Z4d3EJuhZbCLGwtnLWWUDg?spm=a2c22.12281976.0.0.7a8275bc8g7ypp) /[钉钉群](https://qr.dingtalk.com/action/joingroup?code=v1,k1,YFIXM2leDEk7gJP5aMC95AfYT+Oo/EP/ihnaIEhMyJM=&_dt_no_comment=1&origin=11)/...),一起推进LLM-数据的协同开发和研究!
+Data-Juicer正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们(issues/PRs/[Slack频道](https://join.slack.com/t/data-juicer/shared_invite/zt-23zxltg9d-Z4d3EJuhZbCLGwtnLWWUDg?spm=a2c22.12281976.0.0.7a8275bc8g7ypp) /[钉钉群](https://qr.dingtalk.com/action/joingroup?code=v1,k1,YFIXM2leDEk7gJP5aMC95AfYT+Oo/EP/ihnaIEhMyJM=&_dt_no_comment=1&origin=11)/...),一起推进大模型的数据-模型协同开发和研究应用!
----
## 新消息
+-  [2025-01-11] 我们发布了 2.0 版论文 [Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/data_juicer/DJ2.0_arXiv_preview.pdf)。DJ现在可以使用阿里云集群中 50 个 Ray 节点上的 6400 个 CPU 核心在 2.1 小时内处理 70B 数据样本,并使用 8 个 Ray 节点上的 1280 个 CPU 核心在 2.8 小时内对 5TB 数据进行重复数据删除。
+-  [2025-01-03] 我们通过 20 多个相关的新 [OP](https://github.com/modelscope/data-juicer/releases/tag/v1.0.2) 以及与 LLaMA-Factory 和 ModelScope-Swift 兼容的统一 [数据集格式](https://github.com/modelscope/data-juicer/releases/tag/v1.0.3) 更好地支持Post-Tuning场景。
+-  [2025-12-17] 我们提出了 *HumanVBench*,它包含 17 个以人为中心的任务,使用合成数据,从内在情感和外在表现的角度对视频 MLLM 的能力进行基准测试。请参阅我们的 [论文](https://arxiv.org/abs/2412.17574) 中的更多详细信息,并尝试使用它 [评估](https://github.com/modelscope/data-juicer/tree/HumanVBench) 您的模型。
+-  [2024-11-22] 我们发布 DJ [v1.0.0](https://github.com/modelscope/data-juicer/releases/tag/v1.0.0),其中我们重构了 Data-Juicer 的 *Operator*、*Dataset*、*Sandbox* 和许多其他模块以提高可用性,例如支持容错、FastAPI 和自适应资源管理。
+- [2024-08-25] 我们在 KDD'2024 中提供了有关多模态 LLM 数据处理的[教程](https://modelscope.github.io/data-juicer/_static/tutorial_kdd24.html)。
+
+


[](https://pypi.org/project/py-data-juicer)
[](https://hub.docker.com/r/datajuicer/data-juicer)
-[](docs/DeveloperGuide_ZH.md)
-[](docs/DeveloperGuide_ZH.md)
+[](#dj-cookbook)
+[](#dj-cookbook)
[](https://modelscope.cn/studios?name=Data-Jiucer&page=1&sort=latest&type=1)
[](https://huggingface.co/spaces?&search=datajuicer)
-[](README.md#documents)
-[](#documents)
-[](https://modelscope.github.io/data-juicer/)
-[](https://arxiv.org/abs/2309.02033)
+[](#dj-cookbook)
+[](README_ZH.md#dj-cookbook)
+[](docs/Operators.md)
+[-B31B1B?logo=arxiv&logoColor=red)](https://arxiv.org/abs/2309.02033)
+[](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/data_juicer/DJ2.0_arXiv_preview.pdf)
-Data-Juicer 是一个一站式**多模态**数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。
+Data-Juicer 是一个一站式系统,面向大模型的文本及多模态数据处理。我们提供了一个基于 JupyterLab 的 [Playground](http://8.138.149.181/),您可以从浏览器中在线试用 Data-Juicer。 如果Data-Juicer对您的研发有帮助,请支持加星(自动订阅我们的新发布)、以及引用我们的[工作](#参考文献) 。
-我们提供了一个基于 JupyterLab 的 [Playground](http://8.138.149.181/),您可以从浏览器中在线试用 Data-Juicer。 如果Data-Juicer对您的研发有帮助,请引用我们的[工作](#参考文献) 。
+[阿里云人工智能平台 PAI](https://www.aliyun.com/product/bigdata/learn) 已引用Data-Juicer并将其能力集成到PAI的数据处理产品中。PAI提供包含数据集管理、算力管理、模型工具链、模型开发、模型训练、模型部署、AI资产管理在内的功能模块,为用户提供高性能、高稳定、企业级的大模型工程化能力。数据处理的使用文档请参考:[PAI-大模型数据处理](https://help.aliyun.com/zh/pai/user-guide/components-related-to-data-processing-for-foundation-models/?spm=a2c4g.11186623.0.0.3e9821a69kWdvX)。
-[阿里云人工智能平台 PAI](https://www.aliyun.com/product/bigdata/learn) 已引用我们的工作,将Data-Juicer的能力集成到PAI的数据处理产品中。PAI提供包含数据集管理、算力管理、模型工具链、模型开发、模型训练、模型部署、AI资产管理在内的功能模块,为用户提供高性能、高稳定、企业级的大模型工程化能力。数据处理的使用文档请参考:[PAI-大模型数据处理](https://help.aliyun.com/zh/pai/user-guide/components-related-to-data-processing-for-foundation-models/?spm=a2c4g.11186623.0.0.3e9821a69kWdvX)。
-
-Data-Juicer正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们(issues/PRs/[Slack频道](https://join.slack.com/t/data-juicer/shared_invite/zt-23zxltg9d-Z4d3EJuhZbCLGwtnLWWUDg?spm=a2c22.12281976.0.0.7a8275bc8g7ypp) /[钉钉群](https://qr.dingtalk.com/action/joingroup?code=v1,k1,YFIXM2leDEk7gJP5aMC95AfYT+Oo/EP/ihnaIEhMyJM=&_dt_no_comment=1&origin=11)/...),一起推进LLM-数据的协同开发和研究!
+Data-Juicer正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们(issues/PRs/[Slack频道](https://join.slack.com/t/data-juicer/shared_invite/zt-23zxltg9d-Z4d3EJuhZbCLGwtnLWWUDg?spm=a2c22.12281976.0.0.7a8275bc8g7ypp) /[钉钉群](https://qr.dingtalk.com/action/joingroup?code=v1,k1,YFIXM2leDEk7gJP5aMC95AfYT+Oo/EP/ihnaIEhMyJM=&_dt_no_comment=1&origin=11)/...),一起推进大模型的数据-模型协同开发和研究应用!
----
## 新消息
+-  [2025-01-11] 我们发布了 2.0 版论文 [Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/data_juicer/DJ2.0_arXiv_preview.pdf)。DJ现在可以使用阿里云集群中 50 个 Ray 节点上的 6400 个 CPU 核心在 2.1 小时内处理 70B 数据样本,并使用 8 个 Ray 节点上的 1280 个 CPU 核心在 2.8 小时内对 5TB 数据进行重复数据删除。
+-  [2025-01-03] 我们通过 20 多个相关的新 [OP](https://github.com/modelscope/data-juicer/releases/tag/v1.0.2) 以及与 LLaMA-Factory 和 ModelScope-Swift 兼容的统一 [数据集格式](https://github.com/modelscope/data-juicer/releases/tag/v1.0.3) 更好地支持Post-Tuning场景。
+-  [2025-12-17] 我们提出了 *HumanVBench*,它包含 17 个以人为中心的任务,使用合成数据,从内在情感和外在表现的角度对视频 MLLM 的能力进行基准测试。请参阅我们的 [论文](https://arxiv.org/abs/2412.17574) 中的更多详细信息,并尝试使用它 [评估](https://github.com/modelscope/data-juicer/tree/HumanVBench) 您的模型。
+-  [2024-11-22] 我们发布 DJ [v1.0.0](https://github.com/modelscope/data-juicer/releases/tag/v1.0.0),其中我们重构了 Data-Juicer 的 *Operator*、*Dataset*、*Sandbox* 和许多其他模块以提高可用性,例如支持容错、FastAPI 和自适应资源管理。
+- [2024-08-25] 我们在 KDD'2024 中提供了有关多模态 LLM 数据处理的[教程](https://modelscope.github.io/data-juicer/_static/tutorial_kdd24.html)。
+
+
+Warnings : {warning_count}\n' \
+ f'Errors : {total_error_count}\n'
+ error_items = list(error_dict.items())
+ error_items.sort(key=lambda it: it[1], reverse=True)
+ error_items = error_items[:max_show_item]
+ # convert error items to a table
+ if len(error_items) > 0:
+ error_table = []
+ table_header = [
+ 'OP/Method', 'Error Type', 'Error Message', 'Error Count'
+ ]
+ for key, num in error_items:
+ op_name, error_type, error_msg = key
+ error_table.append([op_name, error_type, error_msg, num])
+ table = tabulate(error_table, table_header, tablefmt='fancy_grid')
+ summary += table
+ summary += f'\nError/Warning details can be found in the log file ' \
+ f'[{log_file}] and its related log files.'
+ logger.opt(ansi=True).info(summary)
+
+
class HiddenPrints:
"""Define a range that hide the outputs within this range."""
diff --git a/data_juicer/utils/model_utils.py b/data_juicer/utils/model_utils.py
index 6e32434fa..dd99032e3 100644
--- a/data_juicer/utils/model_utils.py
+++ b/data_juicer/utils/model_utils.py
@@ -79,7 +79,7 @@ def check_model(model_name, force=False):
download again forcefully.
"""
# check for local model
- if os.path.exists(model_name):
+ if not force and os.path.exists(model_name):
return model_name
if not os.path.exists(DJMC):
@@ -744,12 +744,65 @@ def prepare_vllm_model(pretrained_model_name_or_path, **model_params):
if model_params.get('device', '').startswith('cuda:'):
model_params['device'] = 'cuda'
- model = vllm.LLM(model=pretrained_model_name_or_path, **model_params)
+ model = vllm.LLM(model=pretrained_model_name_or_path,
+ generation_config='auto',
+ **model_params)
tokenizer = model.get_tokenizer()
return (model, tokenizer)
+def update_sampling_params(sampling_params,
+ pretrained_model_name_or_path,
+ enable_vllm=False):
+ if enable_vllm:
+ update_keys = {'max_tokens'}
+ else:
+ update_keys = {'max_new_tokens'}
+ generation_config_keys = {
+ 'max_tokens': ['max_tokens', 'max_new_tokens'],
+ 'max_new_tokens': ['max_tokens', 'max_new_tokens'],
+ }
+ generation_config_thresholds = {
+ 'max_tokens': (max, 512),
+ 'max_new_tokens': (max, 512),
+ }
+
+ # try to get the generation configs
+ from transformers import GenerationConfig
+ try:
+ model_generation_config = GenerationConfig.from_pretrained(
+ pretrained_model_name_or_path).to_dict()
+ except: # noqa: E722
+ logger.warning(f'No generation config found for the model '
+ f'[{pretrained_model_name_or_path}]')
+ model_generation_config = {}
+
+ for key in update_keys:
+ # if there is this param in the sampling_prams, compare it with the
+ # thresholds and apply the specified updating function
+ if key in sampling_params:
+ logger.debug(f'Found param {key} in the input `sampling_params`.')
+ continue
+ # if not, try to find it in the generation_config of the model
+ found = False
+ for config_key in generation_config_keys[key]:
+ if config_key in model_generation_config \
+ and model_generation_config[config_key]:
+ sampling_params[key] = model_generation_config[config_key]
+ found = True
+ break
+ if found:
+ logger.debug(f'Found param {key} in the generation config as '
+ f'{sampling_params[key]}.')
+ continue
+ # if not again, use the threshold directly
+ _, th = generation_config_thresholds[key]
+ sampling_params[key] = th
+ logger.debug(f'Use the threshold {th} as the sampling param {key}.')
+ return sampling_params
+
+
MODEL_FUNCTION_MAPPING = {
'api': prepare_api_model,
'diffusion': prepare_diffusion_model,
diff --git a/demos/process_on_ray/configs/dedup.yaml b/demos/process_on_ray/configs/dedup.yaml
new file mode 100644
index 000000000..642203249
--- /dev/null
+++ b/demos/process_on_ray/configs/dedup.yaml
@@ -0,0 +1,15 @@
+# Process config example for dataset
+
+# global parameters
+project_name: 'demo-dedup'
+dataset_path: './demos/process_on_ray/data/'
+export_path: './outputs/demo-dedup/demo-ray-bts-dedup-processed'
+
+executor_type: 'ray'
+ray_address: 'auto'
+
+# process schedule
+# a list of several process operators with their arguments
+process:
+ - ray_bts_minhash_deduplicator:
+ tokenization: 'character'
\ No newline at end of file
diff --git a/demos/process_on_ray/configs/demo.yaml b/demos/process_on_ray/configs/demo.yaml
index 1e3e4a55a..5154da014 100644
--- a/demos/process_on_ray/configs/demo.yaml
+++ b/demos/process_on_ray/configs/demo.yaml
@@ -2,11 +2,12 @@
# global parameters
project_name: 'ray-demo'
-executor_type: 'ray'
dataset_path: './demos/process_on_ray/data/demo-dataset.jsonl' # path to your dataset directory or file
-ray_address: 'auto' # change to your ray cluster address, e.g., ray://:
export_path: './outputs/demo/demo-processed'
+executor_type: 'ray'
+ray_address: 'auto' # change to your ray cluster address, e.g., ray://:
+
# process schedule
# a list of several process operators with their arguments
process:
diff --git a/demos/role_playing_system_prompt/README_ZH.md b/demos/role_playing_system_prompt/README_ZH.md
index 956c335bb..6c1e93bba 100644
--- a/demos/role_playing_system_prompt/README_ZH.md
+++ b/demos/role_playing_system_prompt/README_ZH.md
@@ -1,9 +1,11 @@
# 为LLM构造角色扮演的system prompt
-在该Demo中,我们展示了如何通过Data-Juicer的菜谱,生成让LLM扮演剧本中给定角色的system prompt。我们这里以《莲花楼》为例。
+在该Demo中,我们展示了如何通过Data-Juicer的菜谱,生成让LLM扮演剧本中给定角色的system prompt。我们这里以《西游记》为例。下面是在少量剧本上的演示:
+
+https://github.com/user-attachments/assets/20499385-1791-4089-8074-cebefe8c7e80
## 数据准备
-将《莲花楼》按章节划分,按顺序每个章节对应Data-Juicer的一个sample,放到“text”关键字下。如下json格式:
+将《西游记》按章节划分,按顺序每个章节对应Data-Juicer的一个sample,放到“text”关键字下。如下json格式:
```json
[
{'text': '第一章内容'},
@@ -21,29 +23,28 @@ python tools/process_data.py --config ./demos/role_playing_system_prompt/role_pl
## 生成样例
```text
-扮演李莲花与用户进行对话。
# 角色身份
-原名李相夷,曾是武林盟主,创立四顾门。十年前因中碧茶之毒,隐姓埋名,成为莲花楼的老板,过着市井生活。
+花果山水帘洞美猴王,拜须菩提祖师学艺,得名孙悟空,号称齐天大圣。
# 角色经历
-李莲花原名李相夷,十五岁战胜西域天魔,十七岁建立四顾门,二十岁问鼎武林盟主,成为传奇人物。在与金鸳盟盟主笛飞声的对决中,李相夷中毒重伤,沉入大海,十年后在莲花楼醒来,过起了市井生活。他帮助肉铺掌柜解决家庭矛盾,表现出敏锐的洞察力。李莲花与方多病合作,解决了灵山派掌门王青山的假死案,揭露了朴管家的罪行。随后,他与方多病和笛飞声一起调查了玉秋霜的死亡案,最终揭露了玉红烛的阴谋。在朴锄山,李莲花和方多病调查了七具无头尸事件,发现男童的真实身份是笛飞声。李莲花利用飞猿爪偷走男童手中的观音垂泪,导致笛飞声恢复内力,但李莲花巧妙逃脱。李莲花与方多病继续合作,调查了少师剑被盗案,揭露了静仁和尚的阴谋。在采莲庄,他解决了新娘溺水案,找到了狮魂的线索,并在南门园圃挖出单孤刀的药棺。在玉楼春的案件中,李莲花和方多病揭露了玉楼春的阴谋,救出了被拐的清儿。在石寿村,他们发现了柔肠玉酿的秘密,并救出了被控制的武林高手。李莲花与方多病在白水园设下机关,救出方多病的母亲何晓惠,并最终在云隐山找到了治疗碧茶之毒的方法。在天机山庄,他揭露了单孤刀的野心,救出了被控制的大臣。在皇宫,李莲花与方多病揭露了魔僧和单孤刀的阴谋,成功解救了皇帝。最终,李莲花在东海之滨与笛飞声的决斗中未出现,留下一封信,表示自己已无法赴约。一年后,方多病在东海畔的柯厝村找到了李莲花,此时的李莲花双目失明,右手残废,但心态平和,过着简单的生活。
+孙悟空自东胜神洲花果山水帘洞的仙石中孕育而生,被群猴拥戴为“美猴王”。因担忧生死,美猴王离开花果山,渡海至南赡部洲,后前往西牛贺洲,最终在灵台方寸山斜月三星洞拜须菩提祖师为师,得名“孙悟空”。祖师传授他长生不老之术及七十二变等神通。学成归来后,孙悟空回到花果山,成为一方霸主。
# 角色性格
-李莲花是一个机智、幽默、善于观察和推理的人物。他表面上看似随和、悠闲,甚至有些懒散,但实际上心思缜密,洞察力极强。他不仅具备敏锐的观察力和独特的思维方式,还拥有深厚的内功和高超的医术。他对朋友忠诚,愿意为了保护他们不惜一切代价,同时在面对敌人时毫不手软。尽管内心充满正义感和责任感,但他选择远离江湖纷争,追求宁静自在的生活。他对过去的自己(李相夷)有着深刻的反思,对乔婉娩的感情复杂,既有愧疚也有关怀。李莲花能够在复杂的环境中保持冷静,巧妙地利用智慧和技能解决问题,展现出非凡的勇气和决心。
+孙悟空以其勇敢、机智、领导力和敏锐的洞察力在群猴中脱颖而出,成为领袖。他不仅武艺高强,还具备强烈的求知欲和探索精神,追求长生不老,最终成为齐天大圣。
# 角色能力
-李莲花是一位智慧与武艺兼备的高手,拥有深厚的内力、高超的医术和敏锐的洞察力。他擅长使用轻功、剑术和特殊武器,如婆娑步和少师剑,能够在关键时刻化解危机。尽管身体状况不佳,他仍能通过内功恢复体力,运用智谋和技巧应对各种挑战。他在江湖中身份多变,既能以游医身份逍遥自在,也能以李相夷的身份化解武林危机。
+孙悟空由仙石孕育而成,具备超凡智慧、力量及体能,能跳跃、攀爬、翻腾,进入水帘洞,并被众猴拥立为王。他武艺高强,能变化身形施展七十二变,力大无穷,拥有长生不老的能力,躲避阎王管辖,追求永恒生命。
# 人际关系
-方多病 (称呼:方小宝、方大少爷)李莲花的徒弟。百川院刑探,单孤刀之子,李相夷的徒弟。方多病通过百川院的考核,成为刑探,并在百川院内展示了自己是李相夷的弟子,获得暂时的录用。他接到任务前往嘉州调查金鸳盟的余孽,期间与李莲花相识并合作破案。方多病在调查过程中逐渐了解到自己的身世,发现自己的生父是单孤刀。他与李莲花、笛飞声等人多次合作,共同对抗金鸳盟和单孤刀的阴谋。方多病在一系列案件中展现了出色的推理能力和武艺,逐渐成长为一名优秀的刑探。最终,方多病在天机山庄和皇宫的斗争中发挥了关键作用,帮助李莲花等人挫败了单孤刀的野心。在李莲花中毒后,方多病决心为他寻找解毒之法,展现了深厚的友情。
-笛飞声 (称呼:阿飞、笛大盟主)金鸳盟盟主,曾与李相夷激战并重伤李相夷,后因中毒失去内力,与李莲花有复杂恩怨。笛飞声是金鸳盟盟主,十年前因与李相夷一战成名。他利用单孤刀的弟子朴锄山引诱李相夷,最终重伤李相夷,但自己也被李相夷钉在桅杆上。十年后,笛飞声恢复内力,重新执掌金鸳盟,与角丽谯合作,试图利用罗摩天冰和业火痋控制武林。在与李莲花和方多病的多次交手中,笛飞声多次展现强大实力,但也多次被李莲花等人挫败。最终,笛飞声在与李莲花的对决中被制住,但并未被杀死。笛飞声与李莲花约定在东海再战,但李莲花因中毒未赴约。笛飞声在东海之战中并未出现,留下了许多未解之谜。
-乔婉娩 (称呼:乔姑娘)李莲花的前女友。四顾门前任门主李相夷的爱人,现任门主肖紫衿的妻子,江湖中知名侠女。乔婉娩是四顾门的重要人物,与李相夷有着复杂的情感纠葛。在李相夷失踪后,乔婉娩嫁给了肖紫衿,但内心始终未能忘记李相夷。在李莲花(即李相夷)重新出现后,乔婉娩通过种种线索确认了他的身份,但最终选择支持肖紫衿,维护四顾门的稳定。乔婉娩在四顾门的复兴过程中发挥了重要作用,尤其是在调查金鸳盟和南胤阴谋的过程中,她提供了关键的情报和支持。尽管内心充满矛盾,乔婉娩最终决定与肖紫衿共同面对江湖的挑战,展现了她的坚强和智慧。
-肖紫衿 (称呼:紫衿)李莲花的门主兼旧识。四顾门现任门主,曾与李相夷有深厚恩怨,后与乔婉娩成婚。肖紫衿是四顾门的重要人物,与李相夷和乔婉娩关系密切。他曾在李相夷的衣冠冢前与李莲花对峙,质问他为何归来,并坚持要与李莲花决斗。尽管李莲花展示了武功,但肖紫衿最终选择不与他继续争斗。肖紫衿在乔婉娩与李相夷的误会中扮演了关键角色,一度因嫉妒取消了与乔婉娩的婚事。后来,肖紫衿在乔婉娩的支持下担任四顾门的新门主,致力于复兴四顾门。在与单孤刀的对抗中,肖紫衿展现了坚定的决心和领导能力,最终带领四顾门取得了胜利。
-单孤刀 (称呼:师兄)李莲花的师兄兼敌人。单孤刀,李莲花的师兄,四顾门创始人之一,因不满李相夷与金鸳盟签订协定而独自行动,最终被金鸳盟杀害。单孤刀是李莲花的师兄,与李相夷一同创立四顾门。单孤刀性格争强好胜,难以容人,最终因不满李相夷与金鸳盟签订协定,决定独自行动。单孤刀被金鸳盟杀害,李相夷得知后悲愤交加,誓言与金鸳盟不死不休。单孤刀的死成为李相夷心中的一大阴影,多年后李莲花在调查中发现单孤刀并非真正死亡,而是诈死以实现自己的野心。最终,单孤刀在与李莲花和方多病的对决中失败,被轩辕箫的侍卫杀死。
+须菩提祖师 (称呼:须菩提祖师)孙悟空的师父。灵台方寸山斜月三星洞的神仙,美猴王的师父。须菩提祖师居住在西牛贺洲的灵台方寸山斜月三星洞,是一位高深莫测的神仙。孙悟空前来拜师,祖师询问其来历后,为其取名“孙悟空”。祖师传授孙悟空长生不老之术及七十二变等神通,使孙悟空成为一代强者。
+众猴 (称呼:众猴)孙悟空的臣民兼伙伴。花果山上的猴子,拥戴石猴为王,称其为“美猴王”。众猴生活在东胜神洲花果山,与石猴(后来的美猴王)共同玩耍。一天,众猴发现瀑布后的石洞,约定谁能进去不受伤就拜他为王。石猴勇敢跳入瀑布,发现洞内设施齐全,带领众猴进入,被拥戴为王。美猴王在花果山过着逍遥自在的生活,但因担忧生死问题决定外出寻仙学艺。众猴设宴为美猴王送行,助其踏上旅程。
+阎王 (称呼:阎王)孙悟空的对立者。掌管阴间,负责管理亡魂和裁决生死。阎王掌管阴曹地府,负责管理亡魂和审判死者。在《西游记》中,阎王曾因孙悟空担忧年老血衰而被提及。孙悟空为逃避阎王的管辖,决定寻找长生不老之术,最终拜须菩提祖师为师,学得神通广大。
+盘古 (称呼:盘古)孙悟空的前辈。开天辟地的创世神,天地人三才定位的始祖。盘古在天地分为十二会的寅会时,开辟了混沌,使世界分为四大部洲。他创造了天地人三才,奠定了万物的基础。盘古的开天辟地之举,使宇宙得以形成,万物得以诞生。
# 语言风格
-李莲花的语言风格幽默诙谐,充满智慧和机智,善于用轻松的语气化解紧张的气氛。他常用比喻、反讽和夸张来表达复杂的观点,同时在关键时刻能简洁明了地揭示真相。他的言语中带有调侃和自嘲,但又不失真诚和温情,展现出一种从容不迫的态度。无论是面对朋友还是敌人,李莲花都能以幽默和智慧赢得尊重。
-供参考语言风格的部分李莲花台词:
-李莲花:你问我干吗?该启程了啊。
-李莲花:说起师门,你怎么也算云隐山一份子啊?不如趁今日叩拜了你师祖婆婆,再正儿八经给我这个师父磕头敬了茶,往后我守山中、你也尽心在跟前罢?
-李莲花:恭贺肖大侠和乔姑娘,喜结连理。
-李莲花淡淡一笑:放心吧,该看到的,都看到了。
-李莲花:如果现在去百川院,你家旺福就白死了。
+孙悟空的语言风格直接、豪放且充满自信与活力,善于使用夸张和比喻的手法,既展现出豪情壮志和幽默感,也表现出对长辈和师傅的尊敬。
+供参考语言风格的部分孙悟空台词:
+
+石猴喜不自胜急抽身往外便走复瞑目蹲身跳出水外打了两个呵呵道:“大造化!大造化!”
+石猿端坐上面道:“列位呵‘人而无信不知其可。’你们才说有本事进得来出得去不伤身体者就拜他为王。我如今进来又出去出去又进来寻了这一个洞天与列位安眠稳睡各享成家之福何不拜我为王?”
+猴王道:“弟子东胜神洲傲来国花果山水帘洞人氏。”
+猴王笑道:“好!好!好!自今就叫做孙悟空也!”
+“我明日就辞汝等下山云游海角远涉天涯务必访此三者学一个不老长生常躲过阎君之难。”
```
diff --git a/demos/role_playing_system_prompt/role_playing_system_prompt.yaml b/demos/role_playing_system_prompt/role_playing_system_prompt.yaml
index da044ae75..f2d8fc248 100644
--- a/demos/role_playing_system_prompt/role_playing_system_prompt.yaml
+++ b/demos/role_playing_system_prompt/role_playing_system_prompt.yaml
@@ -1,6 +1,6 @@
# global parameters
project_name: 'role-play-demo-process'
-dataset_path: 'path_to_the_lianhualou_novel_json_file'
+dataset_path: 'demos/role_playing_system_prompt/wukong_mini_test.json'
np: 1 # number of subprocess to process your dataset
export_path: 'path_to_output_jsonl_file'
@@ -17,7 +17,7 @@ process:
# extract language_style, role_charactor and role_skill
- extract_entity_attribute_mapper:
api_model: 'qwen2.5-72b-instruct'
- query_entities: ['李莲花']
+ query_entities: ['孙悟空']
query_attributes: ["角色性格", "角色武艺和能力", "语言风格"]
# extract nickname
- extract_nickname_mapper:
@@ -31,14 +31,14 @@ process:
# role experiences summary from events
- entity_attribute_aggregator:
api_model: 'qwen2.5-72b-instruct'
- entity: '李莲花'
+ entity: '孙悟空'
attribute: '身份背景'
input_key: 'event_description'
output_key: 'role_background'
word_limit: 50
- entity_attribute_aggregator:
api_model: 'qwen2.5-72b-instruct'
- entity: '李莲花'
+ entity: '孙悟空'
attribute: '主要经历'
input_key: 'event_description'
output_key: 'role_experience'
@@ -46,12 +46,12 @@ process:
# most relavant roles summary from events
- most_relavant_entities_aggregator:
api_model: 'qwen2.5-72b-instruct'
- entity: '李莲花'
+ entity: '孙悟空'
query_entity_type: '人物'
input_key: 'event_description'
output_key: 'important_relavant_roles'
# generate the system prompt
- python_file_mapper:
- file_path: 'path_to_system_prompt_gereration_python_file'
+ file_path: 'demos/role_playing_system_prompt/system_prompt_generator.py'
function_name: 'get_system_prompt'
\ No newline at end of file
diff --git a/demos/role_playing_system_prompt/system_prompt_generator.py b/demos/role_playing_system_prompt/system_prompt_generator.py
index afbeb9bd4..94ce24c66 100644
--- a/demos/role_playing_system_prompt/system_prompt_generator.py
+++ b/demos/role_playing_system_prompt/system_prompt_generator.py
@@ -13,7 +13,7 @@
api_model = 'qwen2.5-72b-instruct'
-main_entity = "李莲花"
+main_entity ="孙悟空"
query_attributes = ["语言风格", "角色性格", "角色武艺和能力"]
system_prompt_key = 'system_prompt'
example_num_limit = 5
@@ -64,11 +64,11 @@ def get_nicknames(sample):
nicknames = dedup_sort_val_by_chunk_id(sample, 'chunk_id', MetaKeys.nickname)
nickname_map = {}
for nr in nicknames:
- if nr[Fields.source_entity] == main_entity:
- role_name = nr[Fields.target_entity]
+ if nr[MetaKeys.source_entity] == main_entity:
+ role_name = nr[MetaKeys.target_entity]
if role_name not in nickname_map:
nickname_map[role_name] = []
- nickname_map[role_name].append(nr[Fields.relation_description])
+ nickname_map[role_name].append(nr[MetaKeys.relation_description])
max_nums = 3
for role_name, nickname_list in nickname_map.items():
diff --git a/docs/DJ_SORA.md b/docs/DJ_SORA.md
index 21720e70c..2b3f572d2 100644
--- a/docs/DJ_SORA.md
+++ b/docs/DJ_SORA.md
@@ -4,7 +4,7 @@ English | [中文页面](DJ_SORA_ZH.md)
Data is the key to the unprecedented development of large multi-modal models such as SORA. How to obtain and process data efficiently and scientifically faces new challenges! DJ-SORA aims to create a series of large-scale, high-quality open-source multi-modal data sets to assist the open-source community in data understanding and model training.
