diff --git a/.gitignore b/.gitignore
index 97032ad..819a078 100644
--- a/.gitignore
+++ b/.gitignore
@@ -57,11 +57,16 @@ _ignore/
/_site/
/docs/
+# directories that include the word "scratch"
+*scratch*/
+
# Project Specific Files
-## ignore files that start with "scratch" in any directory
-**/scratch*.R
+## files with "scratch" in the filename any directory
+**/*scratch*.R
# 03_data_results/*.csv
# 03_data_results/*.gpkg
03_data_results/dataset_hash.csv
code_from_python_package_comparison.R
-quarto_document_publishing.txt
\ No newline at end of file
+quarto_document_publishing.txt
+water_supplier_boundaries_2024-03-11/
+water_supplier_boundaries_2024-03-11.zip
\ No newline at end of file
diff --git a/01_document/example_census_race_ethnicity_calculation.qmd b/01_document/example_census_race_ethnicity_calculation.qmd
index 75ce9df..fb82263 100644
--- a/01_document/example_census_race_ethnicity_calculation.qmd
+++ b/01_document/example_census_race_ethnicity_calculation.qmd
@@ -20,16 +20,20 @@ text-align: left;
```
## Background {#sec-background}
+::: callout-note
+For comments, suggestions, corrections, or questions on anything below, contact [david.altare\@waterboards.ca.gov](mailto:david.altare@waterboards.ca.gov), or [open an issue](https://github.com/daltare/example-census-race-ethnicity-calculation/issues) on github.
+:::
+
+::: callout-warning
+This document is a work in progress, and may change significantly.
+:::
+
This document provides an example of how to use tools available from the [R programming language](https://www.R-project.org/) [@R] to estimate characteristics of any given *target* spatial area(s) (e.g., neighborhoods, project boundaries, water supplier service areas, etc.) based on data from a *source* dataset containing the characteristic data of interest (e.g., census data, CalEnvrioScreen scores, etc.), especially when the boundaries of the *source* and *target* areas overlap but don't necessarily align with each other. It also provides some brief background on the various types of data available from the U.S Census Bureau, and links to a few places to find more in-depth information.
This particular example estimates demographic characteristics of community water systems in the Sacramento County area (the *target* dataset). It uses the [`tidycensus`](https://walker-data.com/tidycensus/index.html) R package [@tidycensus] to access selected demographic data from the U.S. Census Bureau (the *source* dataset) for census units whose spatial extent covers those water systems' service areas, then uses the [`areal`](https://chris-prener.github.io/areal/) R package [@areal] to estimate some demographic characteristics of each water system based on that census data. It also relies on a number of other R packages, such as the [`tidyverse`](https://www.tidyverse.org/) collection of packages [@tidyverse] for general data management and analysis, and the [`sf`](https://r-spatial.github.io/sf/) package [@sf] for working with spatial data.
This example is just intended to be a simplified demonstration of a possible workflow. For a real analysis, additional steps and considerations -- that may not be covered here -- may be needed to deal with data inconsistencies (e.g., missing or incomplete data), required level of precision and acceptable assumptions (e.g. more fine-grained datasets or more sophisticated techniques could be used to estimate/model population distributions), or other project-specific issues that might arise.
-::: callout-note
-For comments, suggestions, corrections, or questions on anything below, contact [david.altare\@waterboards.ca.gov](mailto:david.altare@waterboards.ca.gov), or [open an issue](https://github.com/daltare/example-census-race-ethnicity-calculation/issues) on github.
-:::
-
## Setup {#sec-setup}
The code block below loads required packages for this analysis, and sets some user-defined options and defaults. If they aren't already installed on your computer, you can install them with the R command `install.packages('package-name')` (and replace `package-name` with the name of the package you want to install).
@@ -67,15 +71,75 @@ options(tigris_use_cache = TRUE) # use data caching for tigris
crs_projected <- 3310 # set a common projected coordinate reference system to be used throughout this analysis - see: https://epsg.io/3310
```
-## Water System Boundaries (Target Data) {#sec-system-boundaries}
-In this section, we'll get the service area boundaries for Community Water Systems within the Sacramento County area. This will serve as the *target* dataset -- i.e., the set of areas which we'll be estimating the characteristics of. We'll also get a dataset of county boundaries which overlap the water service areas in this study, which will help with accessing the census data and with making maps/visualizations.
+## Census Data Overview {#sec-census-overview}
+
+This section provides some brief background on the various types of data available from the U.S. Census Bureau (a later section - @sec-census-access - demonstrates how to retrieve data from the U.S. Census Bureau using the [`tidycensus`](https://walker-data.com/tidycensus/index.html) R package). Most of the information covered here comes from the book [Analyzing US Census Data: Methods, Maps, and Models in R](https://walker-data.com/census-r/index.html), which is a great source of information if you'd like more detail about any of the topics below [@walker2023].
