網路資料採集是 Python 語言非常擅長的領域,上節課我們講到,實現網路資料採集的程式通常稱之為網路爬蟲或蜘蛛程式。即便是在大資料時代,資料對於中小企業來說仍然是硬傷和短板,有些資料需要透過開放或付費的資料介面來獲得,其他的行業資料和競對資料則必須要透過網路資料採集的方式來獲得。不管使用哪種方式獲取網路資料資源,Python 語言都是非常好的選擇,因為 Python 的標準庫和三方庫都對網路資料採集提供了良好的支援。
要使用 Python 獲取網路資料,我們推薦大家使用名為requests 的三方庫,這個庫我們在之前的課程中其實已經使用過了。按照官方網站的解釋,requests是基於 Python 標準庫進行了封裝,簡化了透過 HTTP 或 HTTPS 訪問網路資源的操作。上課我們提到過,HTTP 是一個請求響應式的協議,當我們在瀏覽器中輸入正確的 URL(通常也稱為網址)並按下 Enter 鍵時,我們就向網路上的 Web 伺服器傳送了一個 HTTP 請求,伺服器在收到請求後會給我們一個 HTTP 響應。在 Chrome 瀏覽器中的選單中開啟“開發者工具”切換到“Network”選項卡就能夠檢視 HTTP 請求和響應到底是什麼樣子的,如下圖所示。

透過requests庫,我們可以讓 Python 程式向瀏覽器一樣向 Web 伺服器發起請求,並接收伺服器返回的響應,從響應中我們就可以提取出想要的資料。瀏覽器呈現給我們的網頁是用 HTML 編寫的,瀏覽器相當於是 HTML 的直譯器環境,我們看到的網頁中的內容都包含在 HTML 的標籤中。在獲取到 HTML 程式碼後,就可以從標籤的屬性或標籤體中提取內容。下面例子演示瞭如何獲取網頁 HTML 程式碼,我們透過requests庫的get函式,獲取了搜狐首頁的程式碼。
import requests
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
print(resp.text)說明:上面程式碼中的變數
resp是一個Response物件(requests庫封裝的型別),透過該物件的status_code屬性可以獲取響應狀態碼,而該物件的text屬性可以幫我們獲取到頁面的 HTML 程式碼。
由於Response物件的text是一個字串,所以我們可以利用之前講過的正則表示式的知識,從頁面的 HTML 程式碼中提取新聞的標題和連結,程式碼如下所示。
import re
import requests
pattern = re.compile(r'<a.*?href="(.*?)".*?title="(.*?)".*?>')
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
all_matches = pattern.findall(resp.text)
for href, title in all_matches:
print(href)
print(title)除了文字內容,我們也可以使用requests庫透過 URL 獲取二進位制資源。下面的例子演示瞭如何獲取百度 Logo 並儲存到名為baidu.png的本地檔案中。可以在百度的首頁上右鍵點選百度Logo,並透過“複製圖片地址”選單項獲取圖片的 URL。
import requests
resp = requests.get('https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png')
