爬蟲(crawler)也經常被稱為網路蜘蛛(spider),是按照一定的規則自動瀏覽網站並獲取所需資訊的機器人程式(自動化指令碼程式碼),被廣泛的應用於網際網路搜尋引擎和資料採集。使用過網際網路和瀏覽器的人都知道,網頁中除了供使用者閱讀的文字資訊之外,還包含一些超連結,網路爬蟲正是透過網頁中的超連結資訊,不斷獲得網路上其它頁面的地址,然後持續的進行資料採集。正因如此,網路資料採集的過程就像一個爬蟲或者蜘蛛在網路上漫遊,所以才被形象的稱為爬蟲或者網路蜘蛛。
在理想的狀態下,所有 ICP(Internet Content Provider)都應該為自己的網站提供 API 介面來共享它們允許其他程式獲取的資料,在這種情況下就根本不需要爬蟲程式。國內比較有名的電商平臺(如淘寶、京東等)、社交平臺(如微博、微信等)等都提供了自己的 API 介面,但是這類 API 介面通常會對可以抓取的資料以及抓取資料的頻率進行限制。對於大多數的公司而言,及時的獲取行業資料和競對資料是企業生存的重要環節之一,然而對大部分企業來說,資料都是其與生俱來的短板。在這種情況下,合理的利用爬蟲來獲取資料並從中提取出有商業價值的資訊對這些企業來說就顯得至關重要的。
爬蟲的應用領域其實非常廣泛,下面我們列舉了其中的一部分,有興趣的讀者可以自行探索相關內容。
- 搜尋引擎
- 新聞聚合
- 社交應用
- 輿情監控
- 行業資料
經常聽人說起“爬蟲寫得好,牢飯吃到飽”,那麼程式設計爬蟲程式是否違法呢?關於這個問題,我們可以從以下幾個角度進行解讀。
- 網路爬蟲這個領域目前還屬於拓荒階段,雖然網際網路世界已經透過自己的遊戲規則建立起了一定的道德規範,即 Robots 協議(全稱是“網路爬蟲排除標準”),但法律部分還在建立和完善中,也就是說,現在這個領域暫時還是灰色地帶。
- “法不禁止即為許可”,如果爬蟲就像瀏覽器一樣獲取的是前端顯示的資料(網頁上的公開資訊)而不是網站後臺的私密敏感資訊,就不太擔心法律法規的約束,因為目前大資料產業鏈的發展速度遠遠超過了法律的完善程度。
- 在爬取網站的時候,需要限制自己的爬蟲遵守 Robots 協議,同時控制網路爬蟲程式的抓取資料的速度;在使用資料的時候,必須要尊重網站的智慧財產權(從Web 2.0時代開始,雖然Web上的資料很多都是由使用者提供的,但是網站平臺是投入了運營成本的,當用戶在註冊和釋出內容時,平臺通常就已經獲得了對資料的所有權、使用權和分發權)。如果違反了這些規定,在打官司的時候敗訴機率相當高。
- 適當的隱匿自己的身份在編寫爬蟲程式時必要的,而且最好不要被對方舉證你的爬蟲有破壞別人動產(例如伺服器)的行為。
- 不要在公網(如程式碼託管平臺)上去開源或者展示你的爬蟲程式碼,這些行為通常會給自己帶來不必要的麻煩。