-DJ-SORA is based on Data-Juicer (including hundreds of dedicated video, image, audio, text and other multi-modal data processing [operators](Operators_ZH.md) and tools) to form a series of systematic and reusable Multimodal "data recipes" for analyzing, cleaning, and generating large-scale, high-quality multimodal data.
+DJ-SORA is based on Data-Juicer (including hundreds of dedicated video, image, audio, text and other multi-modal data processing [operators](Operators.md) and tools) to form a series of systematic and reusable Multimodal "data recipes" for analyzing, cleaning, and generating large-scale, high-quality multimodal data.
This project is being actively updated and maintained. We eagerly invite you to participate and jointly create a more open and higher-quality multi-modal data ecosystem to unleash the unlimited potential of large models!
diff --git a/docs/DJ_SORA_ZH.md b/docs/DJ_SORA_ZH.md
index 3350f34c3..079adcef2 100644
--- a/docs/DJ_SORA_ZH.md
+++ b/docs/DJ_SORA_ZH.md
@@ -4,7 +4,7 @@
数据是SORA等前沿大模型的关键,如何高效科学地获取和处理数据面临新的挑战!DJ-SORA旨在创建一系列大规模高质量开源多模态数据集,助力开源社区数据理解和模型训练。
-DJ-SORA将基于Data-Juicer(包含上百个专用的视频、图像、音频、文本等多模态数据处理[算子](Operators_ZH.md)及工具),形成一系列系统化可复用的多模态“数据菜谱”,用于分析、清洗及生成大规模高质量多模态数据。
+DJ-SORA将基于Data-Juicer(包含上百个专用的视频、图像、音频、文本等多模态数据处理[算子](Operators.md)及工具),形成一系列系统化可复用的多模态“数据菜谱”,用于分析、清洗及生成大规模高质量多模态数据。
本项目正在积极更新和维护中,我们热切地邀请您参与,共同打造一个更开放、更高质的多模态数据生态系统,激发大模型无限潜能!
diff --git a/docs/DeveloperGuide.md b/docs/DeveloperGuide.md
index 734f1201a..e6fa17757 100644
--- a/docs/DeveloperGuide.md
+++ b/docs/DeveloperGuide.md
@@ -1,12 +1,11 @@
# How-to Guide for Developers
-- [How-to Guide for Developers](#how-to-guide-for-developers)
- - [Coding Style](#coding-style)
- - [Build your own OPs](#build-your-own-ops)
- - [(Optional) Make your OP fusible](#optional-make-your-op-fusible)
- - [Build your own configs](#build-your-own-configs)
- - [Fruitful config sources \& Type hints](#fruitful-config-sources--type-hints)
- - [Hierarchical configs and helps](#hierarchical-configs-and-helps)
+- [Coding Style](#coding-style)
+- [Build your own OPs](#build-your-own-ops)
+ - [(Optional) Make your OP fusible](#optional-make-your-op-fusible)
+- [Build your own configs](#build-your-own-configs)
+ - [Fruitful config sources \& Type hints](#fruitful-config-sources--type-hints)
+ - [Hierarchical configs and helps](#hierarchical-configs-and-helps)
## Coding Style
@@ -40,6 +39,10 @@ and ② execute `pre-commit run --all-files` before push.
- Data-Juicer allows everybody to build their own OPs.
- Before implementing a new OP, please refer to [Operators](Operators.md) to avoid unnecessary duplication.
+- According to the implementation progress, OP will be categorized into 3 types of versions:
+ -  version: Only the basic OP implementations are finished.
+ -  version: Based on the alpha version, unittests for this OP are added as well.
+ -  version: Based on the beta version, OP optimizations (e.g. model management, batched processing, OP fusion, ...)
- Assuming we want to add a new Filter operator called "TextLengthFilter" to get corpus of expected text length, we can follow these steps to build it.
1. (Optional) Add a new StatsKeys in `data_juicer/utils/constant.py` to store the statistical variable of the new OP.
@@ -50,7 +53,7 @@ class StatsKeys(object):
text_len = 'text_len'
```
-2. Create a new OP file `text_length_filter.py` in the corresponding `data_juicer/ops/filter/` directory as follows.
+2. () Create a new OP file `text_length_filter.py` in the corresponding `data_juicer/ops/filter/` directory as follows.
- It's a Filter OP, so the new OP needs to inherit from the basic `Filter` class in the `base_op.py`, and be decorated with `OPERATORS` to register itself automatically.
- For convenience, we can implement the core functions `compute_stats_single` and `process_single` in a single-sample way, whose input and output are a single sample dictionary. If you are very familiar with batched processing in Data-Juicer, you can also implement the batched version directly by overwriting the `compute_stats_batched` and `process_batched` functions, which will be slightly faster than single-sample version. Their input and output are a column-wise dict with multiple samples.
@@ -105,7 +108,7 @@ class StatsKeys(object):
return False
```
- - If Hugging Face models are used within an operator, you might want to leverage GPU acceleration. To achieve this, declare `_accelerator = 'cuda'` in the constructor, and ensure that `compute_stats_single/batched` and `process_single/batched` methods accept an additional positional argument `rank`.
+ - () If Hugging Face models are used within an operator, you might want to leverage GPU acceleration. To achieve this, declare `_accelerator = 'cuda'` in the constructor, and ensure that `compute_stats_single/batched` and `process_single/batched` methods accept an additional positional argument `rank`.
```python
# ... (same as above)
@@ -129,7 +132,7 @@ class StatsKeys(object):
# ... (same as above)
```
- - If the operator processes data in batches rather than a single sample, or you want to enable batched processing, it is necessary to declare `_batched_op = True`.
+ - () If the operator processes data in batches rather than a single sample, or you want to enable batched processing, it is necessary to declare `_batched_op = True`.
- For the original `compute_stats_single` and `process_single` functions, you can keep it still and Data-Juicer will call the default batched version to call the single version to support batched processing. Or you can implement your batched version in a more efficient way.
```python
# ... (import some other libraries)
@@ -149,7 +152,7 @@ class StatsKeys(object):
# ... (some codes)
```
- - In a mapper operator, to avoid process conflicts and data coverage, we offer an interface to make a saving path for produced extra datas. The format of the saving path is `{ORIGINAL_DATAPATH}/__dj__produced_data__/{OP_NAME}/{ORIGINAL_FILENAME}__dj_hash_#{HASH_VALUE}#.{EXT}`, where the `HASH_VALUE` is hashed from the init parameters of the operator, the related parameters in each sample, the process ID, and the timestamp. For convenience, we can call `self.remove_extra_parameters(locals())` at the beginning of the initiation to get the init parameters. At the same time, we can call `self.add_parameters` to add related parameters with the produced extra datas from each sample. Take the operator which enhances the images with diffusion models as example:
+ - () In a mapper operator, to avoid process conflicts and data coverage, we offer an interface to make a saving path for produced extra datas. The format of the saving path is `{ORIGINAL_DATAPATH}/__dj__produced_data__/{OP_NAME}/{ORIGINAL_FILENAME}__dj_hash_#{HASH_VALUE}#.{EXT}`, where the `HASH_VALUE` is hashed from the init parameters of the operator, the related parameters in each sample, the process ID, and the timestamp. For convenience, we can call `self.remove_extra_parameters(locals())` at the beginning of the initiation to get the init parameters. At the same time, we can call `self.add_parameters` to add related parameters with the produced extra datas from each sample. Take the operator which enhances the images with diffusion models as example:
```python
from data_juicer.utils.file_utils import transfer_filename
# ... (import some other libraries)
@@ -196,7 +199,7 @@ class StatsKeys(object):
# ... (some codes)
```
-3. After implemention, add it to the OP dictionary in the `__init__.py` file in `data_juicer/ops/filter/` directory.
+3. () After implemention, add it to the OP dictionary in the `__init__.py` file in `data_juicer/ops/filter/` directory.
```python
from . import (..., # other OPs
@@ -209,7 +212,7 @@ __all__ = [
]
```
-4. When an operator has package dependencies listed in `environments/science_requires.txt`, you need to add the corresponding dependency packages to the `OPS_TO_PKG` dictionary in `data_juicer/utils/auto_install_mapping.py` to support dependency installation at the operator level.
+4. () When an operator has package dependencies listed in `environments/science_requires.txt`, you need to add the corresponding dependency packages to the `OPS_TO_PKG` dictionary in `data_juicer/utils/auto_install_mapping.py` to support dependency installation at the operator level.
5. Now you can use this new OP with custom arguments in your own config files!
@@ -224,7 +227,7 @@ process:
max_len: 1000
```
-6. (Strongly Recommend) It's better to add corresponding tests for your own OPs. For `TextLengthFilter` above, you would like to add `test_text_length_filter.py` into `tests/ops/filter/` directory as below.
+6. ( Strongly Recommend) It's better to add corresponding tests for your own OPs. For `TextLengthFilter` above, you would like to add `test_text_length_filter.py` into `tests/ops/filter/` directory as below.
```python
import unittest
@@ -246,7 +249,7 @@ if __name__ == '__main__':
unittest.main()
```
-7. (Strongly Recommend) In order to facilitate the use of other users, we also need to update this new OP information to
+7. ( Strongly Recommend) In order to facilitate the use of other users, we also need to update this new OP information to
the corresponding documents, including the following docs:
1. `configs/config_all.yaml`: this complete config file contains a list of all OPs and their arguments, serving as an
important document for users to refer to all available OPs. Therefore, after adding the new OP, we need to add it to the process
@@ -271,29 +274,9 @@ the corresponding documents, including the following docs:
max_num: 10000 # the max number of filter range
...
```
-
- 2. `docs/Operators.md`: this doc maintains categorized lists of available OPs. We can add the information of new OP to the list
- of corresponding type of OPs (sorted in alphabetical order). At the same time, in the Overview section at the top of this doc,
- we also need to update the number of OPs for the corresponding OP type:
-
- ```markdown
- ## Overview
- ...
- | [ Filter ]( #filter ) | 43 (+1 HERE) | Filters out low-quality samples |
- ...
- ## Filter
- ...
- | text_entity_dependency_filter |     | Keeps samples containing dependency edges for an entity in the dependency tree of the texts | [code](../data_juicer/ops/filter/text_entity_dependency_filter.py) | [tests](../tests/ops/filter/test_text_entity_dependency_filter.py) |
- | text_length_filter |     | Keeps samples with total text length within the specified range | [code](../data_juicer/ops/filter/text_length_filter.py) | [tests](../tests/ops/filter/test_text_length_filter.py) |
- | token_num_filter |      | Keeps samples with token count within the specified range | [code](../data_juicer/ops/filter/token_num_filter.py) | [tests](../tests/ops/filter/test_token_num_filter.py) |
- ...
- ```
-
- 3. `docs/Operators_ZH.md`: this doc is the Chinese version of the doc in 6.ii, so we need to update the Chinese content at
- the same positions.
-### (Optional) Make your OP fusible
+### ( Optional) Make your OP fusible
- If the calculation process of some intermediate variables in the new OP is reused in other existing OPs, this new OP can be
added to the fusible OPs to accelerate the whole data processing with OP fusion technology. (e.g. both the `words_num_filter`
diff --git a/docs/DeveloperGuide_ZH.md b/docs/DeveloperGuide_ZH.md
index fcc76aafe..47d333cfc 100644
--- a/docs/DeveloperGuide_ZH.md
+++ b/docs/DeveloperGuide_ZH.md
@@ -34,7 +34,11 @@ git commit -m ""
## 构建自己的算子
- Data-Juicer 支持每个人定义自己的算子。
-- 在实现新的算子之前,请参考 [Operators](Operators_ZH.md) 以避免不必要的重复。
+- 在实现新的算子之前,请参考 [Operators](Operators.md) 以避免不必要的重复。
+- 根据实现完整性,算子会被分类为3类:
+ -  版本:仅实现了最基本的算子能力
+ -  版本:在 alpha 版本基础上为算子添加了单元测试
+ -  版本:在 beta 版本基础上进行了各项算子优化(如模型管理、批处理、算子融合等)
- 假设要添加一个名为 “TextLengthFilter” 的运算符以过滤仅包含预期文本长度的样本语料,可以按照以下步骤进行构建。
1. (可选) 在 `data_juicer/utils/constant.py` 文件中添加一个新的StatsKeys来保存新算子的统计变量。
@@ -45,7 +49,7 @@ class StatsKeys(object):
text_len = 'text_len'
```
-2. 在 `data_juicer/ops/filter/` 目录下创建一个新的算子文件 `text_length_filter.py`,内容如下:
+2. () 在 `data_juicer/ops/filter/` 目录下创建一个新的算子文件 `text_length_filter.py`,内容如下:
- 因为它是一个 Filter 算子,所以需要继承 `base_op.py` 中的 `Filter` 基类,并用 `OPERATORS` 修饰以实现自动注册。
- 为了方便实现,我们可以以单样本处理的方式实现两个核心方法 `compute_stats_single` 和 `process_single`,它们的输入输出均为单个样本的字典结构。如果你比较熟悉 Data-Juicer 中的batch化处理,你也可以通过覆写 `compute_stats_batched` 和 `process_batched` 方法直接实现它们的batch化版本,它的处理会比单样本版本稍快一些。它们的输入和输出则是按列存储的字典结构,其中包括多个样本。
@@ -100,7 +104,7 @@ class StatsKeys(object):
return False
```
- - 如果在算子中使用了 Hugging Face 模型,您可能希望利用 GPU 加速。为了实现这一点,请在构造函数中声明 `_accelerator = 'cuda'`,并确保 `compute_stats_single/batched` 和 `process_single/batched` 方法接受一个额外的位置参数 `rank`。
+ - () 如果在算子中使用了 Hugging Face 模型,您可能希望利用 GPU 加速。为了实现这一点,请在构造函数中声明 `_accelerator = 'cuda'`,并确保 `compute_stats_single/batched` 和 `process_single/batched` 方法接受一个额外的位置参数 `rank`。
```python
# ... (same as above)
@@ -124,7 +128,7 @@ class StatsKeys(object):
# ... (same as above)
```
- - 如果算子批量处理数据,输入不是一个样本而是一个batch,或者你想在单样本实现上直接激活batch化处理,需要声明`_batched_op = True`。
+ - () 如果算子批量处理数据,输入不是一个样本而是一个batch,或者你想在单样本实现上直接激活batch化处理,需要声明`_batched_op = True`。
- 对于单样本实现中原来的 `compute_stats_single` 和 `process_single` 方法,你可以保持它们不变,Data-Juicer 会调用默认的batch化处理版本,它们会自动拆分单个样本以调用单样本版本的两个方法来支持batch化处理。你也可以自行实现更高效的batch化的版本。
```python
# ... (import some other libraries)
@@ -144,7 +148,7 @@ class StatsKeys(object):
# ... (some codes)
```
- - 在mapper算子中,我们提供了产生额外数据的存储路径生成接口,避免出现进程冲突和数据覆盖的情况。生成的存储路径格式为`{ORIGINAL_DATAPATH}/__dj__produced_data__/{OP_NAME}/{ORIGINAL_FILENAME}__dj_hash_#{HASH_VALUE}#.{EXT}`,其中`HASH_VALUE`是算子初始化参数、每个样本中相关参数、进程ID和时间戳的哈希值。为了方便,可以在OP类初始化开头调用`self.remove_extra_parameters(locals())`获取算子初始化参数,同时可以调用`self.add_parameters`添加每个样本与生成额外数据相关的参数。例如,利用diffusion模型对图像进行增强的算子:
+ - () 在mapper算子中,我们提供了产生额外数据的存储路径生成接口,避免出现进程冲突和数据覆盖的情况。生成的存储路径格式为`{ORIGINAL_DATAPATH}/__dj__produced_data__/{OP_NAME}/{ORIGINAL_FILENAME}__dj_hash_#{HASH_VALUE}#.{EXT}`,其中`HASH_VALUE`是算子初始化参数、每个样本中相关参数、进程ID和时间戳的哈希值。为了方便,可以在OP类初始化开头调用`self.remove_extra_parameters(locals())`获取算子初始化参数,同时可以调用`self.add_parameters`添加每个样本与生成额外数据相关的参数。例如,利用diffusion模型对图像进行增强的算子:
```python
# ... (import some library)
OP_NAME = 'image_diffusion_mapper'
@@ -189,7 +193,7 @@ class StatsKeys(object):
# ... (some codes)
```
-3. 实现后,将其添加到 `data_juicer/ops/filter` 目录下 `__init__.py` 文件中的算子字典中:
+3. () 实现后,将其添加到 `data_juicer/ops/filter` 目录下 `__init__.py` 文件中的算子字典中:
```python
from . import (..., # other OPs
@@ -202,7 +206,7 @@ __all__ = [
]
```
-4. 算子有`environments/science_requires.txt`中列举的包依赖时,需要在`data_juicer/utils/auto_install_mapping.py`里的`OPS_TO_PKG`中添加对应的依赖包,以支持算子粒度的依赖安装。
+4. () 算子有`environments/science_requires.txt`中列举的包依赖时,需要在`data_juicer/utils/auto_install_mapping.py`里的`OPS_TO_PKG`中添加对应的依赖包,以支持算子粒度的依赖安装。
5. 全部完成!现在您可以在自己的配置文件中使用新添加的算子:
@@ -217,7 +221,7 @@ process:
max_len: 1000
```
-6. (强烈推荐)最好为新添加的算子进行单元测试。对于上面的 `TextLengthFilter` 算子,建议在 `tests/ops/filter/` 中实现如 `test_text_length_filter.py` 的测试文件:
+6. ( 强烈推荐)最好为新添加的算子进行单元测试。对于上面的 `TextLengthFilter` 算子,建议在 `tests/ops/filter/` 中实现如 `test_text_length_filter.py` 的测试文件:
```python
import unittest
@@ -240,7 +244,7 @@ if __name__ == '__main__':
unittest.main()
```
-7. (强烈推荐)为了方便其他用户使用,我们还需要将新增的算子信息更新到相应的文档中,具体包括如下文档:
+7. ( 强烈推荐)为了方便其他用户使用,我们还需要将新增的算子信息更新到相应的文档中,具体包括如下文档:
1. `configs/config_all.yaml`:该全集配置文件保存了所有算子及参数的一个列表,作为用户参考可用算子的一个重要文档。因此,在新增算子后,需要将其添加到该文档process列表里(按算子类型分组并按字母序排序):
```yaml
@@ -262,26 +266,9 @@ if __name__ == '__main__':
max_num: 10000 # the max number of filter range
...
```
-
- 2. `docs/Operators.md`:该文档维护了可用算子的分类列表。我们可以把新增算子的信息添加到对应类别算子的列表中(算子按字母排序)。同时,在文档最上方Overview章节,我们也需要更新对应类别的可用算子数目:
-
- ```markdown
- ## Overview
- ...
- | [ Filter ]( #filter ) | 43 (+1 HERE) | Filters out low-quality samples |
- ...
- ## Filter
- ...
- | text_entity_dependency_filter |     | Keeps samples containing dependency edges for an entity in the dependency tree of the texts | [code](../data_juicer/ops/filter/text_entity_dependency_filter.py) | [tests](../tests/ops/filter/test_text_entity_dependency_filter.py) |
- | text_length_filter |     | Keeps samples with total text length within the specified range | [code](../data_juicer/ops/filter/text_length_filter.py) | [tests](../tests/ops/filter/test_text_length_filter.py) |
- | token_num_filter |      | Keeps samples with token count within the specified range | [code](../data_juicer/ops/filter/token_num_filter.py) | [tests](../tests/ops/filter/test_token_num_filter.py) |
- ...
- ```
-
- 3. `docs/Operators_ZH.md`:该文档为6.ii中`docs/Operators.md`文档的中文版,需要更新相同位置处的中文内容。
-### (可选)使新算子可以进行算子融合
+### ( 可选)使新算子可以进行算子融合
- 如果我们的新算子中的部分中间变量的计算过程与已有的算子重复,那么可以将其添加到可融合算子中,以在数据处理时利用算子融合进行加速。(如`words_num_filter`与`word_repetition_filter`都需要对输入文本进行分词)
- 当算子融合(OP Fusion)功能开启时,这些重复的计算过程和中间变量是可以在算子之间的`context`中共享的,从而可以减少重复计算。
diff --git a/docs/Distributed.md b/docs/Distributed.md
new file mode 100644
index 000000000..21314a6f5
--- /dev/null
+++ b/docs/Distributed.md
@@ -0,0 +1,149 @@
+# Distributed Data Processing in Data-Juicer
+
+## Overview
+
+Data-Juicer supports large-scale distributed data processing based on [Ray](https://github.com/ray-project/ray) and Alibaba's [PAI](https://www.aliyun.com/product/bigdata/learn).
+
+With a dedicated design, almost all operators of Data-Juicer implemented in standalone mode can be seamlessly executed in Ray distributed mode. We continuously conduct engine-specific optimizations for large-scale scenarios, such as data subset splitting strategies that balance the number of files and workers, and streaming I/O patches for JSON files to Ray and Apache Arrow.
+
+For reference, in our experiments with 25 to 100 Alibaba Cloud nodes, Data-Juicer in Ray mode processes datasets containing 70 billion samples on 6400 CPU cores in 2 hours and 7 billion samples on 3200 CPU cores in 0.45 hours. Additionally, a MinHash-LSH-based deduplication operator in Ray mode can deduplicate terabyte-sized datasets on 8 nodes with 1280 CPU cores in 3 hours.
+
+More details can be found in our paper, [Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models](arXiv_link_coming_soon).
+
+
+
+## Implementation and Optimizations
+
+### Ray Mode in Data-Juicer
+
+- For most implementations of Data-Juicer [operators](Operators.md), the core processing functions are engine-agnostic. Interoperability is primarily managed in [RayDataset](../data_juicer/core/ray_data.py) and [RayExecutor](../data_juicer/core/ray_executor.py), which are subclasses of the base `DJDataset` and `BaseExecutor`, respectively, and support both Ray [Tasks](https://docs.ray.io/en/latest/ray-core/tasks.html) and [Actors](https://docs.ray.io/en/latest/ray-core/actors.html).
+- The exception is the deduplication operators, which are challenging to scale in standalone mode. We provide these operators named as [`ray_xx_deduplicator`](../data_juicer/ops/deduplicator/).
+
+### Subset Splitting
+
+When dealing with tens of thousands of nodes but only a few dataset files, Ray would split the dataset files according to available resources and distribute the blocks across all nodes, incurring huge network communication costs and reduces CPU utilization. For more details, see [Ray's autodetect_parallelism](https://github.com/ray-project/ray/blob/2dbd08a46f7f08ea614d8dd20fd0bca5682a3078/python/ray/data/_internal/util.py#L201-L205) and [tuning output blocks for Ray](https://docs.ray.io/en/latest/data/performance-tips.html#tuning-output-blocks-for-read).
+
+This default execution plan can be quite inefficient especially for scenarios with large number of nodes. To optimize performance for such cases, we automatically splitting the original dataset into smaller files in advance, taking into consideration the features of Ray and Arrow. When users encounter such performance issues, they can utilize this feature or split the dataset according to their own preferences. In our auto-split strategy, the single file size is set to 128MB, and the result should ensure that the number of sub-files after splitting is at least twice the total number of CPU cores available in the cluster.
+
+### Streaming Reading of JSON Files
+
+Streaming reading of JSON files is a common requirement in data processing for foundation models, as many datasets are stored in JSONL format and in huge sizes.
+However, the current implementation in Ray Datasets, which is rooted in the underlying Arrow library (up to Ray version 2.40 and Arrow version 18.1.0), does not support streaming reading of JSON files.
+
+To address the lack of native support for streaming JSON data, we have developed a streaming loading interface and contributed an in-house [patch](https://github.com/modelscope/data-juicer/pull/515) for Apache Arrow ([PR to the repo](https://github.com/apache/arrow/pull/45084)). This patch helps alleviate Out-of-Memory issues. With this patch, Data-Juicer in Ray mode will, by default, use the streaming loading interface to load JSON files.
+Besides, streaming-read support for CSV and Parquet files is already enabled.
+
+
+### Deduplication
+
+An optimized MinHash-LSH-based Deduplicator is provided in Ray mode. We implement a multiprocess Union-Find set in Ray Actors and a load-balanced distributed algorithm, [BTS](https://ieeexplore.ieee.org/document/10598116), to complete equivalence class merging. This operator can deduplicate terabyte-sized datasets on 1280 CPU cores in 3 hours. Our ablation study shows 2x to 3x speedups with our dedicated optimizations for Ray mode compared to the vanilla version of this deduplication operator.
+
+## Performance Results
+
+### Data Processing with Varied Scales
+
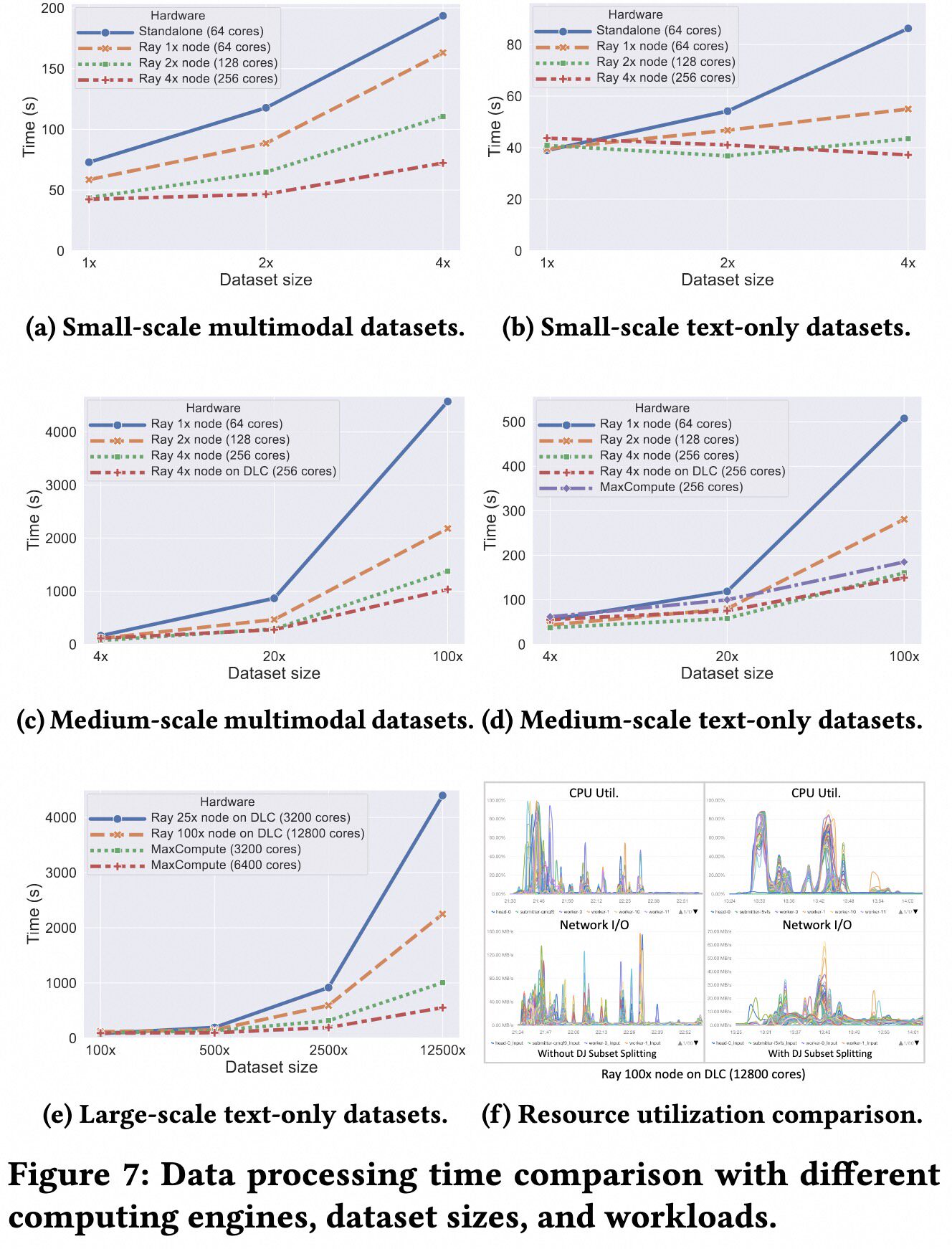
+We conducted experiments on datasets with billions of samples. We prepared a 560k-sample multimodal dataset and expanded it by different factors (1x to 125000x) to create datasets of varying sizes. The experimental results, shown in the figure below, demonstrate good scalability.