+
+::: callout-note
+If you're already familiar with Census data and want to skip this overview, go directly to the next section: @sec-system-boundaries
+:::
+
+Different census products/surveys contain data on different variables, at different geographic scales, over varying periods of time, and with varying levels of certainty. Therefore, there are a number of judgement calls to make when determining which type of census data to use for an analysis -- e.g., which data product to use (Decennial Census or American Community Survey), which geographic scale to use (e.g., Block, Block Group, Tract, etc.), what time frame to use, which variables to assess, etc.
+
+More detailed information about U.S. Census Bureau's data products and other topics mentioned below is available [here](https://walker-data.com/census-r/the-united-states-census-and-the-r-programming-language.html#the-united-states-census-and-the-r-programming-language).
+
+### Census Unit Geography / Hierarchy {#sec-census-hierarchy}
+
+Data from the U.S. Census Bureau is aggregated to census units which are available at different geographic scales. Some of these units are nested and can be neatly aggregated (e.g., each census tract is composed of a collection of block groups, and each block group is composed of a collection of blocks), while other census units are outside this hierarchy (e.g., Zip Code Tabulation Areas don't coincide with any other census unit). @fig-census-hierarchies shows the relationship of all of the various census units.
+
+Commonly used census statistical units like tracts and block groups have target population size ranges, and can be adjusted every 10 years (with the decennial census) based on population changes. For example, all ACS 5-year datasets prior to 2020 use the 2010 boundaries for tracts, block groups, and blocks, and all ACS 5-year datasets from [2020 onward](https://www.census.gov/programs-surveys/acs/technical-documentation/table-and-geography-changes/2020/geography-changes.html) (presumably through 2029) use the 2020 boundaries for those units. [Census tracts](https://www.census.gov/programs-surveys/geography/about/glossary.html#par_textimage_13) are generally around 4,000 people, with a range from about 1,200 to 8,000, and [block groups](https://www.census.gov/programs-surveys/geography/about/glossary.html#par_textimage_4) generally contain 600 to 3,000 people. [Blocks](https://www.census.gov/programs-surveys/geography/about/glossary.html#par_textimage_5) are the smallest census units, and are "areas bounded by visible features, such as streets, roads, streams, and railroad tracks, and by nonvisible boundaries, such as selected property lines and city, township, school district, and county limits and short line-of-sight extensions of streets and roads". For example, a census block may be "a city block bounded on all sides by streets", while "blocks in suburban and rural areas may be larger, more irregular in shape, and bounded by a variety of features, such as roads, streams, and transmission lines".
+
+::: callout-caution
+Census boundaries can change over time. Commonly used statistical units like tracts, block groups, and blocks tend to be revised every 10 years (with the decennial census), so it's important to use a census boundary dataset that matches the version of the census demographic data you're retrieving; otherwise, the demographic data may not match geographic areas in your boundary dataset. In some cases, a census unit that exists in a given year of the census data may not exist at all in a different year's dataset, because census units can be split or merged when boundaries are revised.
+
+For more information, see [here](https://www.census.gov/content/dam/Census/library/publications/2020/acs/acs_geography_handbook_2020_ch02.pdf) or [here](https://www.census.gov/programs-surveys/acs/geography-acs/geography-boundaries-by-year.html) or [here](https://www.census.gov/programs-surveys/geography/about/glossary.html#par_textimage_6) or [here](https://www.census.gov/data/academy/data-gems/2021/compare-2020-census-and-2010-census-redistricting-data.html).
+:::
+
+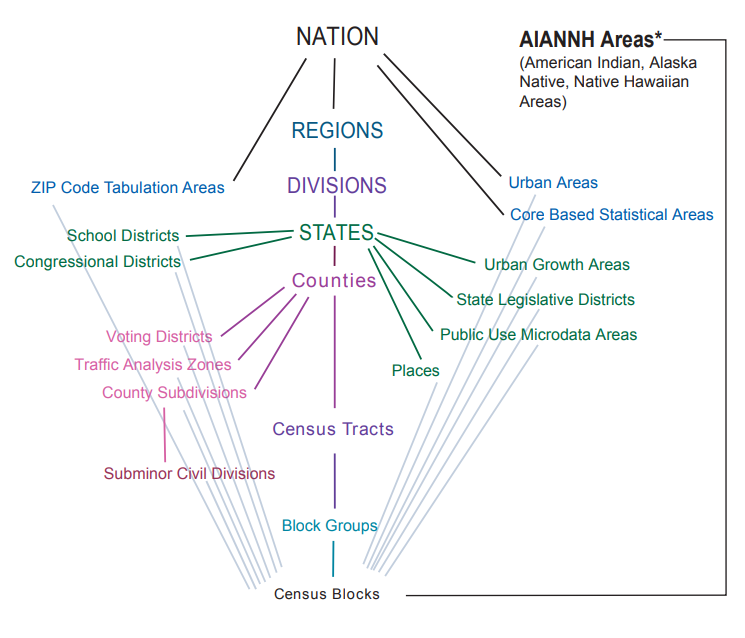{#fig-census-hierarchies}
+
+For a list of the different geographic units available for each of the different census products/surveys (see @sec-census-datasets) that can be accessed via the `tidycensus` package, go [here](https://walker-data.com/tidycensus/articles/basic-usage.html#geography-in-tidycensus).