大多數網站都會定義robots.txt檔案,這是一個君子協議,並不是所有爬蟲都必須遵守的遊戲規則。下面以淘寶的robots.txt檔案為例,看看淘寶網對爬蟲有哪些限制。
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
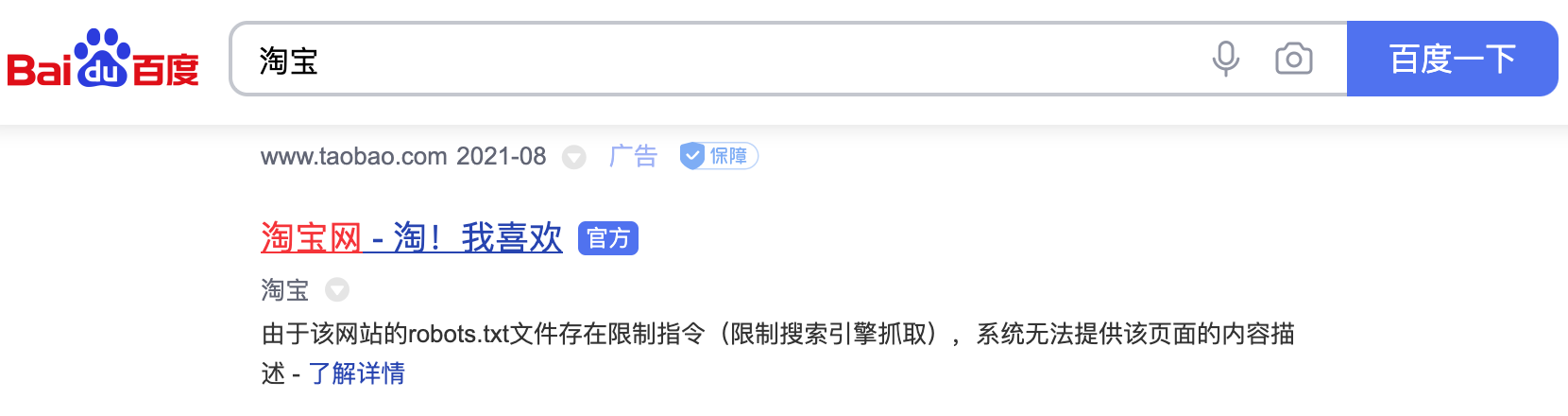
透過上面的檔案可以看出,淘寶禁止百度爬蟲爬取它任何資源,因此當你在百度搜索“淘寶”的時候,搜尋結果下方會出現:“由於該網站的robots.txt檔案存在限制指令(限制搜尋引擎抓取),系統無法提供該頁面的內容描述”。百度作為一個搜尋引擎,至少在表面上遵守了淘寶網的robots.txt協議,所以使用者不能從百度上搜索到淘寶內部的產品資訊。
圖1. 百度搜索淘寶的結果
下面是豆瓣網的robots.txt檔案,大家可以自行解讀,看看它做出了什麼樣的限制。
User-agent: *
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /forum/
Disallow: /new_subject
Disallow: /service/iframe
Disallow: /j/
Disallow: /link2/
Disallow: /recommend/
Disallow: /doubanapp/card
Disallow: /update/topic/
Disallow: /share/
Allow: /ads.txt
Sitemap: https://www.douban.com/sitemap_index.xml
Sitemap: https://www.douban.com/sitemap_updated_index.xml
# Crawl-delay: 5
User-agent: Wandoujia Spider
Disallow: /
User-agent: Mediapartners-Google
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /j/
在開始講解爬蟲之前,我們稍微對超文字傳輸協議(HTTP)做一些回顧,因為我們在網頁上看到的內容通常是瀏覽器執行 HTML (超文字標記語言)得到的結果,而 HTTP 就是傳輸 HTML 資料的協議。HTTP 和其他很多應用級協議一樣是構建在 TCP(傳輸控制協議)之上的,它利用了 TCP 提供的可靠的傳輸服務實現了 Web 應用中的資料交換。按照維基百科上的介紹,設計 HTTP 最初的目的是為了提供一種釋出和接收 HTML 頁面的方法,也就是說,這個協議是瀏覽器和 Web 伺服器之間傳輸的資料的載體。關於 HTTP 的詳細資訊以及目前的發展狀況,大家可以閱讀《HTTP 協議入門》、《網際網路協議入門》、《圖解 HTTPS 協議》等文章進行了解。