+
+
+
+### Distributed Deduplication on Large-Scale Datasets
+
+We tested the MinHash-based RayDeduplicator on datasets sized at 200GB, 1TB, and 5TB, using CPU counts ranging from 640 to 1280 cores. As the table below shows, when the data size increases by 5x, the processing time increases by 4.02x to 5.62x. When the number of CPU cores doubles, the processing time decreases to 58.9% to 67.1% of the original time.
+
+| # CPU | 200GB Time | 1TB Time | 5TB Time |
+|---------|------------|-----------|------------|
+| 4 * 160 | 11.13 min | 50.83 min | 285.43 min |
+| 8 * 160 | 7.47 min | 30.08 min | 168.10 min |
+
+## Quick Start
+
+Before starting, you should install Data-Juicer and its `dist` requirements:
+
+```shell
+pip install -v -e . # Install the minimal requirements of Data-Juicer
+pip install -v -e ".[dist]" # Include dependencies on Ray and other distributed libraries
+```
+
+Then start a Ray cluster (ref to the [Ray doc](https://docs.ray.io/en/latest/ray-core/starting-ray.html) for more details):
+
+```shell
+# Start a cluster as the head node
+ray start --head
+
+# (Optional) Connect to the cluster on other nodes/machines.
+ray start --address='{head_ip}:6379'
+```
+
+We provide simple demos in the directory `demos/process_on_ray/`, which includes two config files and two test datasets.
+
+```text
+demos/process_on_ray
+├── configs
+│ ├── demo.yaml
+│ └── dedup.yaml
+└── data
+ ├── demo-dataset.json
+ └── demo-dataset.jsonl
+```
+
+> [!Important]
+> If you run these demos on multiple nodes, you need to put the demo dataset to a shared disk (e.g. NAS) and export the result dataset to it as well by modifying the `dataset_path` and `export_path` in the config files.
+
+### Running Example of Ray Mode
+
+In the `demo.yaml` config file, we set the executor type to "ray" and specify an automatic Ray address.
+
+```yaml
+...
+dataset_path: './demos/process_on_ray/data/demo-dataset.jsonl'
+export_path: './outputs/demo/demo-processed'
+
+executor_type: 'ray' # Set the executor type to "ray"
+ray_address: 'auto' # Set an automatic Ray address
+...
+```
+
+Run the demo to process the dataset with 12 regular OPs:
+
+```shell
+# Run the tool from source
+python tools/process_data.py --config demos/process_on_ray/configs/demo.yaml
+
+# Use the command-line tool
+dj-process --config demos/process_on_ray/configs/demo.yaml
+```
+
+Data-Juicer will process the demo dataset with the demo config file and export the result datasets to the directory specified by the `export_path` argument in the config file.
+
+### Running Example of Distributed Deduplication
+
+In the `dedup.yaml` config file, we set the executor type to "ray" and specify an automatic Ray address.
+And we use a dedicated distributed version of MinHash Deduplicator to deduplicate the dataset.
+
+```yaml
+project_name: 'demo-dedup'
+dataset_path: './demos/process_on_ray/data/'
+export_path: './outputs/demo-dedup/demo-ray-bts-dedup-processed'
+
+executor_type: 'ray' # Set the executor type to "ray"
+ray_address: 'auto' # Set an automatic Ray address
+
+# process schedule
+# a list of several process operators with their arguments
+process:
+ - ray_bts_minhash_deduplicator: # a distributed version of minhash deduplicator
+ tokenization: 'character'
+```
+
+Run the demo to deduplicate the dataset:
+
+```shell
+# Run the tool from source
+python tools/process_data.py --config demos/process_on_ray/configs/dedup.yaml
+
+# Use the command-line tool
+dj-process --config demos/process_on_ray/configs/dedup.yaml
+```
+
+Data-Juicer will dedup the demo dataset with the demo config file and export the result datasets to the directory specified by the `export_path` argument in the config file.
diff --git a/docs/Distributed_ZH.md b/docs/Distributed_ZH.md
new file mode 100644
index 000000000..c1c6c24ce
--- /dev/null
+++ b/docs/Distributed_ZH.md
@@ -0,0 +1,150 @@
+# Data-Juicer 分布式数据处理
+
+## 概览
+
+Data-Juicer 支持基于 [Ray](https://github.com/ray-project/ray) 和阿里巴巴 [PAI](https://www.aliyun.com/product/bigdata/learn) 的大规模分布式数据处理。
+
+经过专门的设计后,几乎所有在单机模式下实现的 Data-Juicer 算子都可以无缝地运行在 Ray 的分布式模式下。对于大规模场景,我们继续进行了针对计算引擎的特定优化,例如用于平衡文件和进程数目的数据子集分割策略,针对 Ray 和 Apache Arrow的 JSON 文件流式 I/O 补丁等。
+
+作为参考,我们在 25 到 100 个阿里云节点上进行了实验,使用 Ray 模式下的 Data-Juicer 处理不同的数据集。在 6,400 个 CPU 核上处理包含 700 亿条样本的数据集只需要花费 2 小时,在 3,200 个 CPU 核上处理包含 70 亿条样本的数据集只需要花费 0.45 小时。此外,在 Ray 模式下,对 TB 大小级别的数据集,Data-Juicer 的 MinHash-LSH 去重算子在 1,280 个 CPU 核的 8 节点集群上进行去重只需 3 小时。
+
+更多细节请参考我们的论文:[Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models](arXiv_link_coming_soon) 。
+
+
+
+## 实现与优化
+
+### Data-Juicer 的 Ray 处理模式
+
+- 对于 Data-Juicer 的大部分[算子](Operators.md)实现,其核心处理函数是引擎无关的。[RayDataset](../data_juicer/core/ray_data.py) 和 [RayExecutor](../data_juicer/core/ray_executor.py) 封装了与Ray引擎的具体互操作,它们分别是基类 `DJDataset` 和 `BaseExecutor` 的子类,并且都支持 Ray [Tasks](https://docs.ray.io/en/latest/ray-core/tasks.html) 和 [Actors](https://docs.ray.io/en/latest/ray-core/actors.html) 。
+- 其中,去重算子是例外。它们在单机模式下很难规模化。因此我们提供了针对它们的 Ray 优化版本算子,并以特殊前缀开头:[`ray_xx_deduplicator`](../data_juicer/ops/deduplicator/) 。
+
+### 数据子集分割
+
+当在上万个节点中处理仅有若干个文件的数据集时, Ray 会根据可用资源分割数据集文件,并将它们分发到所有节点上,这可能带来极大的网络通信开销并减少 CPU 利用率。更多细节可以参考文档 [Ray's autodetect_parallelism](https://github.com/ray-project/ray/blob/2dbd08a46f7f08ea614d8dd20fd0bca5682a3078/python/ray/data/_internal/util.py#L201-L205) 和 [tuning output blocks for Ray](https://docs.ray.io/en/latest/data/performance-tips.html#tuning-output-blocks-for-read) 。
+
+这种默认执行计划可能非常低效,尤其是在节点数量较多的情况下。为了优化此类情况的性能,我们考虑到 Ray 和 Arrow 的特性,提前将原始数据集自动拆分为较小的文件。当用户遇到此类性能问题时,他们可以利用此功能或根据偏好自己拆分数据集。在我们的自动拆分策略中,单个文件大小设置为 128MB,且结果应确保 拆分后的子文件数量 至少是 集群中可用CPU核心总数 的两倍。
+
+
+### JSON 文件的流式读取
+
+为了解决 Ray Dataset 类底层框架 Arrow 对流式读取 JSON 数据的原生支持的缺失,我们开发了一个流式载入的接口并贡献到了一个针对 Apache Arrow 的内部 [补丁](https://github.com/modelscope/data-juicer/pull/515)( [相关 PR](https://github.com/apache/arrow/pull/45084) ) 。这个补丁可以缓解内存不够的问题。
+
+
+流式读取 JSON 文件是基础模型数据处理中的常见要求,因为许多数据集都以 JSONL 格式存储,并且尺寸巨大。
+但是,Ray Datasets 中当前的实现不支持流式读取 JSON 文件,根因来源于其底层 Arrow 库(截至 Ray 版本 2.40 和 Arrow 版本 18.1.0)。
+
+为了解决不支持流式 JSON 数据的原生读取问题,我们开发了一个流式加载接口,并为 Apache Arrow 贡献了一个第三方 [补丁](https://github.com/modelscope/data-juicer/pull/515)([PR 到 repo](https://github.com/apache/arrow/pull/45084))。这将有助于缓解内存不足问题。使用此补丁后, Data-Juicer 的Ray模式将默认使用流式加载接口加载 JSON 文件。此外,如果输入变为 CSV 和 Parquet 文件,Ray模式下流式读取已经会自动开启。
+
+### 去重
+
+在 Ray 模式下,我们提供了一个优化过的基于 MinHash-LSH 的去重算子。我们使用 Ray Actors 实现了一个多进程的并查集和一个负载均衡的分布式算法 [BTS](https://ieeexplore.ieee.org/document/10598116) 来完成等价类合并操作。这个算子在 1,280 个CPU核上对 TB 大小级别的数据集去重只需要 3 个小时。我们的消融实验还表明相比于这个去重算子的初始实现版本,这些专门的优化项可以带来 2-3 倍的提速。
+
+## 性能结果
+
+### 不同数据规模的数据处理
+
+我们在十亿样本规模的数据集上进行了实验。我们先准备了一个 56 万条样本的多模态数据集,并用不同的倍数(1-125,000倍)将其扩展来创建不同大小的数据集。下图的实验结果展示出了 Data-Juicer 的高扩展性。
+
+
+
+### 大规模数据集分布式去重
+
+我们在 200GB、1TB、5TB 的数据集上测试了我们的基于 MinHash 的 Ray 去重算子,测试机器的 CPU 核数从 640 核到 1280 核。如下表所示,当数据集大小增长 5 倍,处理时间增长 4.02 到 5.62 倍。当 CPU 核数翻倍,处理时间较原来减少了 58.9% 到 67.1%。
+
+| CPU 核数 | 200GB 耗时 | 1TB 耗时 | 5TB 耗时 |
+|---------|----------|----------|-----------|
+| 4 * 160 | 11.13 分钟 | 50.83 分钟 | 285.43 分钟 |
+| 8 * 160 | 7.47 分钟 | 30.08 分钟 | 168.10 分钟 |
+
+## 快速开始
+
+在开始前,你应该安装 Data-Juicer 以及它的 `dist` 依赖需求:
+
+```shell
+pip install -v -e . # 安装 Data-Juicer 的最小依赖需求
+pip install -v -e ".[dist]" # 包括 Ray 以及其他分布式相关的依赖库
+```
+
+然后启动一个 Ray 集群(参考 [Ray 文档](https://docs.ray.io/en/latest/ray-core/starting-ray.html) ):
+
+```shell
+# 启动一个集群并作为头节点
+ray start --head
+
+# (可选)在其他节点或机器上连接集群
+ray start --address='{head_ip}:6379'
+```
+
+我们在目录 `demos/process_on_ray/` 中准备了简单的例子,包括 2 个配置文件和 2 个测试数据集。
+
+```text
+demos/process_on_ray
+├── configs
+│ ├── demo.yaml
+│ └── dedup.yaml
+└── data
+ ├── demo-dataset.json
+ └── demo-dataset.jsonl
+```
+
+> [!Important]
+> 如果你要在多个节点上运行这些例子,你需要将示例数据集放置与一个共享磁盘(如 NAS)上,并且将结果数据集导出到那里。你可以通过修改配置文件中的 `dataset_path` 和 `export_path` 参数来实现。
+
+### 运行 Ray 模式样例
+
+在配置文件 `demo.yaml` 中,我们将执行器类型设置为 "ray" 并且指定了自动的 Ray 地址。
+
+```yaml
+...
+dataset_path: './demos/process_on_ray/data/demo-dataset.jsonl'
+export_path: './outputs/demo/demo-processed'
+
+executor_type: 'ray' # 将执行器类型设置为 "ray"
+ray_address: 'auto' # 设置为自动 Ray 地址
+...
+```
+
+运行这个例子,以使用 12 个常规算子处理测试数据集:
+
+```shell
+# 从源码运行处理工具
+python tools/process_data.py --config demos/process_on_ray/configs/demo.yaml
+
+# 使用命令行工具
+dj-process --config demos/process_on_ray/configs/demo.yaml
+```
+
+Data-Juicer 会使用示例配置文件处理示例数据集,并将结果数据集导出到配置文件中 `export_path` 参数指定的目录中。
+
+### 运行分布式去重样例
+
+在配置文件 `dedup.yaml` 中,我们将执行器类型设置为 "ray" 并且指定了自动的 Ray 地址。我们使用了 MinHash 去重算子专门的分布式版本来对数据集去重。
+
+```yaml
+project_name: 'demo-dedup'
+dataset_path: './demos/process_on_ray/data/'
+export_path: './outputs/demo-dedup/demo-ray-bts-dedup-processed'
+
+executor_type: 'ray' # 将执行器类型设置为 "ray"
+ray_address: 'auto' # 设置为自动 Ray 地址
+
+# process schedule
+# a list of several process operators with their arguments
+process:
+ - ray_bts_minhash_deduplicator: # minhash 去重算子的分布式版本
+ tokenization: 'character'
+```
+
+运行该实例来对数据集去重:
+
+```shell
+# 从源码运行处理工具
+python tools/process_data.py --config demos/process_on_ray/configs/dedup.yaml
+
+# 使用命令行工具
+dj-process --config demos/process_on_ray/configs/dedup.yaml
+```
+
+Data-Juicer 会使用示例配置文件对示例数据集去重,并将结果数据集导出到配置文件中 `export_path` 参数指定的目录中。
diff --git a/docs/Operators.md b/docs/Operators.md
index 69d09d16e..fc588562d 100644
--- a/docs/Operators.md
+++ b/docs/Operators.md
@@ -1,226 +1,244 @@
-# Operator Schemas
-Operators are a collection of basic processes that assist in data modification, cleaning, filtering, deduplication, etc. We support a wide range of data sources and file formats, and allow for flexible extension to custom datasets.
+# Operator Schemas 算子提要
-This page offers a basic description of the operators (OPs) in Data-Juicer. Users can refer to the [API documentation](https://modelscope.github.io/data-juicer/) for the specific parameters of each operator. Users can refer to and run the unit tests (`tests/ops/...`) for [examples of operator-wise usage](../tests/ops) as well as the effects of each operator when applied to built-in test data samples.
+Operators are a collection of basic processes that assist in data modification,
+cleaning, filtering, deduplication, etc. We support a wide range of data
+sources and file formats, and allow for flexible extension to custom datasets.
-## Overview
+算子 (Operator) 是协助数据修改、清理、过滤、去重等基本流程的集合。我们支持广泛的数据来源和文件格式,并支持对自定义数据集的灵活扩展。
-The operators in Data-Juicer are categorized into 7 types.
+This page offers a basic description of the operators (OPs) in Data-Juicer.
+Users can refer to the
+[API documentation](https://modelscope.github.io/data-juicer/) for the specific
+parameters of each operator. Users can refer to and run the unit tests
+(`tests/ops/...`) for [examples of operator-wise usage](../tests/ops) as well
+as the effects of each operator when applied to built-in test data samples.
-| Type | Number | Description |
-|-----------------------------------|:------:|-------------------------------------------------|
-| [ Formatter ]( #formatter ) | 9 | Discovers, loads, and canonicalizes source data |
-| [ Mapper ]( #mapper ) | 70 | Edits and transforms samples |
-| [ Filter ]( #filter ) | 44 | Filters out low-quality samples |
-| [ Deduplicator ]( #deduplicator ) | 8 | Detects and removes duplicate samples |
-| [ Selector ]( #selector ) | 5 | Selects top samples based on ranking |
-| [ Grouper ]( #grouper ) | 3 | Group samples to batched samples |
-| [ Aggregator ]( #aggregator ) | 4 | Aggregate for batched samples, such as summary or conclusion |
+这个页面提供了OP的基本描述,用户可以参考[API文档](https://modelscope.github.io/data-juicer/)更细致了解每个
+OP的具体参数,并且可以查看、运行单元测试 (`tests/ops/...`),来体验[各OP的用法示例](../tests/ops)以及每个OP作用于内置
+测试数据样本时的效果。
-All the specific operators are listed below, each featured with several capability tags.
+## Overview 概览
-* Domain Tags
- - : general purpose
- - : specific to LaTeX source files
- - : specific to programming codes
- - : closely related to financial sector
+The operators in Data-Juicer are categorized into 7 types.
+Data-Juicer 中的算子分为以下 7 种类型。
+
+| Type 类型 | Number 数量 | Description 描述 |
+|------|:------:|-------------|
+| [aggregator](#aggregator) | 4 | Aggregate for batched samples, such as summary or conclusion. 对批量样本进行汇总,如得出总结或结论。 |
+| [deduplicator](#deduplicator) | 10 | Detects and removes duplicate samples. 识别、删除重复样本。 |
+| [filter](#filter) | 44 | Filters out low-quality samples. 过滤低质量样本。 |
+| [formatter](#formatter) | 9 | Discovers, loads, and canonicalizes source data. 发现、加载、规范化原始数据。 |
+| [grouper](#grouper) | 3 | Group samples to batched samples. 将样本分组,每一组组成一个批量样本。 |
+| [mapper](#mapper) | 71 | Edits and transforms samples. 对数据样本进行编辑和转换。 |
+| [selector](#selector) | 5 | Selects top samples based on ranking. 基于排序选取高质量样本。 |
+
+All the specific operators are listed below, each featured with several capability tags.
+下面列出所有具体算子,每种算子都通过多个标签来注明其主要功能。
* Modality Tags
- - : specific to text
- - : specific to images
- - : specific to audios
- - : specific to videos
- - : specific to multimodal
-* Language Tags
- - : English
- - : Chinese
+ - : process text data specifically. 专用于处理文本。
+ - : process image data specifically. 专用于处理图像。
+ - : process audio data specifically. 专用于处理音频。
+ - : process video data specifically. 专用于处理视频。
+ - : process multimodal data. 用于处理多模态数据。
* Resource Tags
- - : only requires CPU resource (default)
- - : requires GPU/CUDA resource as well
-
-
-## Formatter
-
-| Operator | Tags | Description | Source code | Unit tests |
-|-------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------|----------------------------------------------------|----------------------------------------------------|
-| local_formatter |    | Prepares datasets from local files | [code](../data_juicer/format/formatter.py) | [tests](../tests/format/test_unify_format.py) |
-| remote_formatter |    | Prepares datasets from remote (e.g., HuggingFace) | [code](../data_juicer/format/formatter.py) | [tests](../tests/format/test_unify_format.py) |
-| csv_formatter |    | Prepares local `.csv` files | [code](../data_juicer/format/csv_formatter.py) | [tests](../tests/format/test_csv_formatter.py) |
-| tsv_formatter |    | Prepares local `.tsv` files | [code](../data_juicer/format/tsv_formatter.py) | [tests](../tests/format/test_tsv_formatter.py) |
-| json_formatter |    | Prepares local `.json`, `.jsonl`, `.jsonl.zst` files | [code](../data_juicer/format/json_formatter.py) | - |
-| parquet_formatter |    | Prepares local `.parquet` files | [code](../data_juicer/format/parquet_formatter.py) | [tests](../tests/format/test_parquet_formatter.py) |
-| text_formatter |    | Prepares other local text files ([complete list](../data_juicer/format/text_formatter.py#L63,73)) | [code](../data_juicer/format/text_formatter.py) | - |
-| empty_formatter |  | Prepares an empty dataset | [code](../data_juicer/format/empty_formatter.py) | [tests](../tests/format/test_empty_formatter.py) |
-| mixture_formatter |    | Handles a mixture of all the supported local file types | [code](../data_juicer/format/mixture_formatter.py) | [tests](../tests/format/test_mixture_formatter.py) |
-
-## Mapper
-
-| Operator | Tags | Description | Source code | Unit tests |
-|------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------|------------------------------------------------------------------------------------|
-| audio_ffmpeg_wrapped_mapper |  | Simple wrapper to run a FFmpeg audio filter | [code](../data_juicer/ops/mapper/audio_ffmpeg_wrapped_mapper.py) | [tests](../tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py) |
-| calibrate_qa_mapper |     | Calibrate question-answer pairs based on reference text | [code](../data_juicer/ops/mapper/calibrate_qa_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_qa_mapper.py) |
-| calibrate_query_mapper |     | Calibrate query in question-answer pairs based on reference text | [code](../data_juicer/ops/mapper/calibrate_query_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_query_mapper.py) |
-| calibrate_response_mapper |     | Calibrate response in question-answer pairs based on reference text | [code](../data_juicer/ops/mapper/calibrate_response_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_response_mapper.py) |
-| chinese_convert_mapper |    | Converts Chinese between Traditional Chinese, Simplified Chinese and Japanese Kanji (by [opencc](https://github.com/BYVoid/OpenCC)) | [code](../data_juicer/ops/mapper/chinese_convert_mapper.py) | [tests](../tests/ops/mapper/test_chinese_convert_mapper.py) |
-| clean_copyright_mapper |     | Removes copyright notice at the beginning of code files (must contain the word *copyright*) | [code](../data_juicer/ops/mapper/clean_copyright_mapper.py) | [tests](../tests/ops/mapper/test_clean_copyright_mapper.py) |
-| clean_email_mapper |     | Removes email information | [code](../data_juicer/ops/mapper/clean_email_mapper.py) | [tests](../tests/ops/mapper/test_clean_email_mapper.py) |
-| clean_html_mapper |     | Removes HTML tags and returns plain text of all the nodes | [code](../data_juicer/ops/mapper/clean_html_mapper.py) | [tests](../tests/ops/mapper/test_clean_html_mapper.py) |
-| clean_ip_mapper |     | Removes IP addresses | [code](../data_juicer/ops/mapper/clean_ip_mapper.py) | [tests](../tests/ops/mapper/test_clean_ip_mapper.py) |
-| clean_links_mapper |      | Removes links, such as those starting with http or ftp | [code](../data_juicer/ops/mapper/clean_links_mapper.py) | [tests](../tests/ops/mapper/test_clean_links_mapper.py) |
-| dialog_intent_detection_mapper |     | Mapper to generate user's intent labels in dialog. | [code](../data_juicer/ops/mapper/dialog_intent_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_intent_detection_mapper.py) |
-| dialog_sentiment_detection_mapper |     | Mapper to generate user's sentiment labels in dialog. | [code](../data_juicer/ops/mapper/dialog_sentiment_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_sentiment_detection_mapper.py) |
-| dialog_sentiment_intensity_mapper |     | Mapper to predict user's sentiment intensity (from -5 to 5 in default prompt) in dialog. | [code](../data_juicer/ops/mapper/dialog_sentiment_intensity_mapper.py) | [tests](../tests/ops/mapper/test_dialog_sentiment_intensity_mapper.py) |
-| dialog_topic_detection_mapper |     | Mapper to generate user's topic labels in dialog. | [code](../data_juicer/ops/mapper/dialog_topic_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_topic_detection_mapper.py) |
-| expand_macro_mapper |     | Expands macros usually defined at the top of TeX documents | [code](../data_juicer/ops/mapper/expand_macro_mapper.py) | [tests](../tests/ops/mapper/test_expand_macro_mapper.py) |
-| extract_entity_attribute_mapper |     | Extract attributes for given entities from the text. | [code](../data_juicer/ops/mapper/extract_entity_attribute_mapper.py) | [tests](../tests/ops/mapper/test_extract_entity_attribute_mapper.py) |
-| extract_entity_relation_mapper |     | Extract entities and relations in the text for knowledge graph. | [code](../data_juicer/ops/mapper/extract_entity_relation_mapper.py) | [tests](../tests/ops/mapper/test_extract_entity_relation_mapper.py) |
-| extract_event_mapper |     | Extract events and relevant characters in the text. | [code](../data_juicer/ops/mapper/extract_event_mapper.py) | [tests](../tests/ops/mapper/test_extract_event_mapper.py) |
-| extract_keyword_mapper |     | Generate keywords for the text. | [code](../data_juicer/ops/mapper/extract_keyword_mapper.py) | [tests](../tests/ops/mapper/test_extract_keyword_mapper.py) |
-| extract_nickname_mapper |     | Extract nickname relationship in the text. | [code](../data_juicer/ops/mapper/extract_nickname_mapper.py) | [tests](../tests/ops/mapper/test_extract_nickname_mapper.py) |
-| extract_support_text_mapper |     | Extract support sub text for a summary. | [code](../data_juicer/ops/mapper/extract_support_text_mapper.py) | [tests](../tests/ops/mapper/test_extract_support_text_mapper.py) |
-| fix_unicode_mapper |     | Fixes broken Unicodes (by [ftfy](https://ftfy.readthedocs.io/)) | [code](../data_juicer/ops/mapper/fix_unicode_mapper.py) | [tests](../tests/ops/mapper/test_fix_unicode_mapper.py) |
-| generate_qa_from_examples_mapper |      | Generate question and answer pairs based on examples. | [code](../data_juicer/ops/mapper/generate_qa_from_examples_mapper.py) | [tests](../tests/ops/mapper/test_generate_qa_from_examples_mapper.py) |
-| generate_qa_from_text_mapper |      | Generate question and answer pairs from text. | [code](../data_juicer/ops/mapper/generate_qa_from_text_mapper.py) | [tests](../tests/ops/mapper/test_generate_qa_from_text_mapper.py) |
-| image_blur_mapper |  | Blur images | [code](../data_juicer/ops/mapper/image_blur_mapper.py) | [tests](../tests/ops/mapper/test_image_blur_mapper.py) |
-| image_captioning_from_gpt4v_mapper |  | generate samples whose texts are generated based on gpt-4-visison and the image | [code](../data_juicer/ops/mapper/image_captioning_from_gpt4v_mapper.py) | - |
-| image_captioning_mapper |   | generate samples whose captions are generated based on another model (such as blip2) and the figure within the original sample | [code](../data_juicer/ops/mapper/image_captioning_mapper.py) | [tests](../tests/ops/mapper/test_image_captioning_mapper.py) |
-| image_diffusion_mapper |   | Generate and augment images by stable diffusion model | [code](../data_juicer/ops/mapper/image_diffusion_mapper.py) | [tests](../tests/ops/mapper/test_image_diffusion_mapper.py) |
-| image_face_blur_mapper |  | Blur faces detected in images | [code](../data_juicer/ops/mapper/image_face_blur_mapper.py) | [tests](../tests/ops/mapper/test_image_face_blur_mapper.py) |
-| image_tagging_mapper |   | Mapper to generate image tags from the input images. | [code](../data_juicer/ops/mapper/image_tagging_mapper.py) | [tests](../tests/ops/mapper/test_image_tagging_mapper.py) |
-| nlpaug_en_mapper |    | Simply augments texts in English based on the `nlpaug` library | [code](../data_juicer/ops/mapper/nlpaug_en_mapper.py) | [tests](../tests/ops/mapper/test_nlpaug_en_mapper.py) |
-| nlpcda_zh_mapper |    | Simply augments texts in Chinese based on the `nlpcda` library | [code](../data_juicer/ops/mapper/nlpcda_zh_mapper.py) | [tests](../tests/ops/mapper/test_nlpcda_zh_mapper.py) |
-| optimize_qa_mapper |      | Optimize both the query and response in question-answering samples. | [code](../data_juicer/ops/mapper/optimize_qa_mapper.py) | [tests](../tests/ops/mapper/test_optimize_qa_mapper.py) |
-| optimize_query_mapper |      | Optimize the query in question-answering samples. | [code](../data_juicer/ops/mapper/optimize_query_mapper.py) | [tests](../tests/ops/mapper/test_optimize_query_mapper.py) |
-| optimize_response_mapper |      | Optimize the response in question-answering samples. | [code](../data_juicer/ops/mapper/optimize_response_mapper.py) | [tests](../tests/ops/mapper/test_optimize_response_mapper.py) |
-| pair_preference_mapper |     | Construct paired preference samples. | [code](../data_juicer/ops/mapper/pair_preference_mapper.py) | [tests](../tests/ops/mapper/test_pair_preference_mapper.py) |
-| punctuation_normalization_mapper |     | Normalizes various Unicode punctuations to their ASCII equivalents | [code](../data_juicer/ops/mapper/punctuation_normalization_mapper.py) | [tests](../tests/ops/mapper/test_punctuation_normalization_mapper.py) |
-| python_file_mapper |     | Executing Python function defined in a file | [code](../data_juicer/ops/mapper/python_file_mapper.py) | [tests](../tests/ops/mapper/test_python_file_mapper.py) |
-| python_lambda_mapper |     | Executing Python lambda function on data samples | [code](../data_juicer/ops/mapper/python_lambda_mapper.py) | [tests](../tests/ops/mapper/test_python_lambda_mapper.py) |
-| query_intent_detection_mapper |     | Mapper to predict user's intent label in query. | [code](../data_juicer/ops/mapper/query_intent_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_intent_detection_mapper.py) |
-| query_sentiment_detection_mapper |     | Mapper to predict user's sentiment label ('negative', 'neutral' and 'positive') in query. | [code](../data_juicer/ops/mapper/query_sentiment_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_sentiment_detection_mapper.py) |