+
+### Census Datasets / Surveys {#sec-census-datasets}
+
+The Decennial Census is conducted every 10 years, and is intended to provide a complete count of the US population and assist with political redistricting. As a result, it collects a relatively limited set of basic demographic data, but (should) provide a high degree of precision (i.e., in general it should provide exact counts). It is available for geographic units down to the census block (the smallest census unit available -- see @sec-census-hierarchy). For information about existing and planned future releases of 2020 census data products, go [here](https://www.census.gov/programs-surveys/decennial-census/decade/2020/planning-management/release/about-2020-data-products.html).
+
+The American Community Survey (ACS) provides a much larger array of demographic information than the Decennial Census, and is updated more frequently. The ACS is based on a sample of the population (rather than a count of the entire population, as in the Decennial Census), so it represents estimated values rather than precise counts; therefore, each data point is available as an estimate (typically labeled with an "E" in census variable codes, which are discussed in @sec-census-variables ) along with an associated margin of error (typically labeled with "M" or "MOE" in census variable codes) around its estimated value.
+
+The ACS is available in two formats. The 5-year ACS is a rolling average of 5 years of data (e.g., the 2021 5-year ACS dataset is an average of the ACS data from 2017 through 2021), and is generally available for geographic units down to the census block group (though some 5-year ACS data may only be available at less granular levels). The 1-year ACS provides data for a single year, and is only available for geographies with population greater than 65,000 (e.g., large cities and counties). Therefore, only the 5-year ACS will be useful for any analysis at a relatively fine scale (e.g., anything that requires data at or more detailed than the census tract level, or any analysis that considers smaller counties/cities -- by definition, census tracts always contain significantly fewer than 65,000 people).
+
+In addition to the Decennial Census and ACS data, a number of other census data products/surveys are also available. For example, see the `censusapi` R package ([here](https://github.com/hrecht/censusapi) or [here](https://www.hrecht.com/censusapi/index.html)) for access to over 300 census API endpoints. For historical census data, see the discussion [here](https://walker-data.com/census-r/other-census-and-government-data-resources.html?q=API%20endpoint#other-census-and-government-data-resources) on using NHGIS, IPUMS, and the `ipumsr` package.
+
+### Census Variables / Codes {#sec-census-variables}
+
+Each census product collects data for many different demographic variables, and each variable is generally associated with an identifier code. In order to access census data programmatically, you often need to know the code associated with each variable of interest. When determining which variables to use, you need to consider what census product contains those variables (see @sec-census-datasets) and how they differ in terms of time frame, precision, spatial granularity (see @sec-census-hierarchy), etc.
+
+The `tidycensus` package offers a convenient generic way to search for variables across different census products using the `load_variables()` function, as described [here](https://walker-data.com/tidycensus/articles/basic-usage.html#searching-for-variables).
+
+The following websites may also be helpful for exploring the various census data products and finding the variable names and codes they contain:
+
+- Census Reporter (for ACS data): (especially )
+
+- Census Bureau's list of variable codes, e.g.:
+
+ - 2020 Census codes:
+
+ - 2022 ACS 5 year codes:
+
+- Census Bureau's data interface (for Decennial Census and ACS, and other census datasets):
+
+- National Historical Geographic Information System (NHGIS) (for ACS data and historical decennial Census data):
+
+
+## Target Data Boundaries (Water Systems) {#sec-system-boundaries}
+
+In this section, we'll get the service area boundaries for Community Water Systems within the Sacramento County area. This will serve as the *target* dataset – i.e., the set of areas which we'll be estimating the characteristics of – and will also be used to specifying what census data we want to retrieve. We'll also get a dataset of county boundaries which overlap the water service areas in this study, which can also help with specifying what census data to access and/or with making maps and visualizations.
### Read Water System Data
In this case, we'll get the water system dataset from a shapefile that's saved locally, then transform that dataset into a common coordinate reference system for mapping and analysis (which is defined above in the variable `crs_projected`).
-This water system dataset is a subset of the [California Drinking Water System Area Boundaries dataset](https://gispublic.waterboards.ca.gov/portal/home/item.html?id=fbba842bf134497c9d611ad506ec48cc). I created the subset used here by filtering the full dataset for systems within Sacramento County (by selecting records where the `COUNTY` field is "SACRAMENTO") and filtering for Community Water Systems (by selecting records where the `STATE_CLAS` field is "COMMUNITY"). I also dropped some un-needed fields from the dataset and reordered some columns.