下圖是我在四川省網路通訊技術重點實驗室工作期間用開源協議分析工具 Ethereal(WireShark 的前身)擷取的訪問百度首頁時的 HTTP 請求和響應的報文(協議資料),由於 Ethereal 擷取的是經過網路介面卡的資料,因此可以清晰的看到從物理鏈路層到應用層的協議資料。
圖2. HTTP請求
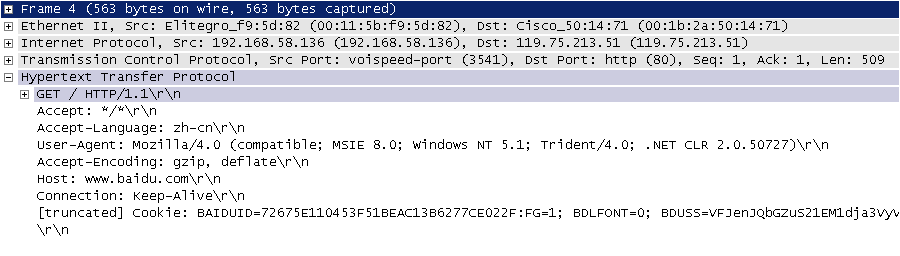
HTTP 請求通常是由請求行、請求頭、空行、訊息體四個部分構成,如果沒有資料發給伺服器,訊息體就不是必須的部分。請求行中包含了請求方法(GET、POST 等,如下表所示)、資源路徑和協議版本;請求頭由若干鍵值對構成,包含了瀏覽器、編碼方式、首選語言、快取策略等資訊;請求頭的後面是空行和訊息體。

圖3. HTTP響應
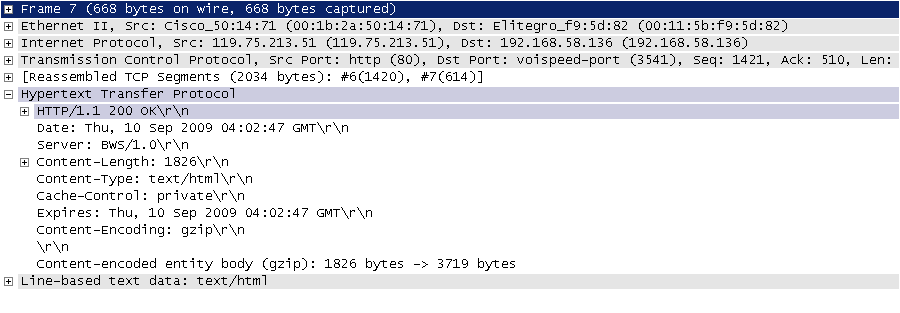
HTTP 響應通常是由響應行、響應頭、空行、訊息體四個部分構成,其中訊息體是服務響應的資料,可能是 HTML 頁面,也有可能是JSON或二進位制資料等。響應行中包含了協議版本和響應狀態碼,響應狀態碼有很多種,常見的如下表所示。

下面我們先介紹一些開發爬蟲程式的輔助工具,這些工具相信能幫助你事半功倍。
-
Chrome Developer Tools:谷歌瀏覽器內建的開發者工具。該工具最常用的幾個功能模組是:
- 元素(ELements):用於檢視或修改 HTML 元素的屬性、CSS 屬性、監聽事件等。CSS 可以即時修改,即時顯示,大大方便了開發者除錯頁面。
- 控制檯(Console):用於執行一次性程式碼,檢視 JavaScript 物件,檢視除錯日誌資訊或異常資訊。控制檯其實就是一個執行 JavaScript 程式碼的互動式環境。
- 原始碼(Sources):用於檢視頁面的 HTML 檔案原始碼、JavaScript 原始碼、CSS 原始碼,此外最重要的是可以除錯 JavaScript 原始碼,可以給程式碼新增斷點和單步執行。
- 網路(Network):用於 HTTP 請求、HTTP 響應以及與網路連線相關的資訊。
- 應用(Application):用於檢視瀏覽器本地儲存、後臺任務等內容,本地儲存主要包括Cookie、Local Storage、Session Storage等。
-
Postman:功能強大的網頁除錯與 RESTful 請求工具。Postman可以幫助我們模擬請求,非常方便的定製我們的請求以及檢視伺服器的響應。
-
HTTPie:命令列HTTP客戶端。
安裝。
pip install httpie
使用。