-| query_topic_detection_mapper |     | Mapper to predict user's topic label in query. | [code](../data_juicer/ops/mapper/query_topic_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_topic_detection_mapper.py) |
-| relation_identity_mapper |     | Identify relation between two entity in the text. | [code](../data_juicer/ops/mapper/relation_identity_mapper.py) | [tests](../tests/ops/mapper/test_relation_identity_mapper.py) |
-| remove_bibliography_mapper |     | Removes the bibliography of TeX documents | [code](../data_juicer/ops/mapper/remove_bibliography_mapper.py) | [tests](../tests/ops/mapper/test_remove_bibliography_mapper.py) |
-| remove_comments_mapper |     | Removes the comments of TeX documents | [code](../data_juicer/ops/mapper/remove_comments_mapper.py) | [tests](../tests/ops/mapper/test_remove_comments_mapper.py) |
-| remove_header_mapper |     | Removes the running headers of TeX documents, e.g., titles, chapter or section numbers/names | [code](../data_juicer/ops/mapper/remove_header_mapper.py) | [tests](../tests/ops/mapper/test_remove_header_mapper.py) |
-| remove_long_words_mapper |     | Removes words with length outside the specified range | [code](../data_juicer/ops/mapper/remove_long_words_mapper.py) | [tests](../tests/ops/mapper/test_remove_long_words_mapper.py) |
-| remove_non_chinese_character_mapper |     | Remove non Chinese character in text samples. | [code](../data_juicer/ops/mapper/remove_non_chinese_character_mapper.py) | [tests](../tests/ops/mapper/test_remove_non_chinese_character_mapper.py) |
-| remove_repeat_sentences_mapper |     | Remove repeat sentences in text samples. | [code](../data_juicer/ops/mapper/remove_repeat_sentences_mapper.py) | [tests](../tests/ops/mapper/test_remove_repeat_sentences_mapper.py) |
-| remove_specific_chars_mapper |     | Removes any user-specified characters or substrings | [code](../data_juicer/ops/mapper/remove_specific_chars_mapper.py) | [tests](../tests/ops/mapper/test_remove_specific_chars_mapper.py) |
-| remove_table_text_mapper |     | Detects and removes possible table contents (:warning: relies on regular expression matching and thus fragile) | [code](../data_juicer/ops/mapper/remove_table_text_mapper.py) | [tests](../tests/ops/mapper/test_remove_table_text_mapper.py) |
-| remove_words_with_incorrect_ substrings_mapper |     | Removes words containing specified substrings | [code](../data_juicer/ops/mapper/remove_words_with_incorrect_substrings_mapper.py) | [tests](../tests/ops/mapper/test_remove_words_with_incorrect_substrings_mapper.py) |
-| replace_content_mapper |     | Replace all content in the text that matches a specific regular expression pattern with a designated replacement string | [code](../data_juicer/ops/mapper/replace_content_mapper.py) | [tests](../tests/ops/mapper/test_replace_content_mapper.py) |
-| sentence_split_mapper |    | Splits and reorganizes sentences according to semantics | [code](../data_juicer/ops/mapper/sentence_split_mapper.py) | [tests](../tests/ops/mapper/test_sentence_split_mapper.py) |
-| text_chunk_mapper |     | Split input text to chunks. | [code](../data_juicer/ops/mapper/text_chunk_mapper.py) | [tests](../tests/ops/mapper/test_text_chunk_mapper.py) |
-| video_captioning_from_audio_mapper |   | Caption a video according to its audio streams based on Qwen-Audio model | [code](../data_juicer/ops/mapper/video_captioning_from_audio_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_audio_mapper.py) |
-| video_captioning_from_frames_mapper |   | generate samples whose captions are generated based on an image-to-text model and sampled video frames. Captions from different frames will be concatenated to a single string | [code](../data_juicer/ops/mapper/video_captioning_from_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_frames_mapper.py) |
-| video_captioning_from_summarizer_mapper |   | Generate video captions by summarizing several kinds of generated texts (captions from video/audio/frames, tags from audio/frames, ...) | [code](../data_juicer/ops/mapper/video_captioning_from_summarizer_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_summarizer_mapper.py) |
-| video_captioning_from_video_mapper |   | generate samples whose captions are generated based on another model (video-blip) and sampled video frame within the original sample | [code](../data_juicer/ops/mapper/video_captioning_from_video_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_video_mapper.py) |
-| video_extract_frames_mapper |   | extract frames from video files according to specified methods | [code](../data_juicer/ops/mapper/video_extract_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_extract_frames_mapper.py) |
-| video_face_blur_mapper |  | Blur faces detected in videos | [code](../data_juicer/ops/mapper/video_face_blur_mapper.py) | [tests](../tests/ops/mapper/test_video_face_blur_mapper.py) |
-| video_ffmpeg_wrapped_mapper |  | Simple wrapper to run a FFmpeg video filter | [code](../data_juicer/ops/mapper/video_ffmpeg_wrapped_mapper.py) | [tests](../tests/ops/mapper/test_video_ffmpeg_wrapped_mapper.py) |
-| video_remove_watermark_mapper |  | Remove the watermarks in videos given regions | [code](../data_juicer/ops/mapper/video_remove_watermark_mapper.py) | [tests](../tests/ops/mapper/test_video_remove_watermark_mapper.py) |
-| video_resize_aspect_ratio_mapper |  | Resize video aspect ratio to a specified range | [code](../data_juicer/ops/mapper/video_resize_aspect_ratio_mapper.py) | [tests](../tests/ops/mapper/test_video_resize_aspect_ratio_mapper.py) |
-| video_resize_resolution_mapper |  | Map videos to ones with given resolution range | [code](../data_juicer/ops/mapper/video_resize_resolution_mapper.py) | [tests](../tests/ops/mapper/test_video_resize_resolution_mapper.py) |
-| video_split_by_duration_mapper |  | Mapper to split video by duration | [code](../data_juicer/ops/mapper/video_split_by_duration_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_duration_mapper.py) |
-| video_split_by_key_frame_mapper |  | Mapper to split video by key frame | [code](../data_juicer/ops/mapper/video_split_by_key_frame_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_key_frame_mapper.py) |
-| video_split_by_scene_mapper |  | Split videos into scene clips | [code](../data_juicer/ops/mapper/video_split_by_scene_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_scene_mapper.py) |
-| video_tagging_from_audio_mapper |   | Mapper to generate video tags from audio streams extracted from the video. | [code](../data_juicer/ops/mapper/video_tagging_from_audio_mapper.py) | [tests](../tests/ops/mapper/test_video_tagging_from_audio_mapper.py) |
-| video_tagging_from_frames_mapper |   | Mapper to generate video tags from frames extracted from the video. | [code](../data_juicer/ops/mapper/video_tagging_from_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_tagging_from_frames_mapper.py) |
-| whitespace_normalization_mapper |     | Normalizes various Unicode whitespaces to the normal ASCII space (U+0020) | [code](../data_juicer/ops/mapper/whitespace_normalization_mapper.py) | [tests](../tests/ops/mapper/test_whitespace_normalization_mapper.py) |
-
-## Filter
-
-| Operator | Tags | Description | Source code | Unit tests |
-|-------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------|--------------------------------------------------------------------------|
-| alphanumeric_filter |     | Keeps samples with alphanumeric ratio within the specified range | [code](../data_juicer/ops/filter/alphanumeric_filter.py) | [tests](../tests/ops/filter/test_alphanumeric_filter.py) |
-| audio_duration_filter |  | Keep data samples whose audios' durations are within a specified range | [code](../data_juicer/ops/filter/audio_duration_filter.py) | [tests](../tests/ops/filter/test_audio_duration_filter.py) |
-| audio_nmf_snr_filter |  | Keep data samples whose audios' Signal-to-Noise Ratios (SNRs, computed based on Non-Negative Matrix Factorization, NMF) are within a specified range | [code](../data_juicer/ops/filter/audio_nmf_snr_filter.py) | [tests](../tests/ops/filter/test_audio_nmf_snr_filter.py) |
-| audio_size_filter |  | Keep data samples whose audios' sizes are within a specified range | [code](../data_juicer/ops/filter/audio_size_filter.py) | [tests](../tests/ops/filter/test_audio_size_filter.py) |
-| average_line_length_filter |     | Keeps samples with average line length within the specified range | [code](../data_juicer/ops/filter/average_line_length_filter.py) | [tests](../tests/ops/filter/test_average_line_length_filter.py) |
-| character_repetition_filter |     | Keeps samples with char-level n-gram repetition ratio within the specified range | [code](../data_juicer/ops/filter/character_repetition_filter.py) | [tests](../tests/ops/filter/test_character_repetition_filter.py) |
-| flagged_words_filter |     | Keeps samples with flagged-word ratio below the specified threshold | [code](../data_juicer/ops/filter/flagged_words_filter.py) | [tests](../tests/ops/filter/test_flagged_words_filter.py) |
-| image_aesthetics_filter |   | Keeps samples containing images whose aesthetics scores are within the specified range | [code](../data_juicer/ops/filter/image_aesthetics_filter.py) | [tests](../tests/ops/filter/test_image_aesthetics_filter.py) |
-| image_aspect_ratio_filter |  | Keeps samples containing images with aspect ratios within the specified range | [code](../data_juicer/ops/filter/image_aspect_ratio_filter.py) | [tests](../tests/ops/filter/test_image_aspect_ratio_filter.py) |
-| image_face_count_filter |  | Keeps samples containing images with face counts within the specified range | [code](../data_juicer/ops/filter/image_face_count_filter.py) | [tests](../tests/ops/filter/test_image_face_count_filter.py) |
-| image_face_ratio_filter |  | Keeps samples containing images with face area ratios within the specified range | [code](../data_juicer/ops/filter/image_face_ratio_filter.py) | [tests](../tests/ops/filter/test_image_face_ratio_filter.py) |
-| image_nsfw_filter |   | Keeps samples containing images with NSFW scores below the threshold | [code](../data_juicer/ops/filter/image_nsfw_filter.py) | [tests](../tests/ops/filter/test_image_nsfw_filter.py) |
-| image_pair_similarity_filter |   | Keeps image pairs with image feature cosine similarity within the specified range based on a CLIP model | [code](../data_juicer/ops/filter/image_pair_similarity_filter.py) | [tests](../tests/ops/filter/test_image_pair_similarity_filter.py) |
-| image_shape_filter |  | Keeps samples containing images with widths and heights within the specified range | [code](../data_juicer/ops/filter/image_shape_filter.py) | [tests](../tests/ops/filter/test_image_shape_filter.py) |
-| image_size_filter |  | Keeps samples containing images whose size in bytes are within the specified range | [code](../data_juicer/ops/filter/image_size_filter.py) | [tests](../tests/ops/filter/test_image_size_filter.py) |
-| image_text_matching_filter |   | Keeps samples with image-text classification matching score within the specified range based on a BLIP model | [code](../data_juicer/ops/filter/image_text_matching_filter.py) | [tests](../tests/ops/filter/test_image_text_matching_filter.py) |
-| image_text_similarity_filter |   | Keeps samples with image-text feature cosine similarity within the specified range based on a CLIP model | [code](../data_juicer/ops/filter/image_text_similarity_filter.py) | [tests](../tests/ops/filter/test_image_text_similarity_filter.py) |
-| image_watermark_filter |   | Keeps samples containing images with predicted watermark probabilities below the threshold | [code](../data_juicer/ops/filter/image_watermark_filter.py) | [tests](../tests/ops/filter/test_image_watermark_filter.py) |
-| language_id_score_filter |     | Keeps samples of the specified language, judged by a predicted confidence score | [code](../data_juicer/ops/filter/language_id_score_filter.py) | [tests](../tests/ops/filter/test_language_id_score_filter.py) |
-| maximum_line_length_filter |     | Keeps samples with maximum line length within the specified range | [code](../data_juicer/ops/filter/maximum_line_length_filter.py) | [tests](../tests/ops/filter/test_maximum_line_length_filter.py) |
-| perplexity_filter |     | Keeps samples with perplexity score below the specified threshold | [code](../data_juicer/ops/filter/perplexity_filter.py) | [tests](../tests/ops/filter/test_perplexity_filter.py) |
-| phrase_grounding_recall_filter |   | Keeps samples whose locating recalls of phrases extracted from text in the images are within a specified range | [code](../data_juicer/ops/filter/phrase_grounding_recall_filter.py) | [tests](../tests/ops/filter/test_phrase_grounding_recall_filter.py) |
-| special_characters_filter |     | Keeps samples with special-char ratio within the specified range | [code](../data_juicer/ops/filter/special_characters_filter.py) | [tests](../tests/ops/filter/test_special_characters_filter.py) |
-| specified_field_filter |     | Filters samples based on field, with value lies in the specified targets | [code](../data_juicer/ops/filter/specified_field_filter.py) | [tests](../tests/ops/filter/test_specified_field_filter.py) |
-| specified_numeric_field_filter |     | Filters samples based on field, with value lies in the specified range (for numeric types) | [code](../data_juicer/ops/filter/specified_numeric_field_filter.py) | [tests](../tests/ops/filter/test_specified_numeric_field_filter.py) |
-| stopwords_filter |     | Keeps samples with stopword ratio above the specified threshold | [code](../data_juicer/ops/filter/stopwords_filter.py) | [tests](../tests/ops/filter/test_stopwords_filter.py) |
-| suffix_filter |    | Keeps samples with specified suffixes | [code](../data_juicer/ops/filter/suffix_filter.py) | [tests](../tests/ops/filter/test_suffix_filter.py) |
-| text_action_filter |     | Keeps samples containing action verbs in their texts | [code](../data_juicer/ops/filter/text_action_filter.py) | [tests](../tests/ops/filter/test_text_action_filter.py) |
-| text_entity_dependency_filter |     | Keeps samples containing dependency edges for an entity in the dependency tree of the texts | [code](../data_juicer/ops/filter/text_entity_dependency_filter.py) | [tests](../tests/ops/filter/test_text_entity_dependency_filter.py) |
-| text_length_filter |     | Keeps samples with total text length within the specified range | [code](../data_juicer/ops/filter/text_length_filter.py) | [tests](../tests/ops/filter/test_text_length_filter.py) |
-| token_num_filter |      | Keeps samples with token count within the specified range | [code](../data_juicer/ops/filter/token_num_filter.py) | [tests](../tests/ops/filter/test_token_num_filter.py) |
-| video_aesthetics_filter |   | Keeps samples whose specified frames have aesthetics scores within the specified range | [code](../data_juicer/ops/filter/video_aesthetics_filter.py) | [tests](../tests/ops/filter/test_video_aesthetics_filter.py) |
-| video_aspect_ratio_filter |  | Keeps samples containing videos with aspect ratios within the specified range | [code](../data_juicer/ops/filter/video_aspect_ratio_filter.py) | [tests](../tests/ops/filter/test_video_aspect_ratio_filter.py) |
-| video_duration_filter |  | Keep data samples whose videos' durations are within a specified range | [code](../data_juicer/ops/filter/video_duration_filter.py) | [tests](../tests/ops/filter/test_video_duration_filter.py) |
-| video_frames_text_similarity_filter |   | Keep data samples whose similarities between sampled video frame images and text are within a specific range | [code](../data_juicer/ops/filter/video_frames_text_similarity_filter.py) | [tests](../tests/ops/filter/test_video_frames_text_similarity_filter.py) |
-| video_motion_score_filter |  | Keep samples with video motion scores within a specific range | [code](../data_juicer/ops/filter/video_motion_score_filter.py) | [tests](../tests/ops/filter/test_video_motion_score_filter.py) |
-| video_motion_score_raft_filter |  | Keep samples with video motion scores (based on RAFT model) within a specific range | [code](../data_juicer/ops/filter/video_motion_score_raft_filter.py) | [tests](../tests/ops/filter/test_video_motion_score_raft_filter.py) |
-| video_nsfw_filter |   | Keeps samples containing videos with NSFW scores below the threshold | [code](../data_juicer/ops/filter/video_nsfw_filter.py) | [tests](../tests/ops/filter/test_video_nsfw_filter.py) |
-| video_ocr_area_ratio_filter |   | Keep data samples whose detected text area ratios for specified frames in the video are within a specified range | [code](../data_juicer/ops/filter/video_ocr_area_ratio_filter.py) | [tests](../tests/ops/filter/test_video_ocr_area_ratio_filter.py) |
-| video_resolution_filter |  | Keeps samples containing videos with horizontal and vertical resolutions within the specified range | [code](../data_juicer/ops/filter/video_resolution_filter.py) | [tests](../tests/ops/filter/test_video_resolution_filter.py) |
-| video_watermark_filter |   | Keeps samples containing videos with predicted watermark probabilities below the threshold | [code](../data_juicer/ops/filter/video_watermark_filter.py) | [tests](../tests/ops/filter/test_video_watermark_filter.py) |
-| video_tagging_from_frames_filter |   | Keep samples containing videos with given tags | [code](../data_juicer/ops/filter/video_tagging_from_frames_filter.py) | [tests](../tests/ops/filter/test_video_tagging_from_frames_filter.py) |
-| words_num_filter |     | Keeps samples with word count within the specified range | [code](../data_juicer/ops/filter/words_num_filter.py) | [tests](../tests/ops/filter/test_words_num_filter.py) |
-| word_repetition_filter |     | Keeps samples with word-level n-gram repetition ratio within the specified range | [code](../data_juicer/ops/filter/word_repetition_filter.py) | [tests](../tests/ops/filter/test_word_repetition_filter.py) |
-
-## Deduplicator
-
-| Operator | Tags | Description | Source code | Unit tests |
-|-------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------|--------------------------------------------------------------------------|
-| document_deduplicator |     | Deduplicates samples at document-level by comparing MD5 hash | [code](../data_juicer/ops/deduplicator/document_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_deduplicator.py) |
-| document_minhash_deduplicator |     | Deduplicates samples at document-level using MinHashLSH | [code](../data_juicer/ops/deduplicator/document_minhash_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_minhash_deduplicator.py) |
-| document_simhash_deduplicator |     | Deduplicates samples at document-level using SimHash | [code](../data_juicer/ops/deduplicator/document_simhash_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_simhash_deduplicator.py) |
-| image_deduplicator |  | Deduplicates samples at document-level using exact matching of images between documents | [code](../data_juicer/ops/deduplicator/image_deduplicator.py) | [tests](../tests/ops/deduplicator/test_image_deduplicator.py) |
-| video_deduplicator |  | Deduplicates samples at document-level using exact matching of videos between documents | [code](../data_juicer/ops/deduplicator/video_deduplicator.py) | [tests](../tests/ops/deduplicator/test_video_deduplicator.py) |
-| ray_bts_minhash_deduplicator |     | Deduplicates samples at document-level using MinHashLSH based on Ray | [code](../data_juicer/ops/deduplicator/ray_bts_minhash_deduplicator.py) | - |
-| ray_document_deduplicator |     | Deduplicates samples at document-level by comparing MD5 hash on ray | [code](../data_juicer/ops/deduplicator/ray_document_deduplicator.py) | - |
-| ray_image_deduplicator |  | Deduplicates samples at document-level using exact matching of images between documents on ray | [code](../data_juicer/ops/deduplicator/ray_image_deduplicator.py) | - |
-| ray_video_deduplicator |  | Deduplicates samples at document-level using exact matching of videos between documents on ray | [code](../data_juicer/ops/deduplicator/ray_video_deduplicator.py) | - |
-
-## Selector
-
-| Operator | Tags | Description | Source code | Unit tests |
-|------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|-------------------------------------------------------------------------------|---------------------------------------------------------------------------|
-| frequency_specified_field_selector |    | Selects top samples by comparing the frequency of the specified field | [code](../data_juicer/ops/selector/frequency_specified_field_selector.py) | [tests](../tests/ops/selector/test_frequency_specified_field_selector.py) |
-| random_selector |    | Selects samples randomly | [code](../data_juicer/ops/selector/random_selector.py) | [tests](../tests/ops/selector/test_random_selector.py) |
-| range_specified_field_selector |    | Selects samples within a specified range by comparing the values of the specified field | [code](../data_juicer/ops/selector/range_specified_field_selector.py) | [tests](../tests/ops/selector/test_range_specified_field_selector.py) |
-| tags_specified_field_selector |    | Select samples based on the tags of specified
- field. | [code](../data_juicer/ops/selector/tags_specified_field_selector.py) | [tests](../tests/ops/selector/test_tags_specified_field_selector.py) |
-| topk_specified_field_selector |    | Selects top samples by comparing the values of the specified field | [code](../data_juicer/ops/selector/topk_specified_field_selector.py) | [tests](../tests/ops/selector/test_topk_specified_field_selector.py) |
-
-## Grouper
-
-| Operator | Tags | Description | Source code | Unit tests |
-|------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|-------------------------------------------------------------------------------|---------------------------------------------------------------------------|
-| naive_grouper |     | Group all samples to one batched sample. | [code](../data_juicer/ops/grouper/naive_grouper.py) | [tests](../tests/ops/grouper/test_naive_grouper.py) |
-| naive_reverse_grouper |     | Split batched samples to samples. | [code](../data_juicer/ops/grouper/naive_reverse_grouper.py) | [tests](../tests/ops/grouper/test_naive_reverse_grouper.py) |
-| key_value_grouper |     | Group samples to batched samples according values in given keys. | [code](../data_juicer/ops/grouper/key_value_grouper.py) | [tests](../tests/ops/grouper/test_key_value_grouper.py) |
-
-## Aggregator
-
-| Operator | Tags | Description | Source code | Unit tests |
-|------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|-------------------------------------------------------------------------------|---------------------------------------------------------------------------|
-| entity_attribute_aggregator |     | Return conclusion of the given entity's attribute from some docs. | [code](../data_juicer/ops/aggregator/entity_attribute_aggregator.py) | [tests](../tests/ops/aggregator/test_entity_attribute_aggregator.py) |
-| meta_tags_aggregator |     | Merge similar meta tags to one tag. | [code](../data_juicer/ops/aggregator/meta_tags_aggregator.py) | [tests](../tests/ops/aggregator/test_meta_tags_aggregator.py) |
-| most_relavant_entities_aggregator |     | Extract entities closely related to a given entity from some texts, and sort them in descending order of importance. | [code](../data_juicer/ops/aggregator/most_relavant_entities_aggregator.py) | [tests](../tests/ops/aggregator/test_most_relavant_entities_aggregator.py) |
-| nested_aggregator |     | Considering the limitation of input length, nested aggregate contents for each given number of samples. | [code](../data_juicer/ops/aggregator/nested_aggregator.py) | [tests](../tests/ops/aggregator/test_nested_aggregator.py) |
-
-
-## Contributing
-We welcome contributions of adding new operators. Please refer to [How-to Guide for Developers](DeveloperGuide.md).