+This water system dataset comes from the [California Drinking Water System Area Boundaries dataset](https://gispublic.waterboards.ca.gov/portal/home/item.html?id=fbba842bf134497c9d611ad506ec48cc). For this example, the dataset has been pre-filtered for systems within Sacramento County (by selecting records where the `COUNTY` field is "SACRAMENTO") and for Community Water Systems (by selecting records where the `STATE_CLAS` field is "COMMUNITY"). Some un-needed fields have also been dropped, remaining fields have been re-orderd.
```{r}
#| message: false
@@ -88,41 +152,44 @@ water_systems_sac <- st_read(here('02_data_input',
st_transform(crs_projected) # transform to common coordinate system
```
-As an alternative, the code chunk below shows how to download this data directly from the online dataset and apply the filters needed to reproduce the dataset in the `System_Area_Boundary_Layer_Sac.shp` file, using the [`arcgislayers`](https://r.esri.com/arcgislayers/index.html) package [@arcgislayers]. This code is commented out (with the `#` symbol), since it gives the same dataset as is contained in the shapefile that's read in above, but is included here as a reference for a more direct alternative way to obtain the current version of the *target* dataset. Note that, since this method is accessing the current version of the dataset, it may return somewhat different data than is in the shapefile read above (since the shapefile contains a locally saved version); also note that the field names are different in the online dataset, because they're automatically truncated when saving to shapefile format, so the code below renames them to be consistent with dataset read above.
-
-```{r}
-# # load arcgislayers package (see: https://r.esri.com/arcgislayers/index.html)
-# # install.packages('pak') # only needed if the pak package is not already installed
-# # pak::pkg_install("R-ArcGIS/arcgislayers", dependencies = TRUE)
-# library(arcgislayers)
-#
-# # define link to data source
-# url_feature <- 'https://gispublic.waterboards.ca.gov/portalserver/rest/services/Drinking_Water/California_Drinking_Water_System_Area_Boundaries/FeatureServer/0'
-#
-# # connect to data source
-# water_systems_feature_layer <- arc_open(url_feature)
-#
-# # download and filter data from source
-# water_systems_sac <- arc_select(
-# water_systems_feature_layer,
-# # apply filters
-# where = "COUNTY = 'SACRAMENTO' AND STATE_CLASSIFICATION = 'COMMUNITY'",
-# # select fields
-# fields = c('WATER_SYSTEM_NAME', 'WATER_SYSTEM_NUMBER', 'GLOBALID',
-# 'BOUNDARY_TYPE', 'OWNER_TYPE_CODE', 'COUNTY',
-# 'REGULATING_AGENCY', 'FEDERAL_CLASSIFICATION', 'STATE_CLASSIFICATION',
-# 'SERVICE_CONNECTIONS', 'POPULATION')) %>%
-# # transform to commont coordinate system
-# st_transform(crs_projected) %>%
-# # rename fields to match names from the shapefile
-# rename(WATER_SY_1 = WATER_SYSTEM_NAME,
-# WATER_SYST = WATER_SYSTEM_NUMBER,
-# BOUNDARY_T = BOUNDARY_TYPE,
-# OWNER_TYPE = OWNER_TYPE_CODE,
-# REGULATING = REGULATING_AGENCY,
-# FEDERAL_CL = FEDERAL_CLASSIFICATION,
-# STATE_CLAS = STATE_CLASSIFICATION,
-# SERVICE_CO = SERVICE_CONNECTIONS)
+Reading in data from a shapefile is shown above because it's likely one of the more common ways that users will access their *target* boundary data. However, depending on the dataset, there may be other ways to access the data. For example, the code chunk below demonstrates an alternative -- using the [`arcgislayers`](https://r.esri.com/arcgislayers/index.html) package [@arcgislayers] -- that connects directly to the source dataset (to retrieve the most recent version) and applies the filters needed to reproduce the dataset in the `System_Area_Boundary_Layer_Sac.shp` file). Note that this code is not actually used -- it is just presented here for reference.