http --header http --header https://movie.douban.com/ HTTP/1.1 200 OK Connection: keep-alive Content-Encoding: gzip Content-Type: text/html; charset=utf-8 Date: Tue, 24 Aug 2021 16:48:00 GMT Keep-Alive: timeout=30 Server: dae Set-Cookie: bid=58h4BdKC9lM; Expires=Wed, 24-Aug-22 16:48:00 GMT; Domain=.douban.com; Path=/ Strict-Transport-Security: max-age=15552000 Transfer-Encoding: chunked X-Content-Type-Options: nosniff X-DOUBAN-NEWBID: 58h4BdKC9lM
-
builtwith庫:識別網站所用技術的工具。安裝。
pip install builtwith
使用。
import ssl import builtwith ssl._create_default_https_context = ssl._create_unverified_context print(builtwith.parse('http://www.bootcss.com/'))
-
python-whois庫:查詢網站所有者的工具。安裝。
pip3 install python-whois
使用。
import whois print(whois.whois('https://www.bootcss.com'))
一個基本的爬蟲通常分為資料採集(網頁下載)、資料處理(網頁解析)和資料儲存(將有用的資訊持久化)三個部分的內容,當然更為高階的爬蟲在資料採集和處理時會使用併發程式設計或分散式技術,這就需要有排程器(安排執行緒或程序執行對應的任務)、後臺管理程式(監控爬蟲的工作狀態以及檢查資料抓取的結果)等的參與。
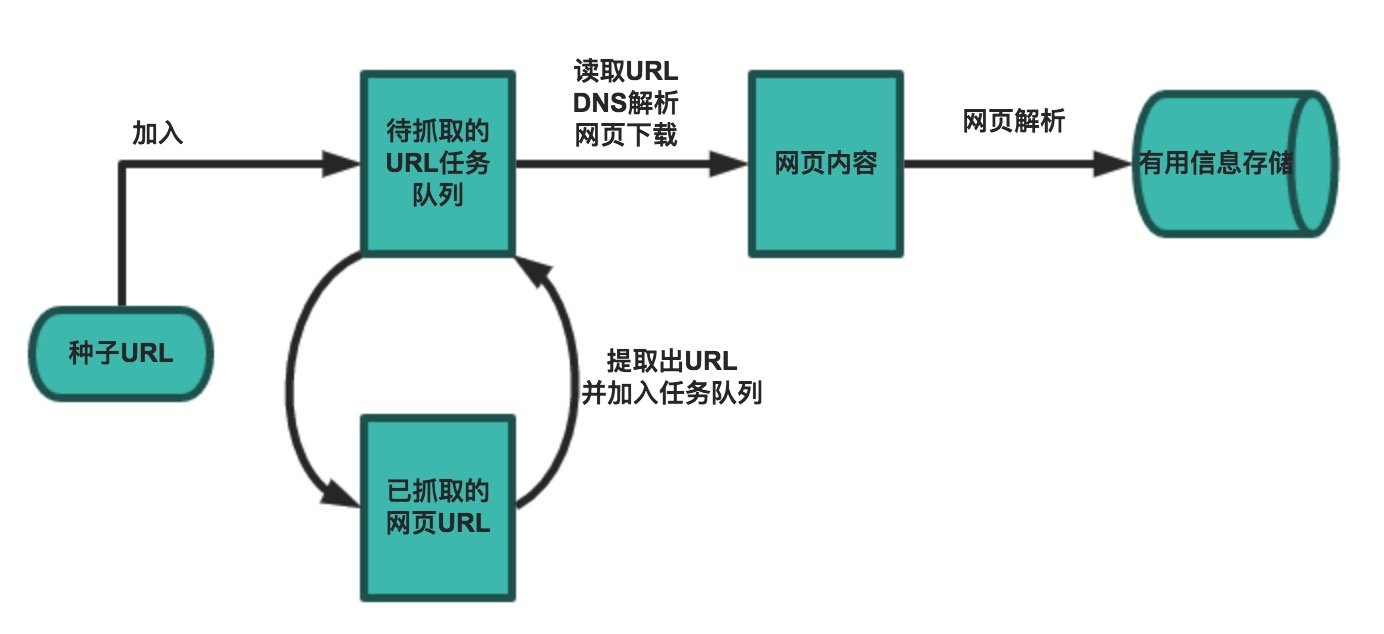
一般來說,爬蟲的工作流程包括以下幾個步驟:
- 設定抓取目標(種子頁面/起始頁面)並獲取網頁。
- 當伺服器無法訪問時,按照指定的重試次數嘗試重新下載頁面。
- 在需要的時候設定使用者代理或隱藏真實IP,否則可能無法訪問頁面。
- 對獲取的頁面進行必要的解碼操作然後抓取出需要的資訊。
- 在獲取的頁面中透過某種方式(如正則表示式)抽取出頁面中的連結資訊。
- 對連結進行進一步的處理(獲取頁面並重覆上面的動作)。
- 將有用的資訊進行持久化以備後續的處理。