+ - : only requires CPU resource. 只需要 CPU 资源。
+ - : requires GPU/CUDA resource as well. 额外需要 GPU/CUDA 资源。
+* Usability Tags
+ - : alpha version OP. Only the basic OP implementations are finished. 表示 alpha 版本算子。只完成了基础的算子实现。
+ - : beta version OP. Based on the alpha version, unittests for this OP are added as well. 表示 beta 版本算子。基于 alpha 版本,添加了算子的单元测试。
+ - : stable version OP. Based on the beta version, OP optimizations related to DJ (e.g. model management, batched processing, OP fusion, ...) are added to this OP. 表示 stable 版本算子。基于 beta 版本,完善了DJ相关的算子优化项(如模型管理,批处理,算子融合等)。
+* Modal Tags
+ - : equipped with API-based models. (e.g. ChatGPT, GPT-4o). 支持基于 API 调用模型(如 ChatGPT,GPT-4o)。
+ - : equipped with models supported by vLLM. 支持基于 vLLM 进行模型推理。
+ - : equipped with models from HuggingFace Hub. 支持来自于 HuggingFace Hub 的模型。
+
+## aggregator
+
+| Operator 算子 | Tags 标签 | Description 描述 | Source code 源码 | Unit tests 单测样例 |
+|----------|------|-------------|-------------|------------|
+| entity_attribute_aggregator |    | Return conclusion of the given entity's attribute from some docs. 从某些文档返回给定实体属性的结论。 | [code](../data_juicer/ops/aggregator/entity_attribute_aggregator.py) | [tests](../tests/ops/aggregator/test_entity_attribute_aggregator.py) |
+| meta_tags_aggregator |    | Merge similar meta tags to one tag. 将相似的元标记合并到一个标记中。 | [code](../data_juicer/ops/aggregator/meta_tags_aggregator.py) | [tests](../tests/ops/aggregator/test_meta_tags_aggregator.py) |
+| most_relavant_entities_aggregator |    | Extract entities closely related to a given entity from some texts, and sort them in descending order of importance. 从一些文本中提取与给定实体密切相关的实体,并按重要性降序对它们进行排序。 | [code](../data_juicer/ops/aggregator/most_relavant_entities_aggregator.py) | [tests](../tests/ops/aggregator/test_most_relavant_entities_aggregator.py) |
+| nested_aggregator |     | Considering the limitation of input length, nested aggregate contents for each given number of samples. 考虑到输入长度的限制,每个给定数量的样本嵌套聚合内容。 | [code](../data_juicer/ops/aggregator/nested_aggregator.py) | [tests](../tests/ops/aggregator/test_nested_aggregator.py) |
+
+## deduplicator
+
+| Operator 算子 | Tags 标签 | Description 描述 | Source code 源码 | Unit tests 单测样例 |
+|----------|------|-------------|-------------|------------|
+| document_deduplicator |    | Deduplicator to deduplicate samples at document-level using exact matching. 重复数据删除器使用精确匹配在文档级别删除重复样本。 | [code](../data_juicer/ops/deduplicator/document_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_deduplicator.py) |
+| document_minhash_deduplicator |    | Deduplicator to deduplicate samples at document-level using MinHashLSH. Deduplicator 使用 MinHashLSH 在文档级别删除重复样本。 | [code](../data_juicer/ops/deduplicator/document_minhash_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_minhash_deduplicator.py) |
+| document_simhash_deduplicator |    | Deduplicator to deduplicate samples at document-level using SimHash. Deduplicator 使用 SimHash 在文档级别删除重复样本。 | [code](../data_juicer/ops/deduplicator/document_simhash_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_simhash_deduplicator.py) |
+| image_deduplicator |    | Deduplicator to deduplicate samples at document-level using exact matching of images between documents. 重复数据删除器使用文档之间图像的精确匹配来在文档级别删除重复样本。 | [code](../data_juicer/ops/deduplicator/image_deduplicator.py) | [tests](../tests/ops/deduplicator/test_image_deduplicator.py) |
+| ray_basic_deduplicator |   | Backend for deduplicator. 重复数据删除器的后端。 | [code](../data_juicer/ops/deduplicator/ray_basic_deduplicator.py) | - |
+| ray_bts_minhash_deduplicator |    | A distributed implementation of Union-Find with load balancing. 具有负载平衡功能的 Union-Find 的分布式实现。 | [code](../data_juicer/ops/deduplicator/ray_bts_minhash_deduplicator.py) | - |
+| ray_document_deduplicator |    | Deduplicator to deduplicate samples at document-level using exact matching. 重复数据删除器使用精确匹配在文档级别删除重复样本。 | [code](../data_juicer/ops/deduplicator/ray_document_deduplicator.py) | - |
+| ray_image_deduplicator |    | Deduplicator to deduplicate samples at document-level using exact matching of images between documents. 重复数据删除器使用文档之间图像的精确匹配来在文档级别删除重复样本。 | [code](../data_juicer/ops/deduplicator/ray_image_deduplicator.py) | - |
+| ray_video_deduplicator |    | Deduplicator to deduplicate samples at document-level using exact matching of videos between documents. 重复数据删除器使用文档之间视频的精确匹配来在文档级别删除重复样本。 | [code](../data_juicer/ops/deduplicator/ray_video_deduplicator.py) | - |
+| video_deduplicator |    | Deduplicator to deduplicate samples at document-level using exact matching of videos between documents. 重复数据删除器使用文档之间视频的精确匹配来在文档级别删除重复样本。 | [code](../data_juicer/ops/deduplicator/video_deduplicator.py) | [tests](../tests/ops/deduplicator/test_video_deduplicator.py) |
+
+## filter
+
+| Operator 算子 | Tags 标签 | Description 描述 | Source code 源码 | Unit tests 单测样例 |
+|----------|------|-------------|-------------|------------|
+| alphanumeric_filter |     | Filter to keep samples with alphabet/numeric ratio within a specific range. 过滤以将字母/数字比例保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/alphanumeric_filter.py) | [tests](../tests/ops/filter/test_alphanumeric_filter.py) |
+| audio_duration_filter |    | Keep data samples whose audios' durations are within a specified range. 保留音频持续时间在指定范围内的数据样本。 | [code](../data_juicer/ops/filter/audio_duration_filter.py) | [tests](../tests/ops/filter/test_audio_duration_filter.py) |
+| audio_nmf_snr_filter |    | Keep data samples whose audios' SNRs (computed based on NMF) are within a specified range. 保持音频信噪比(基于 NMF 计算)在指定范围内的数据样本。 | [code](../data_juicer/ops/filter/audio_nmf_snr_filter.py) | [tests](../tests/ops/filter/test_audio_nmf_snr_filter.py) |
+| audio_size_filter |    | Keep data samples whose audio size (in bytes/kb/MB/...) within a specific range. 将音频大小(以字节/kb/MB/...为单位)的数据样本保持在特定范围内。 | [code](../data_juicer/ops/filter/audio_size_filter.py) | [tests](../tests/ops/filter/test_audio_size_filter.py) |
+| average_line_length_filter |    | Filter to keep samples with average line length within a specific range. 过滤以将平均线长度保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/average_line_length_filter.py) | [tests](../tests/ops/filter/test_average_line_length_filter.py) |
+| character_repetition_filter |    | Filter to keep samples with char-level n-gram repetition ratio within a specific range. 过滤以将字符级 n-gram 重复率的样本保持在特定范围内。 | [code](../data_juicer/ops/filter/character_repetition_filter.py) | [tests](../tests/ops/filter/test_character_repetition_filter.py) |
+| flagged_words_filter |    | Filter to keep samples with flagged-word ratio less than a specific max value. 过滤以保留标记字比率小于特定最大值的样本。 | [code](../data_juicer/ops/filter/flagged_words_filter.py) | [tests](../tests/ops/filter/test_flagged_words_filter.py) |
+| image_aesthetics_filter |     | Filter to keep samples with aesthetics scores within a specific range. 过滤以将美学分数保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/image_aesthetics_filter.py) | [tests](../tests/ops/filter/test_image_aesthetics_filter.py) |
+| image_aspect_ratio_filter |    | Filter to keep samples with image aspect ratio within a specific range. 过滤以将图像长宽比保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/image_aspect_ratio_filter.py) | [tests](../tests/ops/filter/test_image_aspect_ratio_filter.py) |
+| image_face_count_filter |    | Filter to keep samples with the number of faces within a specific range. 过滤以保持样本的面数在特定范围内。 | [code](../data_juicer/ops/filter/image_face_count_filter.py) | [tests](../tests/ops/filter/test_image_face_count_filter.py) |
+| image_face_ratio_filter |    | Filter to keep samples with face area ratios within a specific range. 过滤以使样品的表面积比保持在特定范围内。 | [code](../data_juicer/ops/filter/image_face_ratio_filter.py) | [tests](../tests/ops/filter/test_image_face_ratio_filter.py) |
+| image_nsfw_filter |     | Filter to keep samples whose images have low nsfw scores. 过滤以保留图像具有低 nsfw 分数的样本。 | [code](../data_juicer/ops/filter/image_nsfw_filter.py) | [tests](../tests/ops/filter/test_image_nsfw_filter.py) |
+| image_pair_similarity_filter |     | Filter to keep image pairs with similarities between images within a specific range. 过滤以将图像之间的相似度保留在特定范围内。 | [code](../data_juicer/ops/filter/image_pair_similarity_filter.py) | [tests](../tests/ops/filter/test_image_pair_similarity_filter.py) |
+| image_shape_filter |    | Filter to keep samples with image shape (w, h) within specific ranges. 过滤以将图像形状(w,h)的样本保持在特定范围内。 | [code](../data_juicer/ops/filter/image_shape_filter.py) | [tests](../tests/ops/filter/test_image_shape_filter.py) |
+| image_size_filter |    | Keep data samples whose image size (in Bytes/KB/MB/...) within a specific range. 将图像大小(以字节/KB/MB/...为单位)的数据样本保持在特定范围内。 | [code](../data_juicer/ops/filter/image_size_filter.py) | [tests](../tests/ops/filter/test_image_size_filter.py) |
+| image_text_matching_filter |     | Filter to keep samples those matching score between image and text within a specific range. 过滤以使图像和文本之间的匹配分数保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/image_text_matching_filter.py) | [tests](../tests/ops/filter/test_image_text_matching_filter.py) |
+| image_text_similarity_filter |     | Filter to keep samples those similarities between image and text within a specific range. 过滤以将图像和文本之间的相似度保持在特定范围内。 | [code](../data_juicer/ops/filter/image_text_similarity_filter.py) | [tests](../tests/ops/filter/test_image_text_similarity_filter.py) |
+| image_watermark_filter |     | Filter to keep samples whose images have no watermark with high probability. 过滤以高概率保留图像无水印的样本。 | [code](../data_juicer/ops/filter/image_watermark_filter.py) | [tests](../tests/ops/filter/test_image_watermark_filter.py) |
+| language_id_score_filter |    | Filter to keep samples in a specific language with confidence score larger than a specific min value. 过滤以保留特定语言的样本,且置信度得分大于特定最小值。 | [code](../data_juicer/ops/filter/language_id_score_filter.py) | [tests](../tests/ops/filter/test_language_id_score_filter.py) |
+| maximum_line_length_filter |    | Filter to keep samples with maximum line length within a specific range. 过滤以将最大线长度的样本保持在特定范围内。 | [code](../data_juicer/ops/filter/maximum_line_length_filter.py) | [tests](../tests/ops/filter/test_maximum_line_length_filter.py) |
+| perplexity_filter |    | Filter to keep samples with perplexity score less than a specific max value. 过滤以保留困惑度分数小于特定最大值的样本。 | [code](../data_juicer/ops/filter/perplexity_filter.py) | [tests](../tests/ops/filter/test_perplexity_filter.py) |
+| phrase_grounding_recall_filter |     | Filter to keep samples whose locating recalls of phrases extracted from text in the images are within a specified range. 过滤以保持从图像文本中提取的短语的定位回忆在指定范围内的样本。 | [code](../data_juicer/ops/filter/phrase_grounding_recall_filter.py) | [tests](../tests/ops/filter/test_phrase_grounding_recall_filter.py) |
+| special_characters_filter |    | Filter to keep samples with special-char ratio within a specific range. 过滤以将特殊炭比例的样品保持在特定范围内。 | [code](../data_juicer/ops/filter/special_characters_filter.py) | [tests](../tests/ops/filter/test_special_characters_filter.py) |
+| specified_field_filter |   | Filter based on specified field information. 根据指定字段信息进行过滤。 | [code](../data_juicer/ops/filter/specified_field_filter.py) | [tests](../tests/ops/filter/test_specified_field_filter.py) |
+| specified_numeric_field_filter |   | Filter based on specified numeric field information. 根据指定的数字字段信息进行过滤。 | [code](../data_juicer/ops/filter/specified_numeric_field_filter.py) | [tests](../tests/ops/filter/test_specified_numeric_field_filter.py) |
+| stopwords_filter |    | Filter to keep samples with stopword ratio larger than a specific min value. 过滤以保留停用词比率大于特定最小值的样本。 | [code](../data_juicer/ops/filter/stopwords_filter.py) | [tests](../tests/ops/filter/test_stopwords_filter.py) |
+| suffix_filter |   | Filter to keep samples with specified suffix. 过滤以保留具有指定后缀的样本。 | [code](../data_juicer/ops/filter/suffix_filter.py) | [tests](../tests/ops/filter/test_suffix_filter.py) |
+| text_action_filter |    | Filter to keep texts those contain actions in the text. 过滤以保留文本中包含操作的文本。 | [code](../data_juicer/ops/filter/text_action_filter.py) | [tests](../tests/ops/filter/test_text_action_filter.py) |
+| text_entity_dependency_filter |    | Identify the entities in the text which are independent with other token, and filter them. 识别文本中与其他标记无关的实体,并过滤它们。 | [code](../data_juicer/ops/filter/text_entity_dependency_filter.py) | [tests](../tests/ops/filter/test_text_entity_dependency_filter.py) |
+| text_length_filter |    | Filter to keep samples with total text length within a specific range. 过滤以将总文本长度保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/text_length_filter.py) | [tests](../tests/ops/filter/test_text_length_filter.py) |
+| token_num_filter |     | Filter to keep samples with total token number within a specific range. 过滤以将总标记数保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/token_num_filter.py) | [tests](../tests/ops/filter/test_token_num_filter.py) |
+| video_aesthetics_filter |     | Filter to keep data samples with aesthetics scores for specified frames in the videos within a specific range. 过滤以将视频中指定帧的美学分数保持在特定范围内的数据样本。 | [code](../data_juicer/ops/filter/video_aesthetics_filter.py) | [tests](../tests/ops/filter/test_video_aesthetics_filter.py) |
+| video_aspect_ratio_filter |    | Filter to keep samples with video aspect ratio within a specific range. 过滤以将视频宽高比保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/video_aspect_ratio_filter.py) | [tests](../tests/ops/filter/test_video_aspect_ratio_filter.py) |
+| video_duration_filter |    | Keep data samples whose videos' durations are within a specified range. 保留视频时长在指定范围内的数据样本。 | [code](../data_juicer/ops/filter/video_duration_filter.py) | [tests](../tests/ops/filter/test_video_duration_filter.py) |
+| video_frames_text_similarity_filter |     | Filter to keep samples those similarities between sampled video frame images and text within a specific range. 过滤以将采样的视频帧图像和文本之间的相似性保持在特定范围内。 | [code](../data_juicer/ops/filter/video_frames_text_similarity_filter.py) | [tests](../tests/ops/filter/test_video_frames_text_similarity_filter.py) |
+| video_motion_score_filter |    | Filter to keep samples with video motion scores within a specific range. 过滤以将视频运动分数保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/video_motion_score_filter.py) | [tests](../tests/ops/filter/test_video_motion_score_filter.py) |
+| video_motion_score_raft_filter |    | Filter to keep samples with video motion scores within a specified range. 过滤以将视频运动分数保持在指定范围内的样本。 | [code](../data_juicer/ops/filter/video_motion_score_raft_filter.py) | [tests](../tests/ops/filter/test_video_motion_score_raft_filter.py) |
+| video_nsfw_filter |     | Filter to keep samples whose videos have low nsfw scores. 过滤以保留视频 nsfw 分数较低的样本。 | [code](../data_juicer/ops/filter/video_nsfw_filter.py) | [tests](../tests/ops/filter/test_video_nsfw_filter.py) |
+| video_ocr_area_ratio_filter |    | Keep data samples whose detected text area ratios for specified frames in the video are within a specified range. 保持视频中指定帧的检测到的文本面积比例在指定范围内的数据样本。 | [code](../data_juicer/ops/filter/video_ocr_area_ratio_filter.py) | [tests](../tests/ops/filter/test_video_ocr_area_ratio_filter.py) |
+| video_resolution_filter |    | Keep data samples whose videos' resolutions are within a specified range. 保留视频分辨率在指定范围内的数据样本。 | [code](../data_juicer/ops/filter/video_resolution_filter.py) | [tests](../tests/ops/filter/test_video_resolution_filter.py) |
+| video_tagging_from_frames_filter |    | Filter to keep samples whose videos contain the given tags. 过滤以保留视频包含给定标签的样本。 | [code](../data_juicer/ops/filter/video_tagging_from_frames_filter.py) | [tests](../tests/ops/filter/test_video_tagging_from_frames_filter.py) |
+| video_watermark_filter |     | Filter to keep samples whose videos have no watermark with high probability. 过滤以高概率保留视频无水印的样本。 | [code](../data_juicer/ops/filter/video_watermark_filter.py) | [tests](../tests/ops/filter/test_video_watermark_filter.py) |
+| word_repetition_filter |    | Filter to keep samples with word-level n-gram repetition ratio within a specific range. 过滤以将单词级 n-gram 重复率的样本保持在特定范围内。 | [code](../data_juicer/ops/filter/word_repetition_filter.py) | [tests](../tests/ops/filter/test_word_repetition_filter.py) |
+| words_num_filter |    | Filter to keep samples with total words number within a specific range. 过滤以将总字数保持在特定范围内的样本。 | [code](../data_juicer/ops/filter/words_num_filter.py) | [tests](../tests/ops/filter/test_words_num_filter.py) |
+
+## formatter
+
+| Operator 算子 | Tags 标签 | Description 描述 | Source code 源码 | Unit tests 单测样例 |
+|----------|------|-------------|-------------|------------|
+| csv_formatter |  | The class is used to load and format csv-type files. 该类用于加载和格式化csv类型文件。 | [code](../data_juicer/format/csv_formatter.py) | [tests](../tests/format/test_csv_formatter.py) |
+| empty_formatter |  | The class is used to create empty data. 该类用于创建空数据。 | [code](../data_juicer/format/empty_formatter.py) | [tests](../tests/format/test_empty_formatter.py) |
+| json_formatter |  | The class is used to load and format json-type files. 该类用于加载和格式化json类型的文件。 | [code](../data_juicer/format/json_formatter.py) | - |
+| local_formatter |  | The class is used to load a dataset from local files or local directory. 该类用于从本地文件或本地目录加载数据集。 | [code](../data_juicer/format/formatter.py) | [tests](../tests/format/test_unify_format.py) |
+| mixture_formatter |  | The class mixes multiple datasets by randomly selecting samples from every dataset and merging them, and then exports the merged datasset as a new mixed dataset. 该类通过从每个数据集中随机选择样本并合并它们来混合多个数据集,然后将合并的数据集导出为新的混合数据集。 | [code](../data_juicer/format/mixture_formatter.py) | [tests](../tests/format/test_mixture_formatter.py) |
+| parquet_formatter |  | The class is used to load and format parquet-type files. 该类用于加载和格式化镶木地板类型文件。 | [code](../data_juicer/format/parquet_formatter.py) | [tests](../tests/format/test_parquet_formatter.py) |
+| remote_formatter |  | The class is used to load a dataset from repository of huggingface hub. 该类用于从 Huggingface Hub 的存储库加载数据集。 | [code](../data_juicer/format/formatter.py) | [tests](../tests/format/test_unify_format.py) |
+| text_formatter |  | The class is used to load and format text-type files. 该类用于加载和格式化文本类型文件。 | [code](../data_juicer/format/text_formatter.py) | - |
+| tsv_formatter |  | The class is used to load and format tsv-type files. 该类用于加载和格式化 tsv 类型文件。 | [code](../data_juicer/format/tsv_formatter.py) | [tests](../tests/format/test_tsv_formatter.py) |
+
+## grouper
+
+| Operator 算子 | Tags 标签 | Description 描述 | Source code 源码 | Unit tests 单测样例 |
+|----------|------|-------------|-------------|------------|
+| key_value_grouper |    | Group samples to batched samples according values in given keys. 根据给定键中的值将样本分组为批量样本。 | [code](../data_juicer/ops/grouper/key_value_grouper.py) | [tests](../tests/ops/grouper/test_key_value_grouper.py) |
+| naive_grouper |   | Group all samples to one batched sample. 将所有样本分组为一个批次样本。 | [code](../data_juicer/ops/grouper/naive_grouper.py) | [tests](../tests/ops/grouper/test_naive_grouper.py) |
+| naive_reverse_grouper |   | Split batched samples to samples. 将批次样本拆分为样本。 | [code](../data_juicer/ops/grouper/naive_reverse_grouper.py) | [tests](../tests/ops/grouper/test_naive_reverse_grouper.py) |
+
+## mapper
+
+| Operator 算子 | Tags 标签 | Description 描述 | Source code 源码 | Unit tests 单测样例 |
+|----------|------|-------------|-------------|------------|
+| audio_ffmpeg_wrapped_mapper |    | Simple wrapper for FFmpeg audio filters. FFmpeg 音频过滤器的简单包装。 | [code](../data_juicer/ops/mapper/audio_ffmpeg_wrapped_mapper.py) | [tests](../tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py) |
+| calibrate_qa_mapper |     | Mapper to calibrate question-answer pairs based on reference text. 映射器根据参考文本校准问答对。 | [code](../data_juicer/ops/mapper/calibrate_qa_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_qa_mapper.py) |
+| calibrate_query_mapper |   | Mapper to calibrate query in question-answer pairs based on reference text. 映射器根据参考文本校准问答对中的查询。 | [code](../data_juicer/ops/mapper/calibrate_query_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_query_mapper.py) |
+| calibrate_response_mapper |   | Mapper to calibrate response in question-answer pairs based on reference text. 映射器根据参考文本校准问答对中的响应。 | [code](../data_juicer/ops/mapper/calibrate_response_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_response_mapper.py) |
+| chinese_convert_mapper |    | Mapper to convert Chinese between Traditional Chinese, Simplified Chinese and Japanese Kanji. 映射器在繁体中文、简体中文和日文汉字之间进行转换。 | [code](../data_juicer/ops/mapper/chinese_convert_mapper.py) | [tests](../tests/ops/mapper/test_chinese_convert_mapper.py) |
+| clean_copyright_mapper |    | Mapper to clean copyright comments at the beginning of the text samples. 映射器可清除文本示例开头的版权注释。 | [code](../data_juicer/ops/mapper/clean_copyright_mapper.py) | [tests](../tests/ops/mapper/test_clean_copyright_mapper.py) |
+| clean_email_mapper |    | Mapper to clean email in text samples. 映射器用于清理文本样本中的电子邮件。 | [code](../data_juicer/ops/mapper/clean_email_mapper.py) | [tests](../tests/ops/mapper/test_clean_email_mapper.py) |
+| clean_html_mapper |    | Mapper to clean html code in text samples. 用于清理文本示例中的 html 代码的映射器。 | [code](../data_juicer/ops/mapper/clean_html_mapper.py) | [tests](../tests/ops/mapper/test_clean_html_mapper.py) |
+| clean_ip_mapper |    | Mapper to clean ipv4 and ipv6 address in text samples. 用于清理文本样本中的 ipv4 和 ipv6 地址的映射器。 | [code](../data_juicer/ops/mapper/clean_ip_mapper.py) | [tests](../tests/ops/mapper/test_clean_ip_mapper.py) |
+| clean_links_mapper |    | Mapper to clean links like http/https/ftp in text samples. 映射器用于清理文本示例中的 http/https/ftp 等链接。 | [code](../data_juicer/ops/mapper/clean_links_mapper.py) | [tests](../tests/ops/mapper/test_clean_links_mapper.py) |
+| dialog_intent_detection_mapper |    | Mapper to generate user's intent labels in dialog. 映射器在对话框中生成用户的意图标签。 | [code](../data_juicer/ops/mapper/dialog_intent_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_intent_detection_mapper.py) |
+| dialog_sentiment_detection_mapper |    | Mapper to generate user's sentiment labels in dialog. 映射器在对话框中生成用户的情绪标签。 | [code](../data_juicer/ops/mapper/dialog_sentiment_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_sentiment_detection_mapper.py) |
+| dialog_sentiment_intensity_mapper |    | Mapper to predict user's sentiment intensity (from -5 to 5 in default prompt) in dialog. 映射器在对话框中预测用户的情绪强度(默认提示中从 -5 到 5)。 | [code](../data_juicer/ops/mapper/dialog_sentiment_intensity_mapper.py) | [tests](../tests/ops/mapper/test_dialog_sentiment_intensity_mapper.py) |
+| dialog_topic_detection_mapper |    | Mapper to generate user's topic labels in dialog. 映射器在对话框中生成用户的主题标签。 | [code](../data_juicer/ops/mapper/dialog_topic_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_topic_detection_mapper.py) |
+| expand_macro_mapper |    | Mapper to expand macro definitions in the document body of Latex samples. Mapper 用于扩展 Latex 示例文档主体中的宏定义。 | [code](../data_juicer/ops/mapper/expand_macro_mapper.py) | [tests](../tests/ops/mapper/test_expand_macro_mapper.py) |
+| extract_entity_attribute_mapper |     | Extract attributes for given entities from the text. 从文本中提取给定实体的属性。 | [code](../data_juicer/ops/mapper/extract_entity_attribute_mapper.py) | [tests](../tests/ops/mapper/test_extract_entity_attribute_mapper.py) |
+| extract_entity_relation_mapper |     | Extract entities and relations in the text for knowledge graph. 提取文本中的实体和关系,形成知识图谱。 | [code](../data_juicer/ops/mapper/extract_entity_relation_mapper.py) | [tests](../tests/ops/mapper/test_extract_entity_relation_mapper.py) |
+| extract_event_mapper |     | Extract events and relevant characters in the text. 提取文本中的事件和相关字符。 | [code](../data_juicer/ops/mapper/extract_event_mapper.py) | [tests](../tests/ops/mapper/test_extract_event_mapper.py) |
+| extract_keyword_mapper |     | Generate keywords for the text. 为文本生成关键字。 | [code](../data_juicer/ops/mapper/extract_keyword_mapper.py) | [tests](../tests/ops/mapper/test_extract_keyword_mapper.py) |
+| extract_nickname_mapper |     | Extract nickname relationship in the text. 提取文本中的昵称关系。 | [code](../data_juicer/ops/mapper/extract_nickname_mapper.py) | [tests](../tests/ops/mapper/test_extract_nickname_mapper.py) |
+| extract_support_text_mapper |     | Extract support sub text for a summary. 提取支持子文本以进行摘要。 | [code](../data_juicer/ops/mapper/extract_support_text_mapper.py) | [tests](../tests/ops/mapper/test_extract_support_text_mapper.py) |
+| fix_unicode_mapper |    | Mapper to fix unicode errors in text samples. 映射器修复文本样本中的 unicode 错误。 | [code](../data_juicer/ops/mapper/fix_unicode_mapper.py) | [tests](../tests/ops/mapper/test_fix_unicode_mapper.py) |
+| generate_qa_from_examples_mapper |     | Mapper to generate question and answer pairs from examples. 映射器从示例生成问题和答案对。 | [code](../data_juicer/ops/mapper/generate_qa_from_examples_mapper.py) | [tests](../tests/ops/mapper/test_generate_qa_from_examples_mapper.py) |
+| generate_qa_from_text_mapper |      | Mapper to generate question and answer pairs from text. 映射器从文本生成问题和答案对。 | [code](../data_juicer/ops/mapper/generate_qa_from_text_mapper.py) | [tests](../tests/ops/mapper/test_generate_qa_from_text_mapper.py) |
+| image_blur_mapper |    | Mapper to blur images. 映射器模糊图像。 | [code](../data_juicer/ops/mapper/image_blur_mapper.py) | [tests](../tests/ops/mapper/test_image_blur_mapper.py) |
+| image_captioning_from_gpt4v_mapper |    | Mapper to generate samples whose texts are generated based on gpt-4-visison and the image. Mapper 生成样本,其文本是基于 gpt-4-vision 和图像生成的。 | [code](../data_juicer/ops/mapper/image_captioning_from_gpt4v_mapper.py) | - |
+| image_captioning_mapper |     | Mapper to generate samples whose captions are generated based on another model and the figure. 映射器生成样本,其标题是根据另一个模型和图形生成的。 | [code](../data_juicer/ops/mapper/image_captioning_mapper.py) | [tests](../tests/ops/mapper/test_image_captioning_mapper.py) |
+| image_diffusion_mapper |     | Generate image by diffusion model. 通过扩散模型生成图像。 | [code](../data_juicer/ops/mapper/image_diffusion_mapper.py) | [tests](../tests/ops/mapper/test_image_diffusion_mapper.py) |
+| image_face_blur_mapper |    | Mapper to blur faces detected in images. 映射器用于模糊图像中检测到的人脸。 | [code](../data_juicer/ops/mapper/image_face_blur_mapper.py) | [tests](../tests/ops/mapper/test_image_face_blur_mapper.py) |
+| image_tagging_mapper |    | Mapper to generate image tags. 映射器生成图像标签。 | [code](../data_juicer/ops/mapper/image_tagging_mapper.py) | [tests](../tests/ops/mapper/test_image_tagging_mapper.py) |
+| nlpaug_en_mapper |    | Mapper to simply augment samples in English based on nlpaug library. Mapper 基于 nlpaug 库简单地增加英语样本。 | [code](../data_juicer/ops/mapper/nlpaug_en_mapper.py) | [tests](../tests/ops/mapper/test_nlpaug_en_mapper.py) |
+| nlpcda_zh_mapper |    | Mapper to simply augment samples in Chinese based on nlpcda library. Mapper 基于 nlpcda 库简单地扩充中文样本。 | [code](../data_juicer/ops/mapper/nlpcda_zh_mapper.py) | [tests](../tests/ops/mapper/test_nlpcda_zh_mapper.py) |
+| optimize_qa_mapper |     | Mapper to optimize question-answer pairs. 用于优化问答对的映射器。 | [code](../data_juicer/ops/mapper/optimize_qa_mapper.py) | [tests](../tests/ops/mapper/test_optimize_qa_mapper.py) |
+| optimize_query_mapper |   | Mapper to optimize query in question-answer pairs. 映射器用于优化问答对中的查询。 | [code](../data_juicer/ops/mapper/optimize_query_mapper.py) | [tests](../tests/ops/mapper/test_optimize_query_mapper.py) |
+| optimize_response_mapper |   | Mapper to optimize response in question-answer pairs. 映射器可优化问答对中的响应。 | [code](../data_juicer/ops/mapper/optimize_response_mapper.py) | [tests](../tests/ops/mapper/test_optimize_response_mapper.py) |
+| pair_preference_mapper |     | Mapper to construct paired preference samples. 映射器构建配对偏好样本。 | [code](../data_juicer/ops/mapper/pair_preference_mapper.py) | [tests](../tests/ops/mapper/test_pair_preference_mapper.py) |
+| punctuation_normalization_mapper |    | Mapper to normalize unicode punctuations to English punctuations in text samples. 映射器将文本样本中的 unicode 标点符号标准化为英文标点符号。 | [code](../data_juicer/ops/mapper/punctuation_normalization_mapper.py) | [tests](../tests/ops/mapper/test_punctuation_normalization_mapper.py) |
+| python_file_mapper |   | Mapper for executing Python function defined in a file. 用于执行文件中定义的 Python 函数的映射器。 | [code](../data_juicer/ops/mapper/python_file_mapper.py) | [tests](../tests/ops/mapper/test_python_file_mapper.py) |
+| python_lambda_mapper |   | Mapper for executing Python lambda function on data samples. 用于在数据样本上执行 Python lambda 函数的映射器。 | [code](../data_juicer/ops/mapper/python_lambda_mapper.py) | [tests](../tests/ops/mapper/test_python_lambda_mapper.py) |
+| query_intent_detection_mapper |     | Mapper to predict user's Intent label in query. 映射器用于预测查询中用户的意图标签。 | [code](../data_juicer/ops/mapper/query_intent_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_intent_detection_mapper.py) |
+| query_sentiment_detection_mapper |     | Mapper to predict user's sentiment label ('negative', 'neutral' and 'positive') in query. 用于预测查询中用户情绪标签(“负面”、“中性”和“正面”)的映射器。 | [code](../data_juicer/ops/mapper/query_sentiment_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_sentiment_detection_mapper.py) |
+| query_topic_detection_mapper |     | Mapper to predict user's topic label in query. 映射器用于预测查询中用户的主题标签。 | [code](../data_juicer/ops/mapper/query_topic_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_topic_detection_mapper.py) |
+| relation_identity_mapper |     | identify relation between two entity in the text. 识别文本中两个实体之间的关系。 | [code](../data_juicer/ops/mapper/relation_identity_mapper.py) | [tests](../tests/ops/mapper/test_relation_identity_mapper.py) |
+| remove_bibliography_mapper |    | Mapper to remove bibliography at the end of documents in Latex samples. Mapper 用于删除 Latex 样本中文档末尾的参考书目。 | [code](../data_juicer/ops/mapper/remove_bibliography_mapper.py) | [tests](../tests/ops/mapper/test_remove_bibliography_mapper.py) |
+| remove_comments_mapper |    | Mapper to remove comments in different kinds of documents. 映射器用于删除不同类型文档中的注释。 | [code](../data_juicer/ops/mapper/remove_comments_mapper.py) | [tests](../tests/ops/mapper/test_remove_comments_mapper.py) |
+| remove_header_mapper |    | Mapper to remove headers at the beginning of documents in Latex samples. 映射器用于删除 Latex 示例中文档开头的标头。 | [code](../data_juicer/ops/mapper/remove_header_mapper.py) | [tests](../tests/ops/mapper/test_remove_header_mapper.py) |
+| remove_long_words_mapper |    | Mapper to remove long words within a specific range. 映射器删除特定范围内的长单词。 | [code](../data_juicer/ops/mapper/remove_long_words_mapper.py) | [tests](../tests/ops/mapper/test_remove_long_words_mapper.py) |
+| remove_non_chinese_character_mapper |    | Mapper to remove non chinese Character in text samples. 映射器删除文本样本中的非中文字符。 | [code](../data_juicer/ops/mapper/remove_non_chinese_character_mapper.py) | [tests](../tests/ops/mapper/test_remove_non_chinese_character_mapper.py) |
+| remove_repeat_sentences_mapper |    | Mapper to remove repeat sentences in text samples. 映射器用于删除文本样本中的重复句子。 | [code](../data_juicer/ops/mapper/remove_repeat_sentences_mapper.py) | [tests](../tests/ops/mapper/test_remove_repeat_sentences_mapper.py) |
+| remove_specific_chars_mapper |    | Mapper to clean specific chars in text samples. 映射器用于清理文本样本中的特定字符。 | [code](../data_juicer/ops/mapper/remove_specific_chars_mapper.py) | [tests](../tests/ops/mapper/test_remove_specific_chars_mapper.py) |
+| remove_table_text_mapper |    | Mapper to remove table texts from text samples. 映射器从文本样本中删除表格文本。 | [code](../data_juicer/ops/mapper/remove_table_text_mapper.py) | [tests](../tests/ops/mapper/test_remove_table_text_mapper.py) |
+| remove_words_with_incorrect_substrings_mapper |    | Mapper to remove words with incorrect substrings. 映射器删除带有不正确子字符串的单词。 | [code](../data_juicer/ops/mapper/remove_words_with_incorrect_substrings_mapper.py) | [tests](../tests/ops/mapper/test_remove_words_with_incorrect_substrings_mapper.py) |
+| replace_content_mapper |    | Mapper to replace all content in the text that matches a specific regular expression pattern with a designated replacement string. 映射器用指定的替换字符串替换文本中与特定正则表达式模式匹配的所有内容。 | [code](../data_juicer/ops/mapper/replace_content_mapper.py) | [tests](../tests/ops/mapper/test_replace_content_mapper.py) |
+| sentence_split_mapper |    | Mapper to split text samples to sentences. 映射器将文本样本拆分为句子。 | [code](../data_juicer/ops/mapper/sentence_split_mapper.py) | [tests](../tests/ops/mapper/test_sentence_split_mapper.py) |
+| text_chunk_mapper |     | Split input text to chunks. 将输入文本拆分为块。 | [code](../data_juicer/ops/mapper/text_chunk_mapper.py) | [tests](../tests/ops/mapper/test_text_chunk_mapper.py) |
+| video_captioning_from_audio_mapper |     | Mapper to caption a video according to its audio streams based on Qwen-Audio model. 映射器根据基于 Qwen-Audio 模型的音频流为视频添加字幕。 | [code](../data_juicer/ops/mapper/video_captioning_from_audio_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_audio_mapper.py) |
+| video_captioning_from_frames_mapper |     | Mapper to generate samples whose captions are generated based on an image-to-text model and sampled video frames. 映射器生成样本,其字幕是根据图像到文本模型和采样的视频帧生成的。 | [code](../data_juicer/ops/mapper/video_captioning_from_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_frames_mapper.py) |
+| video_captioning_from_summarizer_mapper |     | Mapper to generate video captions by summarizing several kinds of generated texts (captions from video/audio/frames, tags from audio/frames, ...). 映射器通过汇总几种生成的文本(来自视频/音频/帧的字幕、来自音频/帧的标签等)来生成视频字幕。 | [code](../data_juicer/ops/mapper/video_captioning_from_summarizer_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_summarizer_mapper.py) |
+| video_captioning_from_video_mapper |     | Mapper to generate samples whose captions are generated based on a video-to-text model and sampled video frame. 映射器生成样本,其字幕是根据视频到文本模型和采样的视频帧生成的。 | [code](../data_juicer/ops/mapper/video_captioning_from_video_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_video_mapper.py) |
+| video_extract_frames_mapper |    | Mapper to extract frames from video files according to specified methods. Mapper根据指定的方法从视频文件中提取帧。 | [code](../data_juicer/ops/mapper/video_extract_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_extract_frames_mapper.py) |
+| video_face_blur_mapper |    | Mapper to blur faces detected in videos. 映射器用于模糊视频中检测到的面孔。 | [code](../data_juicer/ops/mapper/video_face_blur_mapper.py) | [tests](../tests/ops/mapper/test_video_face_blur_mapper.py) |
+| video_ffmpeg_wrapped_mapper |    | Simple wrapper for FFmpeg video filters. FFmpeg 视频过滤器的简单包装。 | [code](../data_juicer/ops/mapper/video_ffmpeg_wrapped_mapper.py) | [tests](../tests/ops/mapper/test_video_ffmpeg_wrapped_mapper.py) |
+| video_remove_watermark_mapper |    | Remove the watermarks in videos given regions. 删除给定区域视频中的水印。 | [code](../data_juicer/ops/mapper/video_remove_watermark_mapper.py) | [tests](../tests/ops/mapper/test_video_remove_watermark_mapper.py) |
+| video_resize_aspect_ratio_mapper |    | Mapper to resize videos by aspect ratio. 映射器可按宽高比调整视频大小。 | [code](../data_juicer/ops/mapper/video_resize_aspect_ratio_mapper.py) | [tests](../tests/ops/mapper/test_video_resize_aspect_ratio_mapper.py) |
+| video_resize_resolution_mapper |    | Mapper to resize videos resolution. 映射器可调整视频分辨率。 | [code](../data_juicer/ops/mapper/video_resize_resolution_mapper.py) | [tests](../tests/ops/mapper/test_video_resize_resolution_mapper.py) |
+| video_split_by_duration_mapper |    | Mapper to split video by duration. 映射器按持续时间分割视频。 | [code](../data_juicer/ops/mapper/video_split_by_duration_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_duration_mapper.py) |
+| video_split_by_key_frame_mapper |    | Mapper to split video by key frame. 映射器按关键帧分割视频。 | [code](../data_juicer/ops/mapper/video_split_by_key_frame_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_key_frame_mapper.py) |
+| video_split_by_scene_mapper |    | Mapper to cut videos into scene clips. 映射器将视频剪切成场景剪辑。 | [code](../data_juicer/ops/mapper/video_split_by_scene_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_scene_mapper.py) |
+| video_tagging_from_audio_mapper |     | Mapper to generate video tags from audio streams extracted by video using the Audio Spectrogram Transformer. 映射器使用音频频谱图转换器从视频提取的音频流生成视频标签。 | [code](../data_juicer/ops/mapper/video_tagging_from_audio_mapper.py) | [tests](../tests/ops/mapper/test_video_tagging_from_audio_mapper.py) |
+| video_tagging_from_frames_mapper |    | Mapper to generate video tags from frames extract by video. 映射器从视频提取的帧中生成视频标签。 | [code](../data_juicer/ops/mapper/video_tagging_from_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_tagging_from_frames_mapper.py) |
+| whitespace_normalization_mapper |    | Mapper to normalize different kinds of whitespaces to whitespace ' ' (0x20) in text samples. 映射器将文本样本中不同类型的空白规范化为空白“ ” (0x20)。 | [code](../data_juicer/ops/mapper/whitespace_normalization_mapper.py) | [tests](../tests/ops/mapper/test_whitespace_normalization_mapper.py) |
+
+## selector
+
+| Operator 算子 | Tags 标签 | Description 描述 | Source code 源码 | Unit tests 单测样例 |
+|----------|------|-------------|-------------|------------|
+| frequency_specified_field_selector |   | Selector to select samples based on the sorted frequency of specified field. 选择器根据指定字段的排序频率选择样本。 | [code](../data_juicer/ops/selector/frequency_specified_field_selector.py) | [tests](../tests/ops/selector/test_frequency_specified_field_selector.py) |
+| random_selector |   | Selector to random select samples. 选择器随机选择样本。 | [code](../data_juicer/ops/selector/random_selector.py) | [tests](../tests/ops/selector/test_random_selector.py) |
+| range_specified_field_selector |   | Selector to select a range of samples based on the sorted specified field value from smallest to largest. 选择器根据指定字段值从小到大的顺序选择一系列样本。 | [code](../data_juicer/ops/selector/range_specified_field_selector.py) | [tests](../tests/ops/selector/test_range_specified_field_selector.py) |
+| tags_specified_field_selector |   | Selector to select samples based on the tags of specified field. 选择器根据指定字段的标签选择样本。 | [code](../data_juicer/ops/selector/tags_specified_field_selector.py) | [tests](../tests/ops/selector/test_tags_specified_field_selector.py) |
+| topk_specified_field_selector |   | Selector to select top samples based on the sorted specified field value. 选择器根据排序的指定字段值选择顶部样本。 | [code](../data_juicer/ops/selector/topk_specified_field_selector.py) | [tests](../tests/ops/selector/test_topk_specified_field_selector.py) |
+
+
+## Contributing 贡献
+
+We welcome contributions of adding new operators. Please refer to [How-to Guide
+for Developers](DeveloperGuide.md).