+
+```{r}
+#| eval: false
+
+# load arcgislayers package (see: https://r.esri.com/arcgislayers/index.html)
+# install.packages('pak') # only needed if the pak package is not already installed
+# pak::pkg_install("R-ArcGIS/arcgislayers", dependencies = TRUE)
+
+library(arcgislayers)
+
+# define link to data source
+url_feature <- 'https://gispublic.waterboards.ca.gov/portalserver/rest/services/Drinking_Water/California_Drinking_Water_System_Area_Boundaries/FeatureServer/0'
+
+# connect to data source
+water_systems_feature_layer <- arc_open(url_feature)
+
+# download and filter data from source
+water_systems_sac <- arc_select(
+ water_systems_feature_layer,
+ # apply filters
+ where = "COUNTY = 'SACRAMENTO' AND STATE_CLASSIFICATION = 'COMMUNITY'",
+ # select fields
+ fields = c('WATER_SYSTEM_NAME', 'WATER_SYSTEM_NUMBER', 'GLOBALID',
+ 'BOUNDARY_TYPE', 'OWNER_TYPE_CODE', 'COUNTY',
+ 'REGULATING_AGENCY', 'FEDERAL_CLASSIFICATION', 'STATE_CLASSIFICATION',
+ 'SERVICE_CONNECTIONS', 'POPULATION')) %>%
+ # transform to common coordinate system
+ st_transform(crs_projected) %>%
+ # rename fields to match names from the shapefile (which automatically truncates field names)
+ rename(WATER_SY_1 = WATER_SYSTEM_NAME,
+ WATER_SYST = WATER_SYSTEM_NUMBER,
+ BOUNDARY_T = BOUNDARY_TYPE,
+ OWNER_TYPE = OWNER_TYPE_CODE,
+ REGULATING = REGULATING_AGENCY,
+ FEDERAL_CL = FEDERAL_CLASSIFICATION,
+ STATE_CLAS = STATE_CLASSIFICATION,
+ SERVICE_CO = SERVICE_CONNECTIONS)
```
We can use the `glimpse` function (below) to take get a sense of what type of information is available in the water system dataset and how it's structured.
@@ -135,7 +202,7 @@ glimpse(water_systems_sac)
### Get County Boundaries {#sec-county-boundaries}
-To determine what data to pull from the U.S. Census Bureau, and to create some maps later, we need to get a dataset of county boundaries. These are available from the [TIGER dataset](https://www.census.gov/geographies/mapping-files/time-series/geo/tiger-line-file.html) and can be accessed using the [`tigris`](https://github.com/walkerke/tigris) R package [@tigris].
+When accessing census data, it may be useful to know which counties overlap the target dataset, as described below in @sec-census-access (note that, even though the dataset is filtered for systems in Sacramento county, there are some systems whose boundaries extend into neighboring counties). County boundaries may also be useful for making maps in later stages of the analysis. We can get a dataset of county boundaries in California from the [TIGER dataset](https://www.census.gov/geographies/mapping-files/time-series/geo/tiger-line-file.html), which can be accessed with R using the [`tigris`](https://github.com/walkerke/tigris) R package [@tigris].
```{r}
#| message: false
@@ -147,7 +214,7 @@ counties_ca <- counties(state = 'CA',
st_transform(crs_projected) # transform to common coordinate system
```
-Then, we can get a list of counties that overlap with the boundaries of the Sacramento area community water systems obtained above. This list will be used when getting the census data (below) -- it is needed because there are some systems whose boundaries extend into neighboring counties (or at least have boundaries that intersect the edge of neighboring counties).
+Then, we can get a list of counties that overlap with the boundaries of the Sacramento area community water systems obtained above.
```{r}
counties_list <- st_filter(counties_ca,
@@ -158,8 +225,6 @@ counties_list <- st_filter(counties_ca,
The counties in the `counties_list` variable are: `r counties_list`.
-### Plot Water Systems and County Boundaries {#sec-plot-systems}
-
As a check, @fig-sys-bounds plots the water systems (in blue) and the county boundaries (in grey):
```{r}
@@ -184,67 +249,8 @@ plot_boundaries <- ggplot() +
plot_boundaries
```
-## Census Data (Source Data) {#sec-census-data}
-
-This section provides some brief background on the various types of data available from the U.S. Census Bureau, and demonstrates how to retrieve data from the U.S. Census Bureau using the [`tidycensus`](https://walker-data.com/tidycensus/index.html) R package. Most of the information covered here comes from the book [Analyzing US Census Data: Methods, Maps, and Models in R](https://walker-data.com/census-r/index.html), which is a great source of information if you'd like more detail about any of the topics below [@walker2023].
-
-### Census Data Overview {#sec-census-overview}
-
-::: callout-note
-If you're already familiar with Census data and want to skip this overview, go directly to @sec-census-access
-:::
-
-Different census products/surveys contain data on different variables, at different geographic scales, over varying periods of time, and with varying levels of certainty. Therefore, there are a number of judgement calls to make when determining which type of census data to use for an analysis -- e.g., which data product to use (Decennial Census or American Community Survey), which geographic scale to use (e.g., Block, Block Group, Tract, etc.), what time frame to use, which variables to assess, etc.
-
-More detailed information about U.S. Census Bureau's data products and other topics mentioned below is available [here](https://walker-data.com/census-r/the-united-states-census-and-the-r-programming-language.html#the-united-states-census-and-the-r-programming-language).
-
-#### Census Geography / Hierarchy {#sec-census-hierarchy}
-
-Data from the U.S. Census Bureau is aggregated to census units which are available at different geographic scales. Some of these units are nested and can be neatly aggregated (e.g., each census tract is composed of a collection of block groups, and each block group is composed of a collection of blocks), while other census units are outside this hierarchy (e.g., Zip Code Tabulation Areas don't coincide with any other census unit). @fig-census-hierarchies shows the relationship of all of the various census units.