with open('baidu.png', 'wb') as file:
file.write(resp.content)說明:
Response物件的content屬性可以獲得伺服器響應的二進位制資料。
requests庫非常好用而且功能上也比較強大和完整,具體的內容我們在使用的過程中為大家一點點剖析。想解鎖關於requests庫更多的知識,可以閱讀它的官方文件。
接下來,我們以“豆瓣電影”為例,為大家講解如何編寫爬蟲程式碼。按照上面提供的方法,我們先使用requests獲取到網頁的HTML程式碼,然後將整個程式碼看成一個長字串,這樣我們就可以使用正則表示式的捕獲組從字串提取我們需要的內容。下面的程式碼演示瞭如何從豆瓣電影獲取排前250名的電影的名稱。豆瓣電影Top250的頁面結構和對應程式碼如下圖所示,可以看出,每頁共展示了25部電影,如果要獲取到 Top250 資料,我們共需要訪問10個頁面,對應的地址是https://movie.douban.com/top250?start=xxx,這裡的xxx如果為0就是第一頁,如果xxx的值是100,那麼我們可以訪問到第五頁。為了程式碼簡單易讀,我們只獲取電影的標題和評分。

import random
import re
import time
import requests
for page in range(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 如果不設定HTTP請求頭中的User-Agent,豆瓣會檢測出不是瀏覽器而阻止我們的請求。
# 透過get函式的headers引數設定User-Agent的值,具體的值可以在瀏覽器的開發者工具檢視到。
# 用爬蟲訪問大部分網站時,將爬蟲偽裝成來自瀏覽器的請求都是非常重要的一步。
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
)
# 透過正則表示式獲取class屬性為title且標籤體不以&開頭的span標籤並用捕獲組提取標籤內容
pattern1 = re.compile(r'<span class="title">([^&]*?)</span>')
titles = pattern1.findall(resp.text)
# 透過正則表示式獲取class屬性為rating_num的span標籤並用捕獲組提取標籤內容
pattern2 = re.compile(r'<span class="rating_num".*?>(.*?)</span>')
ranks = pattern2.findall(resp.text)
# 使用zip壓縮兩個列表,迴圈遍歷所有的電影標題和評分
for title, rank in zip(titles, ranks):
print(title, rank)
# 隨機休眠1-5秒,避免爬取頁面過於頻繁
time.sleep(random.random() * 4 + 1)說明:透過分析豆瓣網的robots協議,我們發現豆瓣網並不拒絕百度爬蟲獲取它的資料,因此我們也可以將爬蟲偽裝成百度的爬蟲,將
get函式的headers引數修改為:headers={'User-Agent': 'BaiduSpider'}。