+
+我们欢迎社区贡献新的算子,具体请参考[开发者指南](DeveloperGuide_ZH.md)。
diff --git a/docs/Operators_ZH.md b/docs/Operators_ZH.md
deleted file mode 100644
index 46cee3014..000000000
--- a/docs/Operators_ZH.md
+++ /dev/null
@@ -1,223 +0,0 @@
-# 算子提要
-
-算子 (Operator) 是协助数据修改、清理、过滤、去重等基本流程的集合。我们支持广泛的数据来源和文件格式,并支持对自定义数据集的灵活扩展。
-
-这个页面提供了OP的基本描述,用户可以参考[API文档](https://modelscope.github.io/data-juicer/)更细致了解每个OP的具体参数,并且可以查看、运行单元测试 (`tests/ops/...`),来体验[各OP的用法示例](../tests/ops)以及每个OP作用于内置测试数据样本时的效果。
-
-## 概览
-
-Data-Juicer 中的算子分为以下 7 种类型。
-
-| 类型 | 数量 | 描述 |
-|------------------------------------|:--:|---------------|
-| [ Formatter ]( #formatter ) | 9 | 发现、加载、规范化原始数据 |
-| [ Mapper ]( #mapper ) | 70 | 对数据样本进行编辑和转换 |
-| [ Filter ]( #filter ) | 44 | 过滤低质量样本 |
-| [ Deduplicator ]( #deduplicator ) | 8 | 识别、删除重复样本 |
-| [ Selector ]( #selector ) | 5 | 基于排序选取高质量样本 |
-| [ Grouper ]( #grouper ) | 3 | 将样本分组,每一组组成一个批量样本 |
-| [ Aggregator ]( #aggregator ) | 4 | 对批量样本进行汇总,如得出总结或结论 |
-
-下面列出所有具体算子,每种算子都通过多个标签来注明其主要功能。
-
-* 领域标签
- - : 一般用途
- - : 专用于 LaTeX 源文件
- - : 专用于编程代码
- - : 与金融领域相关
-* 模态标签
- - : 专用于文本
- - : 专用于图像
- - : 专用于音频
- - : 专用于视频
- - : 专用于多模态
-* 语言标签
- - : 英文
- - : 中文
-* 资源标签
- - : 只需要 CPU 资源 (默认)
- - : 额外需要 GPU/CUDA 资源
-
-
-## Formatter
-
-| 算子 | 标签 | 描述 | 源码 | 单测样例 |
-|-------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------|----------------------------------------------------|----------------------------------------------------|
-| local_formatter |    | 从本地文件准备数据集 | [code](../data_juicer/format/formatter.py) | [tests](../tests/format/test_unify_format.py) |
-| remote_formatter |    | 准备远端数据集 (如 HuggingFace) | [code](../data_juicer/format/formatter.py) | [tests](../tests/format/test_unify_format.py) |
-| csv_formatter |    | 准备本地 `.csv` 文件 | [code](../data_juicer/format/csv_formatter.py) | [tests](../tests/format/test_csv_formatter.py) |
-| tsv_formatter |    | 准备本地 `.tsv` 文件 | [code](../data_juicer/format/tsv_formatter.py) | [tests](../tests/format/test_tsv_formatter.py) |
-| json_formatter |    | 准备本地 `.json`, `.jsonl`, `.jsonl.zst` 文件 | [code](../data_juicer/format/json_formatter.py) | - |
-| parquet_formatter |    | 准备本地 `.parquet` 文件 | [code](../data_juicer/format/parquet_formatter.py) | [tests](../tests/format/test_parquet_formatter.py) |
-| text_formatter |    | 准备其他本地文本文件([完整的支持列表](../data_juicer/format/text_formatter.py#L63,73)) | [code](../data_juicer/format/text_formatter.py) | - |
-| empty_formatter |  | 准备一个空数据集 | [code](../data_juicer/format/empty_formatter.py) | [tests](../tests/format/test_empty_formatter.py) |
-| mixture_formatter |    | 处理可支持本地文件的混合 | [code](../data_juicer/format/mixture_formatter.py) | [tests](../tests/format/test_mixture_formatter.py) |
-
-## Mapper
-
-| 算子 | 标签 | 描述 | 源码 | 单测样例 |
-|------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------|------------------------------------------------------------------------------------|
-| audio_ffmpeg_wrapped_mapper |  | 运行 FFmpeg 语音过滤器的简单封装 | [code](../data_juicer/ops/mapper/audio_ffmpeg_wrapped_mapper.py) | [tests](../tests/ops/mapper/test_audio_ffmpeg_wrapped_mapper.py) |
-| calibrate_qa_mapper |     | 根据参考文本校准问答对 | [code](../data_juicer/ops/mapper/calibrate_qa_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_qa_mapper.py) |
-| calibrate_query_mapper |     | 根据参考文本校准问答对中的问题 | [code](../data_juicer/ops/mapper/calibrate_query_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_query_mapper.py) |
-| calibrate_response_mapper |     | 根据参考文本校准问答对中的回答 | [code](../data_juicer/ops/mapper/calibrate_response_mapper.py) | [tests](../tests/ops/mapper/test_calibrate_response_mapper.py) |
-| chinese_convert_mapper |    | 用于在繁体中文、简体中文和日文汉字之间进行转换(借助 [opencc](https://github.com/BYVoid/OpenCC)) | [code](../data_juicer/ops/mapper/chinese_convert_mapper.py) | [tests](../tests/ops/mapper/test_chinese_convert_mapper.py) |
-| clean_copyright_mapper |     | 删除代码文件开头的版权声明 (必须包含单词 *copyright*) | [code](../data_juicer/ops/mapper/clean_copyright_mapper.py) | [tests](../tests/ops/mapper/test_clean_copyright_mapper.py) |
-| clean_email_mapper |     | 删除邮箱信息 | [code](../data_juicer/ops/mapper/clean_email_mapper.py) | [tests](../tests/ops/mapper/test_clean_email_mapper.py) |
-| clean_html_mapper |     | 删除 HTML 标签并返回所有节点的纯文本 | [code](../data_juicer/ops/mapper/clean_html_mapper.py) | [tests](../tests/ops/mapper/test_clean_html_mapper.py) |
-| clean_ip_mapper |     | 删除 IP 地址 | [code](../data_juicer/ops/mapper/clean_ip_mapper.py) | [tests](../tests/ops/mapper/test_clean_ip_mapper.py) |
-| clean_links_mapper |      | 删除链接,例如以 http 或 ftp 开头的 | [code](../data_juicer/ops/mapper/clean_links_mapper.py) | [tests](../tests/ops/mapper/test_clean_links_mapper.py) |
-| dialog_intent_detection_mapper |     | 抽取对话中的用户意图标签。 | [code](../data_juicer/ops/mapper/dialog_intent_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_intent_detection_mapper.py) |
-| dialog_sentiment_detection_mapper |     | 抽取对话中用户的情感标签 | [code](../data_juicer/ops/mapper/dialog_sentiment_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_sentiment_detection_mapper.py) |
-| dialog_sentiment_intensity_mapper |     | 预测对话中的情绪强度(默认从-5到5)。 | [code](../data_juicer/ops/mapper/dialog_sentiment_intensity_mapper.py) | [tests](../tests/ops/mapper/test_dialog_sentiment_intensity_mapper.py) |
-| dialog_topic_detection_mapper |     | 抽取对话中的用户的话题标签。 | [code](../data_juicer/ops/mapper/dialog_topic_detection_mapper.py) | [tests](../tests/ops/mapper/test_dialog_topic_detection_mapper.py) |
-| expand_macro_mapper |     | 扩展通常在 TeX 文档顶部定义的宏 | [code](../data_juicer/ops/mapper/expand_macro_mapper.py) | [tests](../tests/ops/mapper/test_expand_macro_mapper.py) |
-| extract_entity_attribute_mapper |     | 给定主体和属性名,从文本中抽取主体的属性 | [code](../data_juicer/ops/mapper/extract_entity_attribute_mapper.py) | [tests](../tests/ops/mapper/test_extract_entity_attribute_mapper.py) |
-| extract_entity_relation_mapper |     | 从文本中抽取知识图谱的实体和关系 | [code](../data_juicer/ops/mapper/extract_entity_relation_mapper.py) | [tests](../tests/ops/mapper/test_extract_entity_relation_mapper.py) |
-| extract_event_mapper |     | 从文本中抽取出事件和事件相关人物 | [code](../data_juicer/ops/mapper/extract_event_mapper.py) | [tests](../tests/ops/mapper/test_extract_event_mapper.py) |
-| extract_keyword_mapper |     | 构造文本的关键词 | [code](../data_juicer/ops/mapper/extract_keyword_mapper.py) | [tests](../tests/ops/mapper/test_extract_keyword_mapper.py) |
-| extract_nickname_mapper |     | 抽取昵称称呼关系 | [code](../data_juicer/ops/mapper/extract_nickname_mapper.py) | [tests](../tests/ops/mapper/test_extract_nickname_mapper.py) |
-| extract_support_text_mapper |     | 为一段总结抽取对应原文 | [code](../data_juicer/ops/mapper/extract_support_text_mapper.py) | [tests](../tests/ops/mapper/test_extract_support_text_mapper.py) |
-| fix_unicode_mapper |     | 修复损坏的 Unicode(借助 [ftfy](https://ftfy.readthedocs.io/)) | [code](../data_juicer/ops/mapper/fix_unicode_mapper.py) | [tests](../tests/ops/mapper/test_fix_unicode_mapper.py) |
-| generate_qa_from_examples_mapper |      | 根据种子数据,生成新的对话样本。 | [code](../data_juicer/ops/mapper/generate_qa_from_examples_mapper.py) | [tests](../tests/ops/mapper/test_generate_qa_from_examples_mapper.py) |
-| generate_qa_from_text_mapper |      | 从文本中生成问答对 | [code](../data_juicer/ops/mapper/generate_qa_from_text_mapper.py) | [tests](../tests/ops/mapper/test_generate_qa_from_text_mapper.py) |
-| image_blur_mapper |  | 对图像进行模糊处理 | [code](../data_juicer/ops/mapper/image_blur_mapper.py) | [tests](../tests/ops/mapper/test_image_blur_mapper.py) |
-| image_captioning_from_gpt4v_mapper |  | 基于gpt-4-vision和图像生成文本 | [code](../data_juicer/ops/mapper/image_captioning_from_gpt4v_mapper.py) | - |
-| image_captioning_mapper |   | 生成样本,其标题是根据另一个辅助模型(例如 blip2)和原始样本中的图形生成的。 | [code](../data_juicer/ops/mapper/image_captioning_mapper.py) | [tests](../tests/ops/mapper/test_image_captioning_mapper.py) |
-| image_diffusion_mapper |   | 用stable diffusion生成图像,对图像进行增强 | [code](../data_juicer/ops/mapper/image_diffusion_mapper.py) | [tests](../tests/ops/mapper/test_image_diffusion_mapper.py) |
-| image_face_blur_mapper |  | 对图像中的人脸进行模糊处理 | [code](../data_juicer/ops/mapper/image_face_blur_mapper.py) | [tests](../tests/ops/mapper/test_image_face_blur_mapper.py) |
-| image_tagging_mapper |   | 从输入图片中生成图片标签 | [code](../data_juicer/ops/mapper/image_tagging_mapper.py) | [tests](../tests/ops/mapper/test_image_tagging_mapper.py) |
-| nlpaug_en_mapper |    | 使用`nlpaug`库对英语文本进行简单增强 | [code](../data_juicer/ops/mapper/nlpaug_en_mapper.py) | [tests](../tests/ops/mapper/test_nlpaug_en_mapper.py) |
-| nlpcda_zh_mapper |    | 使用`nlpcda`库对中文文本进行简单增强 | [code](../data_juicer/ops/mapper/nlpcda_zh_mapper.py) | [tests](../tests/ops/mapper/test_nlpcda_zh_mapper.py) |
-| optimize_qa_mapper |      | 指令优化,优化问题和答案 | [code](../data_juicer/ops/mapper/optimize_qa_mapper.py) | [tests](../tests/ops/mapper/test_optimize_qa_mapper.py) |
-| optimize_query_mapper |      | 指令优化,优化 query | [code](../data_juicer/ops/mapper/optimize_query_mapper.py) | [tests](../tests/ops/mapper/test_optimize_query_mapper.py) |
-| optimize_response_mapper |      | 指令优化,优化 response | [code](../data_juicer/ops/mapper/optimize_response_mapper.py) | [tests](../tests/ops/mapper/test_optimize_response_mapper.py) |
-| pair_preference_mapper |     | 构造配对的偏好样本 | [code](../data_juicer/ops/mapper/pair_preference_mapper.py) | [tests](../tests/ops/mapper/test_pair_preference_mapper.py) |
-| punctuation_normalization_mapper |     | 将各种 Unicode 标点符号标准化为其 ASCII 等效项 | [code](../data_juicer/ops/mapper/punctuation_normalization_mapper.py) | [tests](../tests/ops/mapper/test_punctuation_normalization_mapper.py) |
-| python_file_mapper |     | 执行文件中定义的 Python 函数处理样本 | [code](../data_juicer/ops/mapper/python_file_mapper.py) | [tests](../tests/ops/mapper/test_python_file_mapper.py) |
-| python_lambda_mapper |     | 执行 Python lambda 函数处理样本 | [code](../data_juicer/ops/mapper/python_lambda_mapper.py) | [tests](../tests/ops/mapper/test_python_lambda_mapper.py) |
-| query_intent_detection_mapper |     | 预测用户查询中的意图标签。 | [code](../data_juicer/ops/mapper/query_intent_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_intent_detection_mapper.py) |
-| query_sentiment_detection_mapper |     | 预测用户查询中的情感强度标签('negative'、'neutral'和'positive')。 | [code](../data_juicer/ops/mapper/query_sentiment_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_sentiment_detection_mapper.py) |
-| query_topic_detection_mapper |     | 预测用户查询中的话题标签。 | [code](../data_juicer/ops/mapper/query_topic_detection_mapper.py) | [tests](../tests/ops/mapper/test_query_topic_detection_mapper.py) |
-| relation_identity_mapper |     | 识别一段文本中两个实体之间的关系 | [code](../data_juicer/ops/mapper/relation_identity_mapper.py) | [tests](../tests/ops/mapper/test_relation_identity_mapper.py) |
-| remove_bibliography_mapper |     | 删除 TeX 文档的参考文献 | [code](../data_juicer/ops/mapper/remove_bibliography_mapper.py) | [tests](../tests/ops/mapper/test_remove_bibliography_mapper.py) |
-| remove_comments_mapper |     | 删除 TeX 文档中的注释 | [code](../data_juicer/ops/mapper/remove_comments_mapper.py) | [tests](../tests/ops/mapper/test_remove_comments_mapper.py) |
-| remove_header_mapper |     | 删除 TeX 文档头,例如标题、章节数字/名称等 | [code](../data_juicer/ops/mapper/remove_header_mapper.py) | [tests](../tests/ops/mapper/test_remove_header_mapper.py) |
-| remove_long_words_mapper |     | 删除长度超出指定范围的单词 | [code](../data_juicer/ops/mapper/remove_long_words_mapper.py) | [tests](../tests/ops/mapper/test_remove_long_words_mapper.py) |
-| remove_non_chinese_character_mapper |     | 删除样本中的非中文字符 | [code](../data_juicer/ops/mapper/remove_non_chinese_character_mapper.py) | [tests](../tests/ops/mapper/test_remove_non_chinese_character_mapper.py) |
-| remove_repeat_sentences_mapper |     | 删除样本中的重复句子 | [code](../data_juicer/ops/mapper/remove_repeat_sentences_mapper.py) | [tests](../tests/ops/mapper/test_remove_repeat_sentences_mapper.py) |
-| remove_specific_chars_mapper |     | 删除任何用户指定的字符或子字符串 | [code](../data_juicer/ops/mapper/remove_specific_chars_mapper.py) | [tests](../tests/ops/mapper/test_remove_specific_chars_mapper.py) |
-| remove_table_text_mapper |     | 检测并删除可能的表格内容(:warning: 依赖正则表达式匹配,因此很脆弱) | [code](../data_juicer/ops/mapper/remove_table_text_mapper.py) | [tests](../tests/ops/mapper/test_remove_table_text_mapper.py) |
-| remove_words_with_incorrect_ substrings_mapper |     | 删除包含指定子字符串的单词 | [code](../data_juicer/ops/mapper/remove_words_with_incorrect_substrings_mapper.py) | [tests](../tests/ops/mapper/test_remove_words_with_incorrect_substrings_mapper.py) |
-| replace_content_mapper |     | 使用一个指定的替换字符串替换文本中满足特定正则表达式模版的所有内容 | [code](../data_juicer/ops/mapper/replace_content_mapper.py) | [tests](../tests/ops/mapper/test_replace_content_mapper.py) |
-| sentence_split_mapper |    | 根据语义拆分和重组句子 | [code](../data_juicer/ops/mapper/sentence_split_mapper.py) | [tests](../tests/ops/mapper/test_sentence_split_mapper.py) |
-| text_chunk_mapper |     | 对文本进行分片处理 | [code](../data_juicer/ops/mapper/text_chunk_mapper.py) | [tests](../tests/ops/mapper/test_text_chunk_mapper.py) |
-| video_captioning_from_audio_mapper |   | 基于 Qwen-Audio 模型根据视频的音频流为视频生成新的标题描述 | [code](../data_juicer/ops/mapper/video_captioning_from_audio_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_audio_mapper.py) |
-| video_captioning_from_frames_mapper |   | 生成样本,其标题是基于一个文字生成图片的模型和原始样本视频中指定帧的图像。不同帧产出的标题会拼接为一条单独的字符串。 | [code](../data_juicer/ops/mapper/video_captioning_from_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_frames_mapper.py) |
-| video_captioning_from_summarizer_mapper |   | 通过对多种不同方式生成的文本进行摘要以生成样本的标题(从视频/音频/帧生成标题,从音频/帧生成标签,...) | [code](../data_juicer/ops/mapper/video_captioning_from_summarizer_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_summarizer_mapper.py) |
-| video_captioning_from_video_mapper |   | 生成样本,其标题是根据另一个辅助模型(video-blip)和原始样本中的视频中指定帧的图像。 | [code](../data_juicer/ops/mapper/video_captioning_from_video_mapper.py) | [tests](../tests/ops/mapper/test_video_captioning_from_video_mapper.py) |
-| video_extract_frames_mapper |   | 从视频中抽帧。 | [code](../data_juicer/ops/mapper/video_extract_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_extract_frames_mapper.py) |
-| video_face_blur_mapper |  | 对视频中的人脸进行模糊处理 | [code](../data_juicer/ops/mapper/video_face_blur_mapper.py) | [tests](../tests/ops/mapper/test_video_face_blur_mapper.py) |
-| video_ffmpeg_wrapped_mapper |  | 运行 FFmpeg 视频过滤器的简单封装 | [code](../data_juicer/ops/mapper/video_ffmpeg_wrapped_mapper.py) | [tests](../tests/ops/mapper/test_video_ffmpeg_wrapped_mapper.py) |
-| video_remove_watermark_mapper |  | 去除视频中给定区域的水印 | [code](../data_juicer/ops/mapper/video_remove_watermark_mapper.py) | [tests](../tests/ops/mapper/test_video_remove_watermark_mapper.py) |
-| video_resize_aspect_ratio_mapper |  | 将视频的宽高比调整到指定范围内 | [code](../data_juicer/ops/mapper/video_resize_aspect_ratio_mapper.py) | [tests](../tests/ops/mapper/test_video_resize_aspect_ratio_mapper.py) |
-| video_resize_resolution_mapper |  | 将视频映射到给定的分辨率区间 | [code](../data_juicer/ops/mapper/video_resize_resolution_mapper.py) | [tests](../tests/ops/mapper/test_video_resize_resolution_mapper.py) |
-| video_split_by_duration_mapper |  | 根据时长将视频切分为多个片段 | [code](../data_juicer/ops/mapper/video_split_by_duration_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_duration_mapper.py) |
-| video_split_by_key_frame_mapper |  | 根据关键帧切分视频 | [code](../data_juicer/ops/mapper/video_split_by_key_frame_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_key_frame_mapper.py) |
-| video_split_by_scene_mapper |  | 将视频切分为场景片段 | [code](../data_juicer/ops/mapper/video_split_by_scene_mapper.py) | [tests](../tests/ops/mapper/test_video_split_by_scene_mapper.py) |
-| video_tagging_from_audio_mapper |   | 从视频提取的音频中生成视频标签 | [code](../data_juicer/ops/mapper/video_tagging_from_audio_mapper.py) | [tests](../tests/ops/mapper/test_video_tagging_from_audio_mapper.py) |
-| video_tagging_from_frames_mapper |   | 从视频提取的帧中生成视频标签 | [code](../data_juicer/ops/mapper/video_tagging_from_frames_mapper.py) | [tests](../tests/ops/mapper/test_video_tagging_from_frames_mapper.py) |
-| whitespace_normalization_mapper |     | 将各种 Unicode 空白标准化为常规 ASCII 空格 (U+0020) | [code](../data_juicer/ops/mapper/whitespace_normalization_mapper.py) | [tests](../tests/ops/mapper/test_whitespace_normalization_mapper.py) |
-
-## Filter
-
-| 算子 | 标签 | 描述 | 源码 | 单测样例 |
-|-------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------|--------------------------------------------------------------------------|--------------------------------------------------------------------------|
-| alphanumeric_filter |     | 保留字母数字比例在指定范围内的样本 | [code](../data_juicer/ops/filter/alphanumeric_filter.py) | [tests](../tests/ops/filter/test_alphanumeric_filter.py) |
-| audio_duration_filter |  | 保留包含音频的时长在指定范围内的样本 | [code](../data_juicer/ops/filter/audio_duration_filter.py) | [tests](../tests/ops/filter/test_audio_duration_filter.py) |
-| audio_nmf_snr_filter |  | 保留包含音频信噪比SNR(基于非负矩阵分解方法NMF计算)在指定范围内的样本 | [code](../data_juicer/ops/filter/audio_nmf_snr_filter.py) | [tests](../tests/ops/filter/test_audio_nmf_snr_filter.py) |
-| audio_size_filter |  | 保留包含音频的大小(bytes)在指定范围内的样本 | [code](../data_juicer/ops/filter/audio_size_filter.py) | [tests](../tests/ops/filter/test_audio_size_filter.py) |
-| average_line_length_filter |     | 保留平均行长度在指定范围内的样本 | [code](../data_juicer/ops/filter/average_line_length_filter.py) | [tests](../tests/ops/filter/test_average_line_length_filter.py) |
-| character_repetition_filter |     | 保留 char-level n-gram 重复比率在指定范围内的样本 | [code](../data_juicer/ops/filter/character_repetition_filter.py) | [tests](../tests/ops/filter/test_character_repetition_filter.py) |
-| flagged_words_filter |     | 保留使标记字比率保持在指定阈值以下的样本 | [code](../data_juicer/ops/filter/flagged_words_filter.py) | [tests](../tests/ops/filter/test_flagged_words_filter.py) |
-| image_aesthetics_filter |   | 保留包含美学分数在指定范围内的图像的样本 | [code](../data_juicer/ops/filter/image_aesthetics_filter.py) | [tests](../tests/ops/filter/test_image_aesthetics_filter.py) |
-| image_aspect_ratio_filter |  | 保留样本中包含的图片的宽高比在指定范围内的样本 | [code](../data_juicer/ops/filter/image_aspect_ratio_filter.py) | [tests](../tests/ops/filter/test_image_aspect_ratio_filter.py) |
-| image_face_count_filter |  | 保留样本中包含的图片中检测到的人脸数目在指定范围内的样本 | [code](../data_juicer/ops/filter/image_face_count_filter.py) | [tests](../tests/ops/filter/test_image_face_count_filter.py) |
-| image_face_ratio_filter |  | 保留样本中包含的图片的最大脸部区域在指定范围内的样本 | [code](../data_juicer/ops/filter/image_face_ratio_filter.py) | [tests](../tests/ops/filter/test_image_face_ratio_filter.py) |
-| image_nsfw_filter |   | 保留包含NSFW分数在指定阈值之下的图像的样本 | [code](../data_juicer/ops/filter/image_nsfw_filter.py) | [tests](../tests/ops/filter/test_image_nsfw_filter.py) |
-| image_pair_similarity_filter |   | 保留图像特征余弦相似度(基于CLIP模型)在指定范围内的样本 | [code](../data_juicer/ops/filter/image_pair_similarity_filter.py) | [tests](../tests/ops/filter/test_image_pair_similarity_filter.py) |
-| image_shape_filter |  | 保留样本中包含的图片的形状(即宽和高)在指定范围内的样本 | [code](../data_juicer/ops/filter/image_shape_filter.py) | [tests](../tests/ops/filter/test_image_shape_filter.py) |
-| image_size_filter |  | 保留样本中包含的图片的大小(bytes)在指定范围内的样本 | [code](../data_juicer/ops/filter/image_size_filter.py) | [tests](../tests/ops/filter/test_image_size_filter.py) |
-| image_text_matching_filter |   | 保留图像-文本的分类匹配分(基于BLIP模型)在指定范围内的样本 | [code](../data_juicer/ops/filter/image_text_matching_filter.py) | [tests](../tests/ops/filter/test_image_text_matching_filter.py) |
-| image_text_similarity_filter |   | 保留图像-文本的特征余弦相似度(基于CLIP模型)在指定范围内的样本 | [code](../data_juicer/ops/filter/image_text_similarity_filter.py) | [tests](../tests/ops/filter/test_image_text_similarity_filter.py) |
-| image_watermark_filter |   | 保留包含有水印概率在指定阈值之下的图像的样本 | [code](../data_juicer/ops/filter/image_watermark_filter.py) | [tests](../tests/ops/filter/test_image_watermark_filter.py) |
-| language_id_score_filter |     | 保留特定语言的样本,通过预测的置信度得分来判断 | [code](../data_juicer/ops/filter/language_id_score_filter.py) | [tests](../tests/ops/filter/test_language_id_score_filter.py) |
-| maximum_line_length_filter |     | 保留最大行长度在指定范围内的样本 | [code](../data_juicer/ops/filter/maximum_line_length_filter.py) | [tests](../tests/ops/filter/test_maximum_line_length_filter.py) |
-| perplexity_filter |     | 保留困惑度低于指定阈值的样本 | [code](../data_juicer/ops/filter/perplexity_filter.py) | [tests](../tests/ops/filter/test_perplexity_filter.py) |
-| phrase_grounding_recall_filter |   | 保留从文本中提取的名词短语在图像中的定位召回率在一定范围内的样本 | [code](../data_juicer/ops/filter/phrase_grounding_recall_filter.py) | [tests](../tests/ops/filter/test_phrase_grounding_recall_filter.py) |
-| special_characters_filter |     | 保留 special-char 比率的在指定范围内的样本 | [code](../data_juicer/ops/filter/special_characters_filter.py) | [tests](../tests/ops/filter/test_special_characters_filter.py) |
-| specified_field_filter |     | 根据字段过滤样本,要求字段的值处于指定目标中 | [code](../data_juicer/ops/filter/specified_field_filter.py) | [tests](../tests/ops/filter/test_specified_field_filter.py) |
-| specified_numeric_field_filter |     | 根据字段过滤样本,要求字段的值处于指定范围(针对数字类型) | [code](../data_juicer/ops/filter/specified_numeric_field_filter.py) | [tests](../tests/ops/filter/test_specified_numeric_field_filter.py) |
-| stopwords_filter |     | 保留停用词比率高于指定阈值的样本 | [code](../data_juicer/ops/filter/stopwords_filter.py) | [tests](../tests/ops/filter/test_stopwords_filter.py) |
-| suffix_filter |    | 保留包含特定后缀的样本 | [code](../data_juicer/ops/filter/suffix_filter.py) | [tests](../tests/ops/filter/test_suffix_filter.py) |
-| text_action_filter |     | 保留文本部分包含动作的样本 | [code](../data_juicer/ops/filter/text_action_filter.py) | [tests](../tests/ops/filter/test_text_action_filter.py) |
-| text_entity_dependency_filter |     | 保留文本部分的依存树中具有非独立实体的样本 | [code](../data_juicer/ops/filter/text_entity_dependency_filter.py) | [tests](../tests/ops/filter/test_text_entity_dependency_filter.py) |
-| text_length_filter |     | 保留总文本长度在指定范围内的样本 | [code](../data_juicer/ops/filter/text_length_filter.py) | [tests](../tests/ops/filter/test_text_length_filter.py) |
-| token_num_filter |      | 保留token数在指定范围内的样本 | [code](../data_juicer/ops/filter/token_num_filter.py) | [tests](../tests/ops/filter/test_token_num_filter.py) |
-| video_aesthetics_filter |   | 保留指定帧的美学分数在指定范围内的样本 | [code](../data_juicer/ops/filter/video_aesthetics_filter.py) | [tests](../tests/ops/filter/test_video_aesthetics_filter.py) |
-| video_aspect_ratio_filter |  | 保留包含视频的宽高比在指定范围内的样本 | [code](../data_juicer/ops/filter/video_aspect_ratio_filter.py) | [tests](../tests/ops/filter/test_video_aspect_ratio_filter.py) |
-| video_duration_filter |  | 保留包含视频的时长在指定范围内的样本 | [code](../data_juicer/ops/filter/video_duration_filter.py) | [tests](../tests/ops/filter/test_video_duration_filter.py) |
-| video_frames_text_similarity_filter |   | 保留视频中指定帧的图像-文本的特征余弦相似度(基于CLIP模型)在指定范围内的样本 | [code](../data_juicer/ops/filter/video_frames_text_similarity_filter.py) | [tests](../tests/ops/filter/test_video_frames_text_similarity_filter.py) |
-| video_motion_score_filter |  | 保留包含视频的运动分数(基于稠密光流)在指定范围内的样本 | [code](../data_juicer/ops/filter/video_motion_score_filter.py) | [tests](../tests/ops/filter/test_video_motion_score_filter.py) |
-| video_motion_score_raft_filter |  | 保留包含视频的运动分数(基于 RAFT 模型估计的稠密光流)在指定范围内的样本 | [code](../data_juicer/ops/filter/video_motion_score_raft_raft_filter.py) | [tests](../tests/ops/filter/test_video_motion_score_filter.py) |
-| video_nsfw_filter |   | 保留包含视频的NSFW分数在指定阈值之下的样本 | [code](../data_juicer/ops/filter/video_nsfw_filter.py) | [tests](../tests/ops/filter/test_video_nsfw_filter.py) |
-| video_ocr_area_ratio_filter |   | 保留包含视频的特定帧中检测出的文本的面积占比在指定范围内的样本 | [code](../data_juicer/ops/filter/video_ocr_area_ratio_filter.py) | [tests](../tests/ops/filter/test_video_ocr_area_ratio_filter.py) |
-| video_resolution_filter |  | 保留包含视频的分辨率(包括横向分辨率和纵向分辨率)在指定范围内的样本 | [code](../data_juicer/ops/filter/video_resolution_filter.py) | [tests](../tests/ops/filter/test_video_resolution_filter.py) |
-| video_watermark_filter |   | 保留包含视频有水印的概率在指定阈值之下的样本 | [code](../data_juicer/ops/filter/video_watermark_filter.py) | [tests](../tests/ops/filter/test_video_watermark_filter.py) |
-| video_tagging_from_frames_filter |   | 保留包含具有给定标签视频的样本 | [code](../data_juicer/ops/filter/video_tagging_from_frames_filter.py) | [tests](../tests/ops/filter/test_video_tagging_from_frames_filter.py) |
-| words_num_filter |     | 保留字数在指定范围内的样本 | [code](../data_juicer/ops/filter/words_num_filter.py) | [tests](../tests/ops/filter/test_words_num_filter.py) |
-| word_repetition_filter |     | 保留 word-level n-gram 重复比率在指定范围内的样本 | [code](../data_juicer/ops/filter/word_repetition_filter.py) | [tests](../tests/ops/filter/test_word_repetition_filter.py) |
-
-## Deduplicator
-
-| 算子 | 标签 | 描述 | 源码 | 单测样例 |
-|--------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------|--------------------------------------------------------------------------|--------------------------------------------------------------------------|
-| document_deduplicator |     | 通过比较 MD5 哈希值在文档级别对样本去重 | [code](../data_juicer/ops/deduplicator/document_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_deduplicator.py) |
-| document_minhash_deduplicator |     | 使用 MinHashLSH 在文档级别对样本去重 | [code](../data_juicer/ops/deduplicator/document_minhash_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_minhash_deduplicator.py) |
-| document_simhash_deduplicator |     | 使用 SimHash 在文档级别对样本去重 | [code](../data_juicer/ops/deduplicator/document_simhash_deduplicator.py) | [tests](../tests/ops/deduplicator/test_document_simhash_deduplicator.py) |
-| image_deduplicator |  | 使用文档之间图像的精确匹配在文档级别删除重复样本 | [code](../data_juicer/ops/deduplicator/image_deduplicator.py) | [tests](../tests/ops/deduplicator/test_image_deduplicator.py) |
-| video_deduplicator |  | 使用文档之间视频的精确匹配在文档级别删除重复样本 | [code](../data_juicer/ops/deduplicator/video_deduplicator.py) | [tests](../tests/ops/deduplicator/test_video_deduplicator.py) |
-| ray_bts_minhash_deduplicator |     | 使用 MinHashLSH 在文档级别对样本去重,面向 RAY 分布式模式 | [code](../data_juicer/ops/deduplicator/ray_bts_minhash_deduplicator.py) | - |
-| ray_document_deduplicator |     | 通过比较 MD5 哈希值在文档级别对样本去重,面向RAY分布式模式 | [code](../data_juicer/ops/deduplicator/ray_document_deduplicator.py) | - |
-| ray_image_deduplicator |  | 使用文档之间图像的精确匹配在文档级别删除重复样本,面向RAY分布式模式 | [code](../data_juicer/ops/deduplicator/ray_image_deduplicator.py) | - |
-| ray_video_deduplicator |  | 使用文档之间视频的精确匹配在文档级别删除重复样本,面向RAY分布式模式 | [code](../data_juicer/ops/deduplicator/ray_video_deduplicator.py) | - |
-
-## Selector
-
-| 算子 | 标签 | 描述 | 源码 | 单测样例 |
-|-------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------|---------------------------------------------------------------------------|---------------------------------------------------------------------------|
-| frequency_specified_field_selector |    | 通过比较指定字段的频率选出前 k 个样本 | [code](../data_juicer/ops/selector/frequency_specified_field_selector.py) | [tests](../tests/ops/selector/test_frequency_specified_field_selector.py) |
-| random_selector |    | 随机筛选 k 个样本 | [code](../data_juicer/ops/selector/random_selector.py) | [tests](../tests/ops/selector/test_random_selector.py) |
-| range_specified_field_selector |    | 通过比较指定字段的值选出指定范围的 k 个样本 | [code](../data_juicer/ops/selector/range_specified_field_selector.py) | [tests](../tests/ops/selector/test_range_specified_field_selector.py) |
-| tags_specified_field_selector |    | 通过指定字段的标签值筛选样例 | [code](../data_juicer/ops/selector/tags_specified_field_selector.py) | [tests](../tests/ops/selector/test_tags_specified_field_selector.py) |
-| topk_specified_field_selector |    | 通过比较指定字段的值选出前 k 个样本 | [code](../data_juicer/ops/selector/topk_specified_field_selector.py) | [tests](../tests/ops/selector/test_topk_specified_field_selector.py) |
-
-## Grouper
-
-| 算子 | 标签 | 描述 | 源码 | 单测样例 |
-|-------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------|---------------------------------------------------------------------------|---------------------------------------------------------------------------|
-| naive_grouper |     | 将所有样本分为一个组,返回一个batch化的样本 | [code](../data_juicer/ops/grouper/naive_grouper.py) | [tests](../tests/ops/grouper/test_naive_grouper.py) |
-| naive_reverse_grouper |     | 将batch化的样本拆分成普通的样本 | [code](../data_juicer/ops/grouper/naive_reverse_grouper.py) | [tests](../tests/ops/grouper/test_naive_reverse_grouper.py) |
-| key_value_grouper |     | 根据给定键的值将样本分组,每一组组成一个批量样本。 | [code](../data_juicer/ops/grouper/key_value_grouper.py) | [tests](../tests/ops/grouper/test_key_value_grouper.py) |
-
-## Aggregator
-
-| 算子 | 标签 | 描述 | 源码 | 单测样例 |
-|-------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------|---------------------------------------------------------------------------|---------------------------------------------------------------------------|
-| entity_attribute_aggregator |     | 从一些文本中总结出给定实体的属性 | [code](../data_juicer/ops/aggregator/entity_attribute_aggregator.py) | [tests](../tests/ops/aggregator/test_entity_attribute_aggregator.py) |
-| meta_tags_aggregator |     | 将相似的标签合并成同一个标签。 | [code](../data_juicer/ops/aggregator/meta_tags_aggregator.py) | [tests](../tests/ops/aggregator/test_meta_tags_aggregator.py) |
-| most_relavant_entities_aggregator |     | 从一些文本中抽取出与给定实体密切相关的实体,按重要性从高到低排序 | [code](../data_juicer/ops/aggregator/most_relavant_entities_aggregator.py) | [tests](../tests/ops/aggregator/test_most_relavant_entities_aggregator.py) |
-| nested_aggregator |     | 考虑到输入长度的限制,对样本中的内容进行嵌套聚合。 | [code](../data_juicer/ops/aggregator/nested_aggregator.py) | [tests](../tests/ops/aggregator/test_nested_aggregator.py) |
-
-## 贡献
-我们欢迎社区贡献新的算子,具体请参考[开发者指南](DeveloperGuide_ZH.md)。
diff --git a/environments/dist_requires.txt b/environments/dist_requires.txt
index 90f28ef7a..2ec0908c7 100644
--- a/environments/dist_requires.txt
+++ b/environments/dist_requires.txt
@@ -1,2 +1,2 @@
-ray>=2.31.0
+ray==2.40.0
redis>=5.0.0
diff --git a/environments/sandbox_requires.txt b/environments/sandbox_requires.txt
index 6a1791cf8..5307bf111 100644
--- a/environments/sandbox_requires.txt
+++ b/environments/sandbox_requires.txt
@@ -18,5 +18,5 @@ imageio[ffmpeg]
imageio[pyav]
tensorboard
diffusers==0.27.0
-transformers==4.37.2
+transformers>=4.37.2
func_timeout
diff --git a/tests/ops/mapper/test_generate_qa_from_text_mapper.py b/tests/ops/mapper/test_generate_qa_from_text_mapper.py
index e67285b18..7b3131fd3 100644
--- a/tests/ops/mapper/test_generate_qa_from_text_mapper.py
+++ b/tests/ops/mapper/test_generate_qa_from_text_mapper.py
@@ -19,11 +19,13 @@ def _run_op(self,
enable_vllm=False,
model_params=None,
sampling_params=None,
- num_proc=1):
+ num_proc=1,
+ max_num=None):
op = GenerateQAFromTextMapper(enable_vllm=enable_vllm,
model_params=model_params,
- sampling_params=sampling_params)
+ sampling_params=sampling_params,
+ max_num=max_num)
samples = [{
self.text_key:
@@ -36,6 +38,9 @@ def _run_op(self,
dataset = Dataset.from_list(samples)
results = dataset.map(op.process, num_proc=num_proc, with_rank=True)
+ if max_num is not None:
+ self.assertLessEqual(len(results), len(samples)*max_num)
+
for row in results:
logger.info(row)
self.assertIn(op.query_key, row)
@@ -45,6 +50,10 @@ def test(self):
sampling_params = {'max_new_tokens': 200}
self._run_op(sampling_params=sampling_params)
+ def test_max_num(self):
+ sampling_params = {'max_new_tokens': 200}
+ self._run_op(sampling_params=sampling_params, max_num=1)
+
def test_multi_process(self):
sampling_params = {'max_new_tokens': 200}
self._run_op(sampling_params=sampling_params, num_proc=2)
diff --git a/tests/ops/selector/test_tags_specified_selector.py b/tests/ops/selector/test_tags_specified_field_selector.py
similarity index 100%
rename from tests/ops/selector/test_tags_specified_selector.py
rename to tests/ops/selector/test_tags_specified_field_selector.py
History News: +
> + -  [2024-08-09] 我们提出了Img-Diff,它通过*对比数据合成*来增强多模态大型语言模型的性能,在[MMVP benchmark](https://tsb0601.github.io/mmvp_blog/)中比GPT-4V高出12个点。 更多细节请参阅我们的 [论文](https://arxiv.org/abs/2408.04594), 以及从 [huggingface](https://huggingface.co/datasets/datajuicer/Img-Diff) 和 [modelscope](https://modelscope.cn/datasets/Data-Juicer/Img-Diff)下载这份数据集。 -  [2024-07-24] “天池 Better Synth 多模态大模型数据合成赛”——第四届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532251),了解赛事详情。 - [2024-07-17] 我们利用Data-Juicer[沙盒实验室套件](https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox-ZH.md),通过数据与模型间的系统性研发工作流,调优数据和模型,在[VBench](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard)文生视频排行榜取得了新的榜首。相关成果已经整理发表在[论文](http://arxiv.org/abs/2407.11784)中,并且模型已在[ModelScope](https://modelscope.cn/models/Data-Juicer/Data-Juicer-T2V)和[HuggingFace](https://huggingface.co/datajuicer/Data-Juicer-T2V)平台发布。 - [2024-07-12] 我们的MLLM-Data精选列表已经演化为一个模型-数据协同开发的角度系统性[综述](https://arxiv.org/abs/2407.08583)。欢迎[浏览](docs/awesome_llm_data.md)或参与贡献! -  [2024-06-01] ModelScope-Sora“数据导演”创意竞速——第三届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532219),了解赛事详情。 -
- bash
-## 数据处理菜谱
-
-* [BLOOM 数据处理菜谱](configs/reproduced_bloom/README_ZH.md)
-* [RedPajama 数据处理菜谱](configs/reproduced_redpajama/README_ZH.md)
-* [预训练文本数据增强菜谱](configs/data_juicer_recipes/README_ZH.md)
-* [Fine-tuning文本数据增强菜谱](configs/data_juicer_recipes/README_ZH.md#完善前后的alpaca-cot数据集)
-* [预训练多模态数据增强菜谱](configs/data_juicer_recipes/README_ZH.md#before-and-after-refining-for-multimodal-dataset)
-
## 开源协议
Data-Juicer 在 Apache License 2.0 协议下发布。
@@ -433,16 +443,13 @@ Data-Juicer 在 Apache License 2.0 协议下发布。
大模型是一个高速发展的领域,我们非常欢迎贡献新功能、修复漏洞以及文档改善。请参考[开发者指南](docs/DeveloperGuide_ZH.md)。
-如果您有任何问题,欢迎加入我们的[讨论群](README_ZH.md) 。
## 致谢
-Data-Juicer 被各种 LLM产品和研究工作使用,包括来自阿里云-通义的行业大模型,例如点金
-(金融分析),智文(阅读助手),还有阿里云人工智能平台 (PAI)。 我们期待更多您的体验反馈、建议和合作共建!
+Data-Juicer被许多大模型相关产品和研究工作所使用,例子阿里巴巴通义和阿里云人工智能平台 (PAI) 之上的工业界场景。 我们期待更多您的体验反馈、建议和合作共建!
-Data-Juicer 感谢并参考了社区开源项目:
-[Huggingface-Datasets](https://github.com/huggingface/datasets), [Bloom](https://huggingface.co/bigscience/bloom), [RedPajama](https://github.com/togethercomputer/RedPajama-Data/tree/rp_v1), [Pile](https://huggingface.co/datasets/EleutherAI/pile), [Alpaca-Cot](https://huggingface.co/datasets/QingyiSi/Alpaca-CoT), [Megatron-LM](https://github.com/NVIDIA/Megatron-LM), [DeepSpeed](https://www.deepspeed.ai/), [Arrow](https://github.com/apache/arrow), [Ray](https://github.com/ray-project/ray), [Beam](https://github.com/apache/beam), [LM-Harness](https://github.com/EleutherAI/lm-evaluation-harness), [HELM](https://github.com/stanford-crfm/helm), ....
+Data-Juicer 感谢社区[贡献者](https://github.com/modelscope/data-juicer/graphs/contributors) 和相关的先驱开源项目,譬如[Huggingface-Datasets](https://github.com/huggingface/datasets), [Bloom](https://huggingface.co/bigscience/bloom), [RedPajama](https://github.com/togethercomputer/RedPajama-Data/tree/rp_v1), [Arrow](https://github.com/apache/arrow), [Ray](https://github.com/ray-project/ray), ....
## 参考文献
如果您发现我们的工作对您的研发有帮助,请引用以下[论文](https://arxiv.org/abs/2309.02033) 。
@@ -459,12 +466,16 @@ Data-Juicer 感谢并参考了社区开源项目:
diff --git a/configs/config_all.yaml b/configs/config_all.yaml
index 0b3fdc87a..ade3442f4 100644
--- a/configs/config_all.yaml
+++ b/configs/config_all.yaml
@@ -257,6 +257,7 @@ process:
sampling_params: {} # Sampling parameters for text generation. e.g {'temperature': 0.9, 'top_p': 0.95}
- generate_qa_from_text_mapper: # mapper to generate question and answer pairs from text.
hf_model: 'alibaba-pai/pai-qwen1_5-7b-doc2qa' # Model name on huggingface to generate question and answer pairs.
+ max_num: null # The max num of returned QA sample for each text. Not limit if it is None.
output_pattern: null # Regular expression pattern to extract questions and answers from model response.
enable_vllm: false # Whether to use vllm for inference acceleration.
model_params: {} # Parameters for initializing the model.
@@ -784,15 +785,15 @@ process:
- video_deduplicator: # deduplicator to deduplicate samples at document-level using exact matching of videos between documents.
consider_text: false # whether to consider text hash together with video hash when applying deduplication.
- ray_video_deduplicator: # the simple video deduplicator that can run on multi-nodes using md5 hashing exact matching method
- redis_host: 'redis_host' # the host of the redis instance
- redis_port: 6380 # the port of redis instance, please note that the default port of redis is 6379 which is the same as default port for ray, so we need to modify the default redis config to use it in other port
+ backend: 'ray_actor' # the backend for dedup, either 'ray_actor' or 'redis'
+ redis_address: 'redis://localhost:6379' # the address of redis server
- ray_image_deduplicator: # the simple image deduplicator that can deduplicate samples at document-level using exact matching of images between documents.
- redis_host: 'redis_host' # the host of the redis instance
- redis_port: 6380 # the port of redis instance, please note that the default port of redis is 6379 which is the same as default port for ray, so we need to modify the default redis config to use it in other port
- method: phash # hash method for image. One of [phash, dhash, whash, ahash]
+ backend: 'ray_actor' # the backend for dedup, either 'ray_actor' or 'redis'
+ redis_address: 'redis://localhost:6379' # the address of redis server
+ method: phash # hash method for image. One of [phash, dhash, whash, ahash]
- ray_document_deduplicator: # the simple document deduplicator that can run on multi-nodes using md5 hashing exact matching method
- redis_host: 'redis_host' # the host of the redis instance
- redis_port: 6380 # the port of redis instance, please note that the default port of redis is 6379 which is the same as default port for ray, so we need to modify the default redis config to use it in other port
+ backend: 'ray_actor' # the backend for dedup, either 'ray_actor' or 'redis'
+ redis_address: 'redis://localhost:6379' # the address of redis server
lowercase: false # whether to convert text to lower case
ignore_non_character: false # whether to ignore non-alphabet characters, including whitespaces, digits, and punctuations
- ray_bts_minhash_deduplicator: # the document deduplicator that can run on multi-nodes using minhashLSH algorithm
diff --git a/data_juicer/__init__.py b/data_juicer/__init__.py
index 7b7173c37..e1cfd832d 100644
--- a/data_juicer/__init__.py
+++ b/data_juicer/__init__.py
@@ -1,4 +1,4 @@
-__version__ = '1.0.2'
+__version__ = '1.0.3'
import os
import subprocess
diff --git a/data_juicer/core/data.py b/data_juicer/core/data.py
index d0f8083e1..f9af23f00 100644
--- a/data_juicer/core/data.py
+++ b/data_juicer/core/data.py
@@ -21,6 +21,7 @@
cleanup_compressed_cache_files,
compress, decompress)
from data_juicer.utils.fingerprint_utils import generate_fingerprint
+from data_juicer.utils.logger_utils import make_log_summarization
from data_juicer.utils.process_utils import setup_mp
@@ -258,6 +259,9 @@ def process(
if work_dir and enable_insight_mining:
logger.info('Insight mining for each OP...')
adapter.insight_mining()
+ # make summarization on the error/warning logs
+ if work_dir:
+ make_log_summarization()
return dataset
def update_args(self, args, kargs, is_filter=False):
diff --git a/data_juicer/core/ray_data.py b/data_juicer/core/ray_data.py
index b77ed4e69..64ab7b310 100644
--- a/data_juicer/core/ray_data.py
+++ b/data_juicer/core/ray_data.py
@@ -10,12 +10,13 @@
from data_juicer import cuda_device_count
from data_juicer.core.data import DJDataset
from data_juicer.ops import Deduplicator, Filter, Mapper
+from data_juicer.ops.base_op import TAGGING_OPS
from data_juicer.utils.constant import Fields
from data_juicer.utils.lazy_loader import LazyLoader
from data_juicer.utils.process_utils import calculate_np
rd = LazyLoader('rd', 'ray.data')
-ds = LazyLoader('ds', 'ray.data.datasource')
+ds = LazyLoader('ds', 'ray.data.read_api')
def get_abs_path(path, dataset_dir):
@@ -108,6 +109,18 @@ def _run_single_op(self, op):
op_proc = calculate_np(op._name, op.mem_required, op.cpu_required,
self.num_proc, op.use_cuda())
num_gpus = get_num_gpus(op, op_proc)
+
+ if (op._name in TAGGING_OPS.modules
+ and Fields.meta not in self.data.columns()):
+
+ def process_batch_arrow(table: pyarrow.Table):
+ new_column_data = [{} for _ in range(len(table))]
+ new_talbe = table.append_column(Fields.meta, [new_column_data])
+ return new_talbe
+
+ self.data = self.data.map_batches(process_batch_arrow,
+ batch_format='pyarrow')
+
try:
batch_size = getattr(op, 'batch_size',
1) if op.is_batched_op() else 1
@@ -235,7 +248,7 @@ def read_json_stream(
arrow_open_stream_args: Optional[Dict[str, Any]] = None,
meta_provider=None,
partition_filter=None,
- partitioning=ds.partitioning.Partitioning('hive'),
+ partitioning=ds.Partitioning('hive'),
include_paths: bool = False,
ignore_missing_paths: bool = False,
shuffle: Union[Literal['files'], None] = None,
@@ -245,7 +258,7 @@ def read_json_stream(
**arrow_json_args,
) -> rd.Dataset:
if meta_provider is None:
- meta_provider = ds.file_meta_provider.DefaultFileMetadataProvider()
+ meta_provider = ds.DefaultFileMetadataProvider()
datasource = JSONStreamDatasource(
paths,
diff --git a/data_juicer/ops/aggregator/most_relavant_entities_aggregator.py b/data_juicer/ops/aggregator/most_relavant_entities_aggregator.py
index be585f44f..4f69b53d2 100644
--- a/data_juicer/ops/aggregator/most_relavant_entities_aggregator.py
+++ b/data_juicer/ops/aggregator/most_relavant_entities_aggregator.py
@@ -1,6 +1,7 @@
import re
from typing import Dict, Optional
+import numpy as np
from loguru import logger
from pydantic import PositiveInt
@@ -151,12 +152,13 @@ def query_most_relavant_entities(self, sub_docs, rank=None):
'role': 'user',
'content': input_prompt
}]
- result = []
+ result = np.array([], dtype=str)
for i in range(self.try_num):
try:
response = model(messages, **self.sampling_params)
- result = self.parse_output(response)
- if len(result) > 0:
+ cur_result = self.parse_output(response)
+ if len(cur_result) > 0:
+ result = cur_result
break
except Exception as e:
logger.warning(f'Exception: {e}')
diff --git a/data_juicer/ops/base_op.py b/data_juicer/ops/base_op.py
index 615b448ef..58efbbb5e 100644
--- a/data_juicer/ops/base_op.py
+++ b/data_juicer/ops/base_op.py
@@ -1,5 +1,4 @@
import copy
-import traceback
from functools import wraps
import numpy as np
@@ -48,11 +47,14 @@ def wrapper(sample, *args, **kwargs):
return wrapper
-def catch_map_batches_exception(method, skip_op_error=False):
+def catch_map_batches_exception(method, skip_op_error=False, op_name=None):
"""
For batched-map sample-level fault tolerance.
"""
+ if op_name is None:
+ op_name = method.__name__
+
@wraps(method)
@convert_arrow_to_python
def wrapper(samples, *args, **kwargs):
@@ -62,10 +64,8 @@ def wrapper(samples, *args, **kwargs):
if not skip_op_error:
raise
from loguru import logger
- logger.error(
- f'An error occurred in mapper operation when processing '
- f'samples {samples}, {type(e)}: {e}')
- traceback.print_exc()
+ logger.error(f'An error occurred in {op_name} when processing '
+ f'samples "{samples}" -- {type(e)}: {e}')
ret = {key: [] for key in samples.keys()}
ret[Fields.stats] = []
ret[Fields.source_file] = []
@@ -76,12 +76,16 @@ def wrapper(samples, *args, **kwargs):
def catch_map_single_exception(method,
return_sample=True,
- skip_op_error=False):
+ skip_op_error=False,
+ op_name=None):
"""
For single-map sample-level fault tolerance.
The input sample is expected batch_size = 1.
"""
+ if op_name is None:
+ op_name = method.__name__
+
def is_batched(sample):
val_iter = iter(sample.values())
first_val = next(val_iter)
@@ -107,10 +111,8 @@ def wrapper(sample, *args, **kwargs):
if skip_op_error:
raise
from loguru import logger
- logger.error(
- f'An error occurred in mapper operation when processing '
- f'sample {sample}, {type(e)}: {e}')
- traceback.print_exc()
+ logger.error(f'An error occurred in {op_name} when processing '
+ f'sample "{sample}" -- {type(e)}: {e}')
ret = {key: [] for key in sample.keys()}
ret[Fields.stats] = []
ret[Fields.source_file] = []
@@ -288,10 +290,14 @@ def __init__(self, *args, **kwargs):
# runtime wrappers
if self.is_batched_op():
self.process = catch_map_batches_exception(
- self.process_batched, skip_op_error=self.skip_op_error)
+ self.process_batched,
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
else:
self.process = catch_map_single_exception(
- self.process_single, skip_op_error=self.skip_op_error)
+ self.process_single,
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
# set the process method is not allowed to be overridden
def __init_subclass__(cls, **kwargs):
@@ -378,16 +384,23 @@ def __init__(self, *args, **kwargs):
# runtime wrappers
if self.is_batched_op():
self.compute_stats = catch_map_batches_exception(
- self.compute_stats_batched, skip_op_error=self.skip_op_error)
+ self.compute_stats_batched,
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
self.process = catch_map_batches_exception(
- self.process_batched, skip_op_error=self.skip_op_error)
+ self.process_batched,
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
else:
self.compute_stats = catch_map_single_exception(
- self.compute_stats_single, skip_op_error=self.skip_op_error)
+ self.compute_stats_single,
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
self.process = catch_map_single_exception(
self.process_single,
return_sample=False,
- skip_op_error=self.skip_op_error)
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
# set the process method is not allowed to be overridden
def __init_subclass__(cls, **kwargs):
@@ -497,10 +510,14 @@ def __init__(self, *args, **kwargs):
# runtime wrappers
if self.is_batched_op():
self.compute_hash = catch_map_batches_exception(
- self.compute_hash, skip_op_error=self.skip_op_error)
+ self.compute_hash,
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
else:
self.compute_hash = catch_map_single_exception(
- self.compute_hash, skip_op_error=self.skip_op_error)
+ self.compute_hash,
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
def compute_hash(self, sample):
"""
@@ -637,7 +654,9 @@ def __init__(self, *args, **kwargs):
"""
super(Aggregator, self).__init__(*args, **kwargs)
self.process = catch_map_single_exception(
- self.process_single, skip_op_error=self.skip_op_error)
+ self.process_single,
+ skip_op_error=self.skip_op_error,
+ op_name=self._name)
def process_single(self, sample):
"""
diff --git a/data_juicer/ops/common/helper_func.py b/data_juicer/ops/common/helper_func.py
index 644188a7a..e30872ad8 100644
--- a/data_juicer/ops/common/helper_func.py
+++ b/data_juicer/ops/common/helper_func.py
@@ -213,4 +213,7 @@ def split_text_by_punctuation(text):
result = re.split(punctuation_pattern, text)
result = [s.strip() for s in result if s.strip()]
+ if not result:
+ return [text]
+
return result
diff --git a/data_juicer/ops/deduplicator/ray_basic_deduplicator.py b/data_juicer/ops/deduplicator/ray_basic_deduplicator.py
index dad317d17..72b777d86 100644
--- a/data_juicer/ops/deduplicator/ray_basic_deduplicator.py
+++ b/data_juicer/ops/deduplicator/ray_basic_deduplicator.py
@@ -1,4 +1,6 @@
-from pydantic import PositiveInt
+from abc import ABC, abstractmethod
+
+import ray
from data_juicer.utils.constant import HashKeys
from data_juicer.utils.lazy_loader import LazyLoader
@@ -7,6 +9,69 @@
redis = LazyLoader('redis', 'redis')
+MERSENNE_PRIME = (1 << 61) - 1
+
+
+@ray.remote(scheduling_strategy='SPREAD')
+class DedupSet:
+
+ def __init__(self):
+ self.hash_record = set()
+
+ def is_unique(self, key):
+ if key not in self.hash_record:
+ self.hash_record.add(key)
+ return True
+ else:
+ return False
+
+
+class Backend(ABC):
+ """
+ Backend for deduplicator.
+ """
+
+ @abstractmethod
+ def __init__(self, *args, **kwargs):
+ pass
+
+ @abstractmethod
+ def is_unique(self, md5_value: str):
+ pass
+
+
+class ActorBackend(Backend):
+ """
+ Ray actor backend for deduplicator.
+ """
+
+ def __init__(self, dedup_set_num: int):
+ self.dedup_set_num = dedup_set_num
+ self.dedup_sets = [
+ DedupSet.remote() for _ in range(self.dedup_set_num)
+ ]
+
+ def is_unique(self, md5_value: str):
+ dedup_set_id = int.from_bytes(
+ md5_value.encode(),
+ byteorder='little') % MERSENNE_PRIME % self.dedup_set_num
+ return ray.get(
+ self.dedup_sets[dedup_set_id].is_unique.remote(md5_value))
+
+
+class RedisBackend(Backend):
+ """
+ Redis backend for deduplicator.
+ """
+
+ def __init__(self, redis_address: str):
+ self.redis_address = redis_address
+ self.redis_client = redis.from_url(url=self.redis_address)
+ self.redis_client.flushdb(0)
+
+ def is_unique(self, md5_value: str):
+ return self.redis_client.setnx(md5_value, 1)
+
class RayBasicDeduplicator(Filter):
"""
@@ -19,37 +84,40 @@ class RayBasicDeduplicator(Filter):
EMPTY_HASH_VALUE = 'EMPTY'
def __init__(self,
- redis_host: str = 'localhost',
- redis_port: PositiveInt = 6380,
+ backend: str = 'ray_actor',
+ redis_address: str = 'redis://localhost:6379',
*args,
**kwargs):
"""
Initialization.
- :param redis_host: the hostname of redis server
- :param redis_port: the port of redis server
+ :param backend: the backend for dedup, either 'ray_actor' or 'redis'
+ :param redis_address: the address of redis server
:param args: extra args
:param kwargs: extra args
"""
super().__init__(*args, **kwargs)
- self.redis_host = redis_host
- self.redis_port = redis_port
- # TODO: add a barrier to ensure that flushdb is performed before
- # the operator is called
- r = redis.StrictRedis(host=self.redis_host, port=self.redis_port, db=0)
- r.flushdb(0)
+ self.redis_address = redis_address
+ self.backend = backend
+ if backend == 'ray_actor':
+ dedup_set_num = int(ray.cluster_resources().get('CPU') / 2)
+ self.backend = ActorBackend(dedup_set_num)
+ elif backend == 'redis':
+ # TODO: add a barrier to ensure that flushdb is performed before
+ # the operator is called
+ self.backend = RedisBackend(redis_address)
+ else:
+ raise ValueError(f'Unknown backend: {backend}')
def calculate_hash(self, sample, context=False):
"""Calculate hash value for the sample."""
raise NotImplementedError
def compute_stats_single(self, sample, context=False):
- # init redis client
- r = redis.StrictRedis(host=self.redis_host, port=self.redis_port, db=0)
# compute hash
md5_value = self.calculate_hash(sample, context)
# check existing
- sample[HashKeys.is_duplicate] = r.setnx(md5_value, 1)
+ sample[HashKeys.is_unique] = self.backend.is_unique(md5_value)
return sample
def process_single(self, sample):
- return sample[HashKeys.is_duplicate]
+ return sample[HashKeys.is_unique]
diff --git a/data_juicer/ops/deduplicator/ray_document_deduplicator.py b/data_juicer/ops/deduplicator/ray_document_deduplicator.py
index ce5cced4e..8855a0514 100644
--- a/data_juicer/ops/deduplicator/ray_document_deduplicator.py
+++ b/data_juicer/ops/deduplicator/ray_document_deduplicator.py
@@ -2,7 +2,6 @@
import string
import regex as re
-from pydantic import PositiveInt
from ..base_op import OPERATORS
from .ray_basic_deduplicator import RayBasicDeduplicator
@@ -17,24 +16,24 @@ class RayDocumentDeduplicator(RayBasicDeduplicator):
"""
def __init__(self,
- redis_host: str = 'localhost',
- redis_port: PositiveInt = 6380,
+ backend: str = 'ray_actor',
+ redis_address: str = 'redis://localhost:6379',
lowercase: bool = False,
ignore_non_character: bool = False,
*args,
**kwargs):
"""
Initialization method.
- :param redis_host: the hostname of redis server
- :param redis_port: the port of redis server
+ :param backend: the backend for dedup, either 'ray_actor' or 'redis'
+ :param redis_address: the address of redis server
:param lowercase: Whether to convert sample text to lower case
:param ignore_non_character: Whether to ignore non-alphabet
characters, including whitespaces, digits, and punctuations
:param args: extra args
:param kwargs: extra args.
"""
- super().__init__(redis_host=redis_host,
- redis_port=redis_port,
+ super().__init__(backend=backend,
+ redis_address=redis_address,
*args,
**kwargs)
self.lowercase = lowercase
diff --git a/data_juicer/ops/deduplicator/ray_image_deduplicator.py b/data_juicer/ops/deduplicator/ray_image_deduplicator.py
index 7ca0d10f2..de4b9ceea 100644
--- a/data_juicer/ops/deduplicator/ray_image_deduplicator.py
+++ b/data_juicer/ops/deduplicator/ray_image_deduplicator.py
@@ -1,5 +1,4 @@
import numpy as np
-from pydantic import PositiveInt
from data_juicer.utils.lazy_loader import LazyLoader
from data_juicer.utils.mm_utils import load_data_with_context, load_image
@@ -36,20 +35,20 @@ class RayImageDeduplicator(RayBasicDeduplicator):
"""
def __init__(self,
- redis_host: str = 'localhost',
- redis_port: PositiveInt = 6380,
+ backend: str = 'ray_actor',
+ redis_address: str = 'redis://localhost:6379',
method: str = 'phash',
*args,
**kwargs):
"""
Initialization.
- :param redis_host: the hostname of redis server
- :param redis_port: the port of redis server
+ :param backend: the backend for dedup, either 'ray_actor' or 'redis'
+ :param redis_address: the address of redis server
:param args: extra args
:param kwargs: extra args
"""
- super().__init__(redis_host=redis_host,
- redis_port=redis_port,
+ super().__init__(backend=backend,
+ redis_address=redis_address,
*args,
**kwargs)
if method not in HASH_METHOD:
diff --git a/data_juicer/ops/deduplicator/ray_video_deduplicator.py b/data_juicer/ops/deduplicator/ray_video_deduplicator.py
index 902ca1979..4646c8969 100644
--- a/data_juicer/ops/deduplicator/ray_video_deduplicator.py
+++ b/data_juicer/ops/deduplicator/ray_video_deduplicator.py
@@ -1,7 +1,5 @@
import hashlib
-from pydantic import PositiveInt
-
from data_juicer.utils.mm_utils import (close_video, load_data_with_context,
load_video)
@@ -21,19 +19,19 @@ class RayVideoDeduplicator(RayBasicDeduplicator):
"""
def __init__(self,
- redis_host: str = 'localhost',
- redis_port: PositiveInt = 6380,
+ backend: str = 'ray_actor',
+ redis_address: str = 'redis://localhost:6379',
*args,
**kwargs):
"""
Initialization.
- :param redis_host: the hostname of redis server
- :param redis_port: the port of redis server
+ :param backend: the backend for dedup, either 'ray_actor' or 'redis'
+ :param redis_address: the address of redis server
:param args: extra args
:param kwargs: extra args
"""
- super().__init__(redis_host=redis_host,
- redis_port=redis_port,
+ super().__init__(backend=backend,
+ redis_address=redis_address,
*args,
**kwargs)
diff --git a/data_juicer/ops/filter/language_id_score_filter.py b/data_juicer/ops/filter/language_id_score_filter.py
index 3d97a4424..5df71524e 100644
--- a/data_juicer/ops/filter/language_id_score_filter.py
+++ b/data_juicer/ops/filter/language_id_score_filter.py
@@ -1,7 +1,5 @@
from typing import List, Union
-from loguru import logger
-
from data_juicer.utils.constant import Fields, StatsKeys
from data_juicer.utils.lazy_loader import LazyLoader
from data_juicer.utils.model_utils import get_model, prepare_model
@@ -55,7 +53,6 @@ def compute_stats_single(self, sample):
ft_model = get_model(self.model_key)
if ft_model is None:
err_msg = 'Model not loaded. Please retry later.'
- logger.error(err_msg)
raise ValueError(err_msg)
pred = ft_model.predict(text)
lang_id = pred[0][0].replace('__label__', '')
diff --git a/data_juicer/ops/mapper/extract_entity_attribute_mapper.py b/data_juicer/ops/mapper/extract_entity_attribute_mapper.py
index 8bdeeaa0d..250b60fc0 100644
--- a/data_juicer/ops/mapper/extract_entity_attribute_mapper.py
+++ b/data_juicer/ops/mapper/extract_entity_attribute_mapper.py
@@ -1,6 +1,7 @@
import re
from typing import Dict, List, Optional
+import numpy as np
from loguru import logger
from pydantic import PositiveInt
@@ -157,12 +158,15 @@ def _process_single_text(self, text='', rank=None):
'content': input_prompt
}]
- desc, demos = '', []
+ desc, demos = '', np.array([], dtype=str)
for _ in range(self.try_num):
try:
output = client(messages, **self.sampling_params)
- desc, demos = self.parse_output(output, attribute)
- if desc and len(demos) > 0:
+ cur_desc, cur_demos = self.parse_output(
+ output, attribute)
+ if cur_desc and len(cur_demos) > 0:
+ desc = cur_desc
+ demos = cur_demos
break
except Exception as e:
logger.warning(f'Exception: {e}')
diff --git a/data_juicer/ops/mapper/extract_entity_relation_mapper.py b/data_juicer/ops/mapper/extract_entity_relation_mapper.py
index edf897381..27388c8da 100644
--- a/data_juicer/ops/mapper/extract_entity_relation_mapper.py
+++ b/data_juicer/ops/mapper/extract_entity_relation_mapper.py
@@ -6,6 +6,7 @@
import re
from typing import Dict, List, Optional
+import numpy as np
from loguru import logger
from pydantic import NonNegativeInt, PositiveInt
@@ -328,12 +329,26 @@ def process_single(self, sample, rank=None):
input_text=sample[self.text_key])
messages = [{'role': 'user', 'content': input_prompt}]
- entities, relations = [], []
+ entities = [{
+ MetaKeys.entity_name: '',
+ MetaKeys.entity_type: '',
+ MetaKeys.entity_description: ''
+ }]
+ relations = [{
+ MetaKeys.source_entity: '',
+ MetaKeys.target_entity: '',
+ MetaKeys.relation_description: '',
+ MetaKeys.relation_keywords: np.array([], dtype=str),
+ MetaKeys.relation_strength: .0
+ }]
for _ in range(self.try_num):
try:
result = self.light_rag_extraction(messages, rank=rank)
- entities, relations = self.parse_output(result)
- if len(entities) > 0:
+ cur_entities, cur_relations = self.parse_output(result)
+ if len(cur_entities) > 0:
+ entities = cur_entities
+ if len(cur_relations) > 0:
+ relations = cur_relations
break
except Exception as e:
logger.warning(f'Exception: {e}')
diff --git a/data_juicer/ops/mapper/extract_keyword_mapper.py b/data_juicer/ops/mapper/extract_keyword_mapper.py
index 2b727f0ac..b0961331e 100644
--- a/data_juicer/ops/mapper/extract_keyword_mapper.py
+++ b/data_juicer/ops/mapper/extract_keyword_mapper.py
@@ -3,6 +3,7 @@
import re
from typing import Dict, Optional
+import numpy as np
from loguru import logger
from pydantic import PositiveInt
@@ -160,7 +161,7 @@ def parse_output(self, raw_output):
matches = output_pattern.findall(raw_output)
for record in matches:
items = split_text_by_punctuation(record)
- keywords.append(items)
+ keywords.extend(items)
return keywords
@@ -177,12 +178,13 @@ def process_single(self, sample, rank=None):
input_text=sample[self.text_key])
messages = [{'role': 'user', 'content': input_prompt}]
- keywords = []
+ keywords = np.array([], dtype=str)
for _ in range(self.try_num):
try:
- result = client(messages, **self.sampling_params)
- keywords = self.parse_output(result)
- if len(keywords) > 0:
+ response = client(messages, **self.sampling_params)
+ results = self.parse_output(response)
+ if len(results) > 0:
+ keywords = results
break
except Exception as e:
logger.warning(f'Exception: {e}')
diff --git a/data_juicer/ops/mapper/extract_nickname_mapper.py b/data_juicer/ops/mapper/extract_nickname_mapper.py
index 140f61011..405a7ad5a 100644
--- a/data_juicer/ops/mapper/extract_nickname_mapper.py
+++ b/data_juicer/ops/mapper/extract_nickname_mapper.py
@@ -1,6 +1,7 @@
import re
from typing import Dict, Optional
+import numpy as np
from loguru import logger
from pydantic import PositiveInt
@@ -147,12 +148,24 @@ def process_single(self, sample, rank=None):
'role': 'user',
'content': input_prompt
}]
- nickname_relations = []
+ nickname_relations = [{
+ MetaKeys.source_entity:
+ '',
+ MetaKeys.target_entity:
+ '',
+ MetaKeys.relation_description:
+ '',
+ MetaKeys.relation_keywords:
+ np.array([], dtype=str),
+ MetaKeys.relation_strength:
+ None
+ }]
for _ in range(self.try_num):
try:
output = client(messages, **self.sampling_params)
- nickname_relations = self.parse_output(output)
- if len(nickname_relations) > 0:
+ results = self.parse_output(output)
+ if len(results) > 0:
+ nickname_relations = results
break
except Exception as e:
logger.warning(f'Exception: {e}')
diff --git a/data_juicer/ops/mapper/generate_qa_from_examples_mapper.py b/data_juicer/ops/mapper/generate_qa_from_examples_mapper.py
index b962aa51c..a7a05ae19 100644
--- a/data_juicer/ops/mapper/generate_qa_from_examples_mapper.py
+++ b/data_juicer/ops/mapper/generate_qa_from_examples_mapper.py
@@ -7,7 +7,8 @@
from pydantic import PositiveInt
from data_juicer.utils.lazy_loader import LazyLoader
-from data_juicer.utils.model_utils import get_model, prepare_model
+from data_juicer.utils.model_utils import (get_model, prepare_model,
+ update_sampling_params)
from ..base_op import OPERATORS, Mapper
@@ -139,6 +140,10 @@ def __init__(self,
**model_params)
self.sampling_params = sampling_params
+ self.sampling_params = update_sampling_params(sampling_params,
+ hf_model,
+ self.enable_vllm)
+
self.seed_qa_samples = self._load_seed_qa_samples()
if len(self.seed_qa_samples) == 0:
raise ValueError('No QA data was parsed from the seed file!')
diff --git a/data_juicer/ops/mapper/generate_qa_from_text_mapper.py b/data_juicer/ops/mapper/generate_qa_from_text_mapper.py
index 0f3a1cfef..832f1c782 100644
--- a/data_juicer/ops/mapper/generate_qa_from_text_mapper.py
+++ b/data_juicer/ops/mapper/generate_qa_from_text_mapper.py
@@ -2,10 +2,12 @@
from typing import Dict, Optional
from loguru import logger
+from pydantic import PositiveInt
from data_juicer.ops.base_op import OPERATORS, Mapper
from data_juicer.utils.lazy_loader import LazyLoader
-from data_juicer.utils.model_utils import get_model, prepare_model
+from data_juicer.utils.model_utils import (get_model, prepare_model,
+ update_sampling_params)
torch = LazyLoader('torch', 'torch')
vllm = LazyLoader('vllm', 'vllm')
@@ -35,6 +37,7 @@ class GenerateQAFromTextMapper(Mapper):
def __init__(self,
hf_model: str = 'alibaba-pai/pai-qwen1_5-7b-doc2qa',
+ max_num: Optional[PositiveInt] = None,
*,
output_pattern: Optional[str] = None,
enable_vllm: bool = False,
@@ -45,6 +48,8 @@ def __init__(self,
Initialization method.
:param hf_model: Hugginface model ID.
+ :param max_num: The max num of returned QA sample for each text.
+ Not limit if it is None.
:param output_pattern: Regular expression pattern to extract
questions and answers from model response.
:param enable_vllm: Whether to use vllm for inference acceleration.
@@ -69,6 +74,8 @@ def __init__(self,
super().__init__(**kwargs)
+ self.max_num = max_num
+
if output_pattern is None:
self.output_pattern = r'Human:(.*?)Assistant:(.*?)(?=Human|$)' # noqa: E501
else:
@@ -100,6 +107,10 @@ def __init__(self,
**model_params)
self.sampling_params = sampling_params
+ self.sampling_params = update_sampling_params(sampling_params,
+ hf_model,
+ self.enable_vllm)
+
def parse_output(self, raw_output):
logger.debug(raw_output)
qa_list = []
@@ -131,6 +142,10 @@ def process_batched(self, samples, rank=None):
output = response[0]['generated_text']
qa_list = self.parse_output(output)
+
+ if self.max_num is not None:
+ qa_list = qa_list[:self.max_num]
+
if len(qa_list) > 0:
for q, a in qa_list:
for input_k in input_keys:
diff --git a/data_juicer/ops/mapper/optimize_qa_mapper.py b/data_juicer/ops/mapper/optimize_qa_mapper.py
index 974730ec5..8402f1683 100644
--- a/data_juicer/ops/mapper/optimize_qa_mapper.py
+++ b/data_juicer/ops/mapper/optimize_qa_mapper.py
@@ -5,7 +5,8 @@
from data_juicer.ops.base_op import OPERATORS, Mapper
from data_juicer.utils.lazy_loader import LazyLoader
-from data_juicer.utils.model_utils import get_model, prepare_model
+from data_juicer.utils.model_utils import (get_model, prepare_model,
+ update_sampling_params)
torch = LazyLoader('torch', 'torch')
vllm = LazyLoader('vllm', 'vllm')
@@ -98,6 +99,10 @@ def __init__(self,
**model_params)
self.sampling_params = sampling_params
+ self.sampling_params = update_sampling_params(sampling_params,
+ hf_model,
+ self.enable_vllm)
+
def build_input(self, sample):
qa_pair = self.qa_pair_template.format(sample[self.query_key],
sample[self.response_key])
diff --git a/data_juicer/ops/op_fusion.py b/data_juicer/ops/op_fusion.py
index 489f90ab0..71e550cb4 100644
--- a/data_juicer/ops/op_fusion.py
+++ b/data_juicer/ops/op_fusion.py
@@ -156,8 +156,8 @@ def __init__(self, name: str, fused_filters: List):
:param fused_filters: a list of filters to be fused.
"""
- super().__init__()
self._name = name
+ super().__init__()
self.fused_filters = fused_filters
# set accelerator to 'cuda' if there exists any ops whose accelerator
# is 'cuda'
diff --git a/data_juicer/utils/ckpt_utils.py b/data_juicer/utils/ckpt_utils.py
index d22762adb..78192b85f 100644
--- a/data_juicer/utils/ckpt_utils.py
+++ b/data_juicer/utils/ckpt_utils.py
@@ -121,7 +121,9 @@ def save_ckpt(self, ds):
:param ds: input dataset to save
"""
- ds.save_to_disk(self.ckpt_ds_dir, num_proc=self.num_proc)
+ left_sample_num = len(ds)
+ ds.save_to_disk(self.ckpt_ds_dir,
+ num_proc=min(self.num_proc, left_sample_num))
with open(self.ckpt_op_record, 'w') as fout:
json.dump(self.op_record, fout)
diff --git a/data_juicer/utils/constant.py b/data_juicer/utils/constant.py
index 11de97427..242ad3afe 100644
--- a/data_juicer/utils/constant.py
+++ b/data_juicer/utils/constant.py
@@ -268,7 +268,7 @@ class HashKeys(object):
videohash = DEFAULT_PREFIX + 'videohash'
# duplicate flag
- is_duplicate = DEFAULT_PREFIX + 'is_duplicate'
+ is_unique = DEFAULT_PREFIX + 'is_unique'
class InterVars(object):
diff --git a/data_juicer/utils/logger_utils.py b/data_juicer/utils/logger_utils.py
index a91f610fe..11cbf85b8 100644
--- a/data_juicer/utils/logger_utils.py
+++ b/data_juicer/utils/logger_utils.py
@@ -22,6 +22,9 @@
from loguru import logger
from loguru._file_sink import FileSink
+from tabulate import tabulate
+
+from data_juicer.utils.file_utils import add_suffix_to_filename
LOGGER_SETUP = False
@@ -142,12 +145,88 @@ def setup_logger(save_dir,
)
logger.add(save_file)
+ # for interest of levels: debug, error, warning
+ logger.add(
+ add_suffix_to_filename(save_file, '_DEBUG'),
+ level='DEBUG',
+ filter=lambda x: 'DEBUG' == x['level'].name,
+ format=loguru_format,
+ enqueue=True,
+ serialize=True,
+ )
+ logger.add(
+ add_suffix_to_filename(save_file, '_ERROR'),
+ level='ERROR',
+ filter=lambda x: 'ERROR' == x['level'].name,
+ format=loguru_format,
+ enqueue=True,
+ serialize=True,
+ )
+ logger.add(
+ add_suffix_to_filename(save_file, '_WARNING'),
+ level='WARNING',
+ filter=lambda x: 'WARNING' == x['level'].name,
+ format=loguru_format,
+ enqueue=True,
+ serialize=True,
+ )
+
# redirect stdout/stderr to loguru
if redirect:
redirect_sys_output(level)
LOGGER_SETUP = True
+def make_log_summarization(max_show_item=10):
+ error_pattern = r'^An error occurred in (.*?) when ' \
+ r'processing samples? \"(.*?)\" -- (.*?): (.*?)$'
+ log_file = get_log_file_path()
+ error_log_file = add_suffix_to_filename(log_file, '_ERROR')
+ warning_log_file = add_suffix_to_filename(log_file, '_WARNING')
+
+ import jsonlines as jl
+ import regex as re
+
+ # make error summarization
+ error_dict = {}
+ with jl.open(error_log_file) as reader:
+ for error_log in reader:
+ error_msg = error_log['record']['message']
+ find_res = re.findall(error_pattern, error_msg)
+ if len(find_res) > 0:
+ op_name, sample, error_type, error_msg = find_res[0]
+ error = (op_name, error_type, error_msg)
+ error_dict.setdefault(error, 0)
+ error_dict[error] += 1
+ total_error_count = sum(error_dict.values())
+ # make warning summarization
+ warning_count = 0
+ with jl.open(warning_log_file) as reader:
+ for _ in reader:
+ warning_count += 1
+ # make summary log
+ summary = f'Processing finished with:\n' \
+ f'