-
-Commonly used cenus statistical units like tracts and block groups have target population size ranges, and can be adjusted every 10 years (with the decennial census) based on population changes. [Census tracts](https://www.census.gov/programs-surveys/geography/about/glossary.html#par_textimage_13) are generally around 4,000 people, with a range from about 1,200 to 8,000, and [block groups](https://www.census.gov/programs-surveys/geography/about/glossary.html#par_textimage_4) generally contain 600 to 3,000 people. [Blocks](https://www.census.gov/programs-surveys/geography/about/glossary.html#par_textimage_5) are the smallest census units, and are "areas bounded by visible features, such as streets, roads, streams, and railroad tracks, and by nonvisible boundaries, such as selected property lines and city, township, school district, and county limits and short line-of-sight extensions of streets and roads". For example, a census block may be "a city block bounded on all sides by streets", while "blocks in suburban and rural areas may be larger, more irregular in shape, and bounded by a variety of features, such as roads, streams, and transmission lines".
-
-::: callout-caution
-Census boundaries can change over time. Commonly used statistical units like tracts, block groups, and blocks tend to be revised every 10 years (with the decennial census), so it's important to use a census boundary dataset that matches the version of the census demographic data you're retrieving; otherwise, the demographic data may not match geographic areas in your boundary dataset (in some cases, a census unit that exists in a given year of the census data may not exist at all in a different year's dataset, because census units can be split or merged when boundaries are revised).
-
-For more information, see [here](https://www.census.gov/content/dam/Census/library/publications/2020/acs/acs_geography_handbook_2020_ch02.pdf) or [here](https://www.census.gov/programs-surveys/acs/geography-acs/geography-boundaries-by-year.html) or [here](https://www.census.gov/programs-surveys/geography/about/glossary.html#par_textimage_6) or [here](https://www.census.gov/data/academy/data-gems/2021/compare-2020-census-and-2010-census-redistricting-data.html).
-:::
-
-{#fig-census-hierarchies}
-
-For a list of the different geographic units available for each of the different census products/surveys (see @sec-census-datasets) that can be accessed via the `tidycensus` package, go [here](https://walker-data.com/tidycensus/articles/basic-usage.html#geography-in-tidycensus).
-
-#### Census Datasets / Surveys {#sec-census-datasets}
-
-The Decennial Census is conducted every 10 years, and is intended to provide a complete count of the US population and assist with political redistricting. As a result, it collects a relatively limited set of basic demographic data, but (should) provide a high degree of precision (i.e., in general it should provide exact counts). It is available for geographic units down to the census block (the smallest census unit available -- see @sec-census-hierarchy). For information about existing and planned future releases of 2020 census data products, go [here](https://www.census.gov/programs-surveys/decennial-census/decade/2020/planning-management/release/about-2020-data-products.html).
-
-The American Community Survey (ACS) provides a much larger array of demographic information than the Decennial Census, and is updated more frequently. The ACS is based on a sample of the population (rather than a count of the entire population, as in the Decennial Census), so it represents estimated values rather than precise counts; therefore, each data point is available as an estimate (typically labeled with an "E" in census variable codes, which are discussed in @sec-census-variables ) along with an associated margin of error (typically labeled with "M" or "MOE" in census variable codes) around its estimated value.
-
-The ACS is available in two formats. The 5-year ACS is a rolling average of 5 years of data (e.g., the 2021 5-year ACS dataset is an average of the ACS data from 2017 through 2021), and is generally available for geographic units down to the census block group (though some 5-year ACS data may only be available at less granular levels). The 1-year ACS provides data for a single year, and is only available for geographies with population greater than 65,000 (e.g., large cities and counties). Therefore, only the 5-year ACS will be useful for any analysis at a relatively fine scale (e.g., anything that requires data at or more detailed than the census tract level, or any analysis that considers smaller counties/cities -- by definition, census tracts always contain significantly fewer than 65,000 people).
-
-In addition to the Decennial Census and ACS data, a number of other census data products/surveys are also available. For example, see the `censusapi` R package ([here](https://github.com/hrecht/censusapi) or [here](https://www.hrecht.com/censusapi/index.html)) for access to over 300 census API endpoints. For historical census data, see the discussion [here](https://walker-data.com/census-r/other-census-and-government-data-resources.html?q=API%20endpoint#other-census-and-government-data-resources) on using NHGIS, IPUMS, and the `ipumsr` package.
-
-#### Census Variables / Codes {#sec-census-variables}
-
-Each census product collects data for many different demographic variables, and each variable is generally associated with an identifier code. In order to access census data programmatically, you often need to know the code associated with each variable of interest. When determining which variables to use, you need to consider what census product contains those variables (see @sec-census-datasets) and how they differ in terms of time frame, precision, spatial granularity (see @sec-census-hierarchy), etc.