讓爬蟲程式隱匿自己的身份對編寫爬蟲程式來說是比較重要的,很多網站對爬蟲都比較反感的,因為爬蟲會耗費掉它們很多的網路頻寬並製造很多無效的流量。要隱匿身份通常需要使用商業 IP 代理(如蘑菇代理、芝麻代理、快代理等),讓被爬取的網站無法獲取爬蟲程式來源的真實 IP 地址,也就無法簡單的透過 IP 地址對爬蟲程式進行封禁。
下面以蘑菇代理為例,為大家講解商業 IP 代理的使用方法。首先需要在該網站註冊一個賬號,註冊賬號後就可以購買相應的套餐來獲得商業 IP 代理。作為商業用途,建議大家購買不限量套餐,這樣可以根據實際需要獲取足夠多的代理 IP 地址;作為學習用途,可以購買包時套餐或根據自己的需求來決定。蘑菇代理提供了兩種接入代理的方式,分別是 API 私密代理和 HTTP 隧道代理,前者是透過請求蘑菇代理的 API 介面獲取代理伺服器地址,後者是直接使用統一的入口(蘑菇代理提供的域名)進行接入。
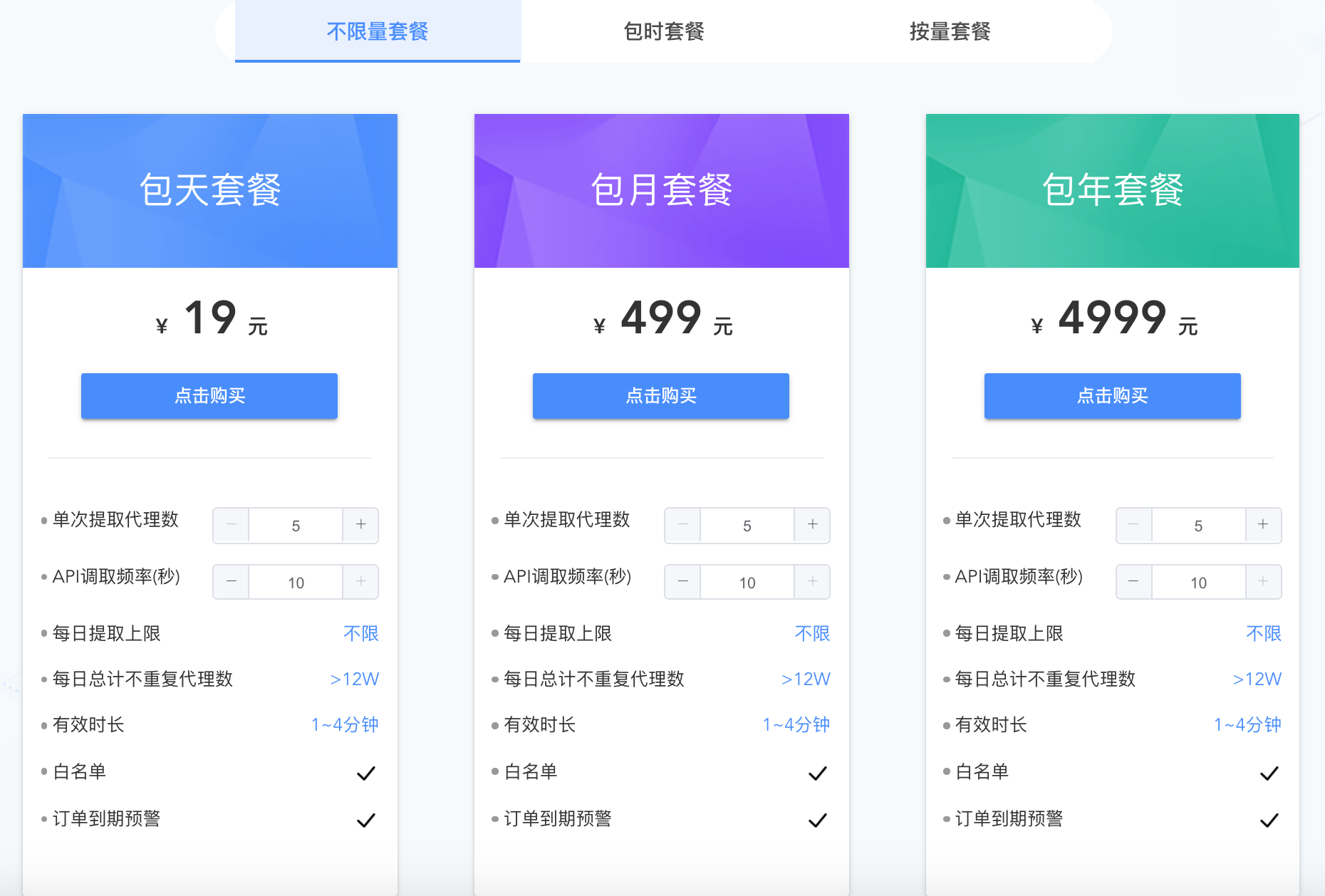
下面,我們以HTTP隧道代理為例,為大家講解接入 IP 代理的方式,大家也可以直接參考蘑菇代理官網提供的程式碼來為爬蟲設定代理。
import requests
APP_KEY = 'Wnp******************************XFx'
PROXY_HOST = 'secondtransfer.moguproxy.com:9001'
for page in range(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 需要在HTTP請求頭設定代理的身份認證方式
headers={
'Proxy-Authorization': f'Basic {APP_KEY}',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4'
},
# 設定代理伺服器
proxies={
'http': f'http://{PROXY_HOST}',
'https': f'https://{PROXY_HOST}'
},
verify=False
)
pattern1 = re.compile(r'<span class="title">([^&]*?)</span>')
titles = pattern1.findall(resp.text)
pattern2 = re.compile(r'<span class="rating_num".*?>(.*?)</span>')
ranks = pattern2.findall(resp.text)
for title, rank in zip(titles, ranks):
print(title, rank)說明:上面的程式碼需要修改
APP_KEY為自己建立的訂單對應的Appkey值,這個值可以在使用者中心使用者訂單中檢視到。蘑菇代理提供了免費的 API 代理和 HTTP 隧道代理試用,但是試用的代理接通率不能保證,建議大家還是直接購買一個在自己支付能力範圍內的代理服務來體驗。
Python 語言能做的事情真的很多,就網路資料採集這一項而言,Python 幾乎是一枝獨秀的,大量的企業和個人都在使用 Python 從網路上獲取自己需要的資料,這可能也是你將來日常工作的一部分。另外,用編寫正則表示式的方式從網頁中提取內容雖然可行,但是寫出一個能夠滿足需求的正則表示式本身也不是件容易的事情,這一點對於新手來說尤為明顯。在下一節課中,我們將會為大家介紹另外兩種從頁面中提取資料的方法,雖然從效能上來講,它們可能不如正則表示式,但是卻降低了編碼的複雜性,相信大家會喜歡上它們的。