diff --git a/docs-website/sidebars.js b/docs-website/sidebars.js
index 06838f2e686bc0..8f3da2050a9b7f 100644
--- a/docs-website/sidebars.js
+++ b/docs-website/sidebars.js
@@ -113,6 +113,18 @@ module.exports = {
id: "docs/automations/snowflake-tag-propagation",
className: "saasOnly",
},
+ {
+ label: "AI Classification",
+ type: "doc",
+ id: "docs/automations/ai-term-suggestion",
+ className: "saasOnly",
+ },
+ {
+ label: "AI Documentation",
+ type: "doc",
+ id: "docs/automations/ai-docs",
+ className: "saasOnly",
+ },
],
},
{
diff --git a/docs/api/datahub-apis.md b/docs/api/datahub-apis.md
index 6bb793a59a86e8..c46aacde3a0cb5 100644
--- a/docs/api/datahub-apis.md
+++ b/docs/api/datahub-apis.md
@@ -2,18 +2,16 @@
DataHub has several APIs to manipulate metadata on the platform. Here's the list of APIs and their pros and cons to help you choose the right one for your use case.
-| API | Definition | Pros | Cons |
-|--------------------------------------------------------------------------------|------------------------------------|------------------------------------------|-------------------------------------------------------------|
-| **[Python SDK](/metadata-ingestion/as-a-library.md)** | SDK | Highly flexible, Good for bulk execution | Requires an understanding of the metadata change event |
-| **[Java SDK](/metadata-integration/java/as-a-library.md)** | SDK | Highly flexible, Good for bulk execution | Requires an understanding of the metadata change event |
-| **[GraphQL API](docs/api/graphql/getting-started.md)** | GraphQL interface | Intuitive; mirrors UI capabilities | Less flexible than SDKs; requires knowledge of GraphQL syntax |
-| **[OpenAPI](docs/api/openapi/openapi-usage-guide.md)** (Not Recommended) | Lower-level API for advanced users | | Generally not recommended for typical use cases |
+| API | Definition | Pros | Cons |
+| ---------------------------------------------------------- | ---------------------------------- | ---------------------------------------- | ----------------------------------------------------------------------- |
+| **[Python SDK](/metadata-ingestion/as-a-library.md)** | SDK | Highly flexible, Good for bulk execution | Requires an understanding of the metadata change event |
+| **[Java SDK](/metadata-integration/java/as-a-library.md)** | SDK | Highly flexible, Good for bulk execution | Requires an understanding of the metadata change event |
+| **[GraphQL API](docs/api/graphql/getting-started.md)** | GraphQL interface | Intuitive; mirrors UI capabilities | Less flexible than SDKs; requires knowledge of GraphQL syntax |
+| **[OpenAPI](docs/api/openapi/openapi-usage-guide.md)** | Lower-level API for advanced users | Most powerful and flexible | Can be hard to use for straightforward use cases; no corresponding SDKs |
In general, **Python and Java SDKs** are our most recommended tools for extending and customizing the behavior of your DataHub instance.
We don't recommend using the **OpenAPI** directly, as it's more complex and less user-friendly than the other APIs.
-
-
## Python and Java SDK
We offer an SDK for both Python and Java that provide full functionality when it comes to CRUD operations and any complex functionality you may want to build into DataHub. We recommend using the SDKs for most use cases. Here are the examples of how to use the SDKs:
@@ -23,22 +21,22 @@ We offer an SDK for both Python and Java that provide full functionality when it
- Creating custom metadata entities
Learn more about the SDKs:
+
- **[Python SDK →](/metadata-ingestion/as-a-library.md)**
- **[Java SDK →](/metadata-integration/java/as-a-library.md)**
-
## GraphQL API
The `graphql` API serves as the primary public API for the platform. It can be used to fetch and update metadata programatically in the language of your choice. Intended as a higher-level API that simplifies the most common operations.
We recommend using the GraphQL API if you're getting started with DataHub since it's more user-friendly and straighfowrad. Here are some examples of how to use the GraphQL API:
+
- Search for datasets with conditions
- Update a certain field of a dataset
Learn more about the GraphQL API:
-- **[GraphQL API →](docs/api/graphql/getting-started.md)**
-
+- **[GraphQL API →](docs/api/graphql/getting-started.md)**
## DataHub API Comparison
@@ -47,59 +45,59 @@ Here's an overview of what each API can do.
> Last Updated : Feb 16 2024
-| Feature | GraphQL | Python SDK | OpenAPI |
-|------------------------------------|------------------------------------------------------------------------------|------------------------------------------------------------------------------|---------|
-| Create a Dataset | 🚫 | ✅ [[Guide]](/docs/api/tutorials/datasets.md) | ✅ |
-| Delete a Dataset (Soft Delete) | ✅ [[Guide]](/docs/api/tutorials/datasets.md#delete-dataset) | ✅ [[Guide]](/docs/api/tutorials/datasets.md#delete-dataset) | ✅ |
-| Delete a Dataset (Hard Delete) | 🚫 | ✅ [[Guide]](/docs/api/tutorials/datasets.md#delete-dataset) | ✅ |
-| Search a Dataset | ✅ [[Guide]](/docs/how/search.md#graphql) | ✅ | ✅ |
-| Read a Dataset Deprecation | ✅ | ✅ | ✅ |
-| Read Dataset Entities (V2) | ✅ | ✅ | ✅ |
-| Create a Tag | ✅ [[Guide]](/docs/api/tutorials/tags.md#create-tags) | ✅ [[Guide]](/docs/api/tutorials/tags.md#create-tags) | ✅ |
-| Read a Tag | ✅ [[Guide]](/docs/api/tutorials/tags.md#read-tags) | ✅ [[Guide]](/docs/api/tutorials/tags.md#read-tags) | ✅ |
-| Add Tags to a Dataset | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags-to-a-dataset) | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags-to-a-dataset) | ✅ |
-| Add Tags to a Column of a Dataset | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags-to-a-column-of-a-dataset) | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags-to-a-column-of-a-dataset) | ✅ |
-| Remove Tags from a Dataset | ✅ [[Guide]](/docs/api/tutorials/tags.md#remove-tags) | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags#remove-tags) | ✅ |
-| Create Glossary Terms | ✅ [[Guide]](/docs/api/tutorials/terms.md#create-terms) | ✅ [[Guide]](/docs/api/tutorials/terms.md#create-terms) | ✅ |
-| Read Terms from a Dataset | ✅ [[Guide]](/docs/api/tutorials/terms.md#read-terms) | ✅ [[Guide]](/docs/api/tutorials/terms.md#read-terms) | ✅ |
-| Add Terms to a Column of a Dataset | ✅ [[Guide]](/docs/api/tutorials/terms.md#add-terms-to-a-column-of-a-dataset) | ✅ [[Guide]](/docs/api/tutorials/terms.md#add-terms-to-a-column-of-a-dataset) | ✅ |
-| Add Terms to a Dataset | ✅ [[Guide]](/docs/api/tutorials/terms.md#add-terms-to-a-dataset) | ✅ [[Guide]](/docs/api/tutorials/terms.md#add-terms-to-a-dataset) | ✅ |
-| Create Domains | ✅ [[Guide]](/docs/api/tutorials/domains.md#create-domain) | ✅ [[Guide]](/docs/api/tutorials/domains.md#create-domain) | ✅ |
-| Read Domains | ✅ [[Guide]](/docs/api/tutorials/domains.md#read-domains) | ✅ [[Guide]](/docs/api/tutorials/domains.md#read-domains) | ✅ |
-| Add Domains to a Dataset | