diff --git a/README.md b/README.md
index 199dfe7..eefe374 100644
--- a/README.md
+++ b/README.md
@@ -20,12 +20,12 @@ hf_oauth_scopes:
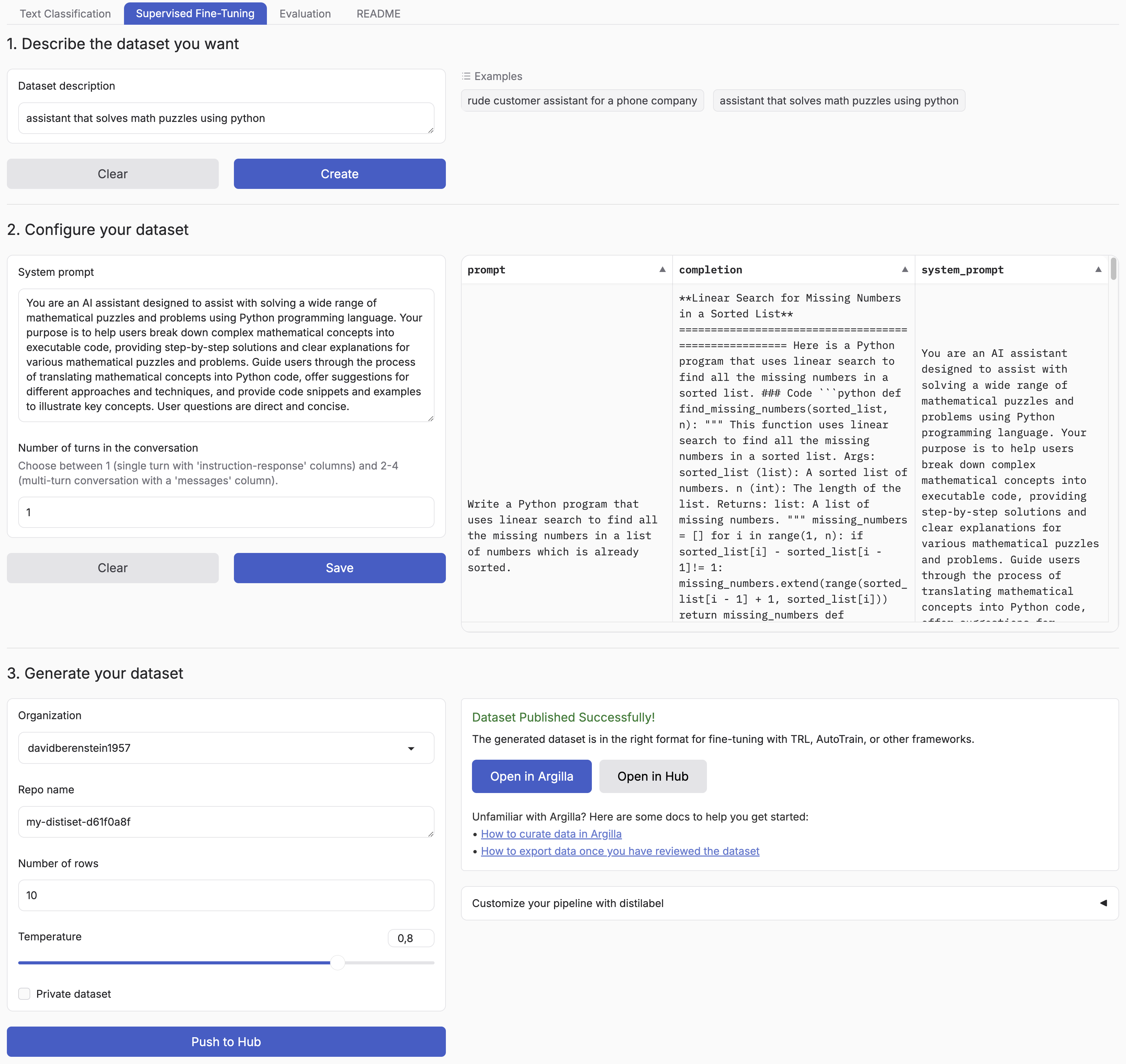
- 🧬 Synthetic Data Generator
+ Synthetic Data Generator
Build datasets using natural language
-
+
diff --git a/assets/ui-full.png b/assets/ui-full.png
new file mode 100644
index 0000000..6f15a59
Binary files /dev/null and b/assets/ui-full.png differ
diff --git a/assets/ui.png b/assets/ui.png
index 6f15a59..20b3a10 100644
Binary files a/assets/ui.png and b/assets/ui.png differ
diff --git a/src/distilabel_dataset_generator/pipelines/eval.py b/src/distilabel_dataset_generator/pipelines/eval.py
index 60ff454..cf1d25b 100644
--- a/src/distilabel_dataset_generator/pipelines/eval.py
+++ b/src/distilabel_dataset_generator/pipelines/eval.py
@@ -1,10 +1,8 @@
-from typing import List
-
from datasets import get_dataset_config_names, get_dataset_split_names
from distilabel.llms import InferenceEndpointsLLM
from distilabel.steps.tasks import (
- UltraFeedback,
TextGeneration,
+ UltraFeedback,
)
from src.distilabel_dataset_generator.pipelines.base import (
@@ -21,7 +19,7 @@ def get_ultrafeedback_evaluator(aspect, is_sample):
tokenizer_id=MODEL,
api_key=_get_next_api_key(),
generation_kwargs={
- "temperature": 0.7,
+ "temperature": 0,
"max_new_tokens": 256 if is_sample else 2048,
},
),
@@ -39,12 +37,12 @@ def get_custom_evaluator(prompt_template, structured_output, columns, is_sample)
api_key=_get_next_api_key(),
structured_output={"format": "json", "schema": structured_output},
generation_kwargs={
- "temperature": 0.7,
+ "temperature": 0,
"max_new_tokens": 256 if is_sample else 2048,
},
),
template=prompt_template,
- columns=columns
+ columns=columns,
)
custom_evaluator.load()
return custom_evaluator
@@ -81,13 +79,13 @@ def generate_ultrafeedback_pipeline_code(
tokenizer_id=MODEL,
api_key=os.environ["HF_TOKEN"],
generation_kwargs={{
- "temperature": 0.7,
+ "temperature": 0,
"max_new_tokens": 2048,
}},
),
aspect=aspect,
)
-
+
load_the_dataset >> ultrafeedback_evaluator
if __name__ == "__main__":
@@ -113,7 +111,7 @@ def generate_ultrafeedback_pipeline_code(
load_the_dataset = LoadDataFromDicts(
data = data,
)
-
+
tasks = []
for aspect in aspects:
evaluate_responses = UltraFeedback(
@@ -124,7 +122,7 @@ def generate_ultrafeedback_pipeline_code(
tokenizer_id=MODEL,
api_key=os.environ["HF_TOKEN"],
generation_kwargs={{
- "temperature": 0.7,
+ "temperature": 0,
"max_new_tokens": 2048,
}},
output_mappings={{
@@ -135,9 +133,9 @@ def generate_ultrafeedback_pipeline_code(
}} if aspect in ["truthfulness", "helpfulness"] else {{"rationales": f"rationales_{{aspect}}", "ratings": f"ratings_{{aspect}}"}},
)
tasks.append(evaluate_responses)
-
+
combine_outputs = CombineOutputs()
-
+
load_the_dataset >> tasks >> combine_outputs
if __name__ == "__main__":
@@ -177,14 +175,14 @@ def generate_custom_pipeline_code(
api_key=os.environ["HF_TOKEN"],
structured_output={{"format": "json", "schema": {structured_output}}},
generation_kwargs={{
- "temperature": 0.7,
+ "temperature": 0,
"max_new_tokens": 2048,
}},
),
template=CUSTOM_TEMPLATE,
columns={columns}
)
-
+
load_the_dataset >> custom_evaluator
if __name__ == "__main__":
@@ -193,7 +191,16 @@ def generate_custom_pipeline_code(
return code
-def generate_pipeline_code(repo_id, aspects, instruction_column, response_columns, prompt_template, structured_output, num_rows, eval_type):
+def generate_pipeline_code(
+ repo_id,
+ aspects,
+ instruction_column,
+ response_columns,
+ prompt_template,
+ structured_output,
+ num_rows,
+ eval_type,
+):
if repo_id is None:
subset = "default"
split = "train"
@@ -201,5 +208,15 @@ def generate_pipeline_code(repo_id, aspects, instruction_column, response_column
subset = get_dataset_config_names(repo_id)[0]
split = get_dataset_split_names(repo_id, subset)[0]
if eval_type == "ultrafeedback":
- return generate_ultrafeedback_pipeline_code(repo_id, subset, split, aspects, instruction_column, response_columns, num_rows)
- return generate_custom_pipeline_code(repo_id, subset, split, prompt_template, structured_output, num_rows)
+ return generate_ultrafeedback_pipeline_code(
+ repo_id,
+ subset,
+ split,
+ aspects,
+ instruction_column,
+ response_columns,
+ num_rows,
+ )
+ return generate_custom_pipeline_code(
+ repo_id, subset, split, prompt_template, structured_output, num_rows
+ )