-
-The `tidycensus` package offers a convenient generic way to search for variables across different census products using the `load_variables()` function, as described [here](https://walker-data.com/tidycensus/articles/basic-usage.html#searching-for-variables).
-
-The following websites may also be helpful for exploring the various census data products and finding the variable names and codes they contain:
-
-- Census Reporter (for ACS data): (especially )
-
-- Census Bureau's list of variable codes, e.g.:
-
- - 2020 Census codes:
-
- - 2022 ACS 5 year codes:
-
-- Census Bureau's data interface (for Decennial Census and ACS, and other census datasets):
-
-- National Historical Geographic Information System (NHGIS) (for ACS data and historical decennial Census data):
-### Accessing Census Data {#sec-census-access}
+## Accessing Census Data {#sec-census-access}
::: callout-caution
Because the boundaries of census units (e.g., tracts, block groups, blocks, etc) can change over time, it's important to make sure that the version (year) of the census data you're retrieving matches the version of the census boundary dataset you're using. The methods shown here retrieve the census boundary dataset together with the census demographic data, which ensures that this won't be a potential problem; however, this could be an issue if you use a different method which retrieves these datasets (geographic boundaries and demographic data) via separate processes.
@@ -254,7 +260,7 @@ The following sections demonstrate how to retrieve census data from the Decennia
In order to use the `tidycensus` R package, you'll need to obtain a personal API key from the US Census Bureau (which is free and available to anyone) by signing up here: . Once you have your API key, you'll need to register it in R by entering the command `census_api_key(key = "YOUR API KEY", install = TRUE)` in the console. Note that the `install = TRUE` argument means that the key is saved for all future R sessions, so you'll only need to run that command once on your computer (rather than including it in your scripts). Alternatively, you could save your key to an environment variable and retrieve it using `Sys.getenv()`. Either way will help you avoid the possibility of entering your API key into any scripts that could be shared publicly.
-#### Decennial Census {#sec-census-access-decennial}
+### Decennial Census {#sec-census-access-decennial}
This section retrieves census data from the 2020 U.S. Decennial Census, using the `get_decennial` function from the `tidycensus` package. For this example we're getting data at the 'Block Group' level (with the `geography = 'block group'` argument), for the counties defined above in the `counties_list` variable (with the `county = counties_list` argument). By setting the `geometry = TRUE` argument we'll be able to get the spatial data -- i.e., the boundaries of the census block groups -- along with the tabular data defined in the `variables` argument (see @sec-census-variables for information about how to find variable codes). In this case, we're first saving the census variables we want in the `census_vars_decennial` object, and also providing descriptive names associated with each variable code, which makes the data easier to work with later. Also, while by default the `tidycensus` package returns data in long/tidy format, we're getting the data in wide format for this example (by specifying `output = 'wide'`) because it'll be easier to work with for the interpolation method described below to estimate demographics for non-census geographies.
@@ -297,7 +303,7 @@ The output is an sf object (i.e., a dataframe-like object that also includes spa
glimpse(census_data_decennial)
```
-#### American Community Survey (ACS) {#sec-census-access-acs}
+### American Community Survey (ACS) {#sec-census-access-acs}
To get data from the ACS, you can use the `get_acs()` function, which is very similar to the `get_decennial()` function used above.
@@ -439,10 +445,11 @@ census_data_acs_state <- get_acs(geography = 'state',
Here's a view of the contents and structure of the revised `r acs_year` 5-year ACS statewide dataset:
-```{r} glimpse(census_data_acs_state)}
+```{r}
+glimpse(census_data_acs_state)
```
-#### Plot Results {#sec-census-plot}
+### Plot Results {#sec-census-plot}
@fig-suppliers-census-map shows the datasets that we'll use below to compute water system demographics (zoomed in to the area around the water systems in this study). Each water system -- the *target* dataset -- is shown with a different (randomly chosen) color. The boundaries of the census data -- the *source* dataset -- are shown in red; in this case we'll use the `r acs_year` 5-year ACS dataset. County boundaries are shown in grey (Sacramento county is show with a bold grey line).
@@ -502,7 +509,7 @@ plot_census
Now we can perform the calculations to estimate demographic characteristics for our *target* areas (water system service boundaries in the Sacramento County area) from our *source* demographic dataset (the census data we obtained above). For this example, we'll use the `r acs_year` 5-year ACS data that we retrieved above (which is saved in the `census_data_acs` variable) as our source of demographic data, and we'll estimate the following for each water system's service area:
- Population of each racial/ethnic group (using the racial/ethnic categories defined in the census dataset), and each racial/ethnic group's portion of the total service area population
-- Median household income
+- Socio-economic variables like poverty rate, median household income, income distributions, and per capita income
There are multiple ways this estimation can be done, but one of the most simple and straightforward is using an areal interpolation (essentially an area weighted average). The major simplifying assumption of this approach is that the population or other characteristic(s) of interest are evenly distributed within each unit in the *source* data -- e.g., in this case we're assuming that population (including the total population and the population of each racial/ethic group) and household income is evenly distributed within each census block group.
@@ -552,6 +559,10 @@ glimpse(census_data_filter)
### Areal Interpolation {#sec-areal-interp}
+::: callout-caution
+A population-weighted interpolation – as shown in @sec-pop-weighted-interpolation – may be more appropriate for many cases than the areal interpolation shown below. This section will likely be revised to reflect that approach at some point soon.
+:::
+
There are a couple of ways to implement the areal interpolation method. The example below uses the [`aw_interpolate`](https://chris-prener.github.io/areal/reference/aw_interpolate.html) function from the [`areal`](https://chris-prener.github.io/areal/) R package. The `sf` package's [`st_interpolate_aw`](https://r-spatial.github.io/sf/reference/interpolate_aw.html) function provides similar functionality. It's also possible to 'manually' implement the process using lower level functions from the `sf` package, which can be useful for even more control, but is more complicated to implement (see @sec-manual-calcs below for examples of 'manual' calculations that demonstrate how the interpolation function works and provide a check on the results).
Note that there are some settings that you may need to modify in the `aw_interpolate` function depending on the type of analysis you're doing. In particular, for more information about extensive versus intensive interpolations, see [this section of the documenation](https://chris-prener.github.io/areal/articles/areal-weighted-interpolation.html#extensive-and-intensive-interpolations). For more information about the `weight` argument -- which can be either `sum` or `total` -- see [this section of the documentation](https://chris-prener.github.io/areal/articles/areal-weighted-interpolation.html#calculating-weights-for-extensive-interpolations).
@@ -673,44 +684,50 @@ rm(water_systems_sac_demographics_hh_inc)
We could stop here, and save the dataset containing the results to an output file (as is done in @sec-results-save ). But, it may be useful to do some additional computations and re-formatting before saving the dataset. For example, in this case it may be useful to calculate the racial/ethnic breakdown of each system's population as percentages of the total population (in addition to the total counts derived above).
-We can start by renaming the fields that start with `population_` and `median_household_income` to indicate that they are estimates.
+```{r}
+# We can start by renaming the fields that start with population_ and median_household_income to indicate that they are estimates.
+
+# water_systems_sac_demographics <- water_systems_sac_demographics %>%
+# rename_with(.fn = ~ str_replace(.,
+# pattern = 'population_',
+# replacement = 'population_est_')) %>%
+# rename_with(.fn = ~ str_replace(.,
+# pattern = 'median_household_income',
+# replacement = 'median_household_income_est'))
+```
```{r}
+# Then add columns with each racial/ethnic group's estimated percent of the total population within each water system's service area:
+
water_systems_sac_demographics <- water_systems_sac_demographics %>%
- rename_with(.fn = ~ str_replace(.,
- pattern = 'population_',
- replacement = 'population_est_')) %>%
- rename_with(.fn = ~ str_replace(.,
- pattern = 'median_household_income',
- replacement = 'median_household_income_est'))
+ mutate(
+ across(
+ .cols = starts_with('population_'),
+ .fns = ~ round(.x / population_total * 100, 2),
+ .names = "{str_replace(.col, 'population_', 'percent_')}"
+ ),
+ .after = population_white)
```
-Then add columns with each racial/ethnic group's estimated percent of the total population within each water system's service area:
+We can also calculate the estimated poverty rate for each water system's service area.
```{r}
water_systems_sac_demographics <- water_systems_sac_demographics %>%
- mutate(
- across(
- .cols = starts_with('population_est_'),
- .fns = ~ .x / population_est_total * 100,
- .names = "{str_replace(.col, 'population_est_', 'percent_est_')}"
- ))
+ mutate(poverty_rate_percent =
+ round(100 * poverty_below_count / poverty_total_assessed,
+ 2),
+ .before = poverty_above_count)
```
-Then format the data, rounding the estimated population and median household income values to the nearest whole number, and the estimated population percentages to two decimal places:
+Then format the data, rounding the estimated values to appropriate levels of precision:
```{r}
water_systems_sac_demographics <- water_systems_sac_demographics %>%
mutate(
across(
- .cols = starts_with('population_est_'),
+ .cols = starts_with('population_'),
.fns = ~ round(.x, 0)
)) %>%
- mutate(
- across(
- .cols = starts_with('percent_est_'),
- .fns = ~ round(.x, 2)
- )) %>%
mutate(median_household_income_est = round(median_household_income_est, digits = 0))
```
@@ -1341,7 +1358,7 @@ In this case, the (un-rounded) 'manually' calculated total population for
This section is in progress...
:::
-### Population Weighted Average
+### Population Weighted Interpolation {#sec-pop-weighted-interpolation}
::: callout-warning
This section is in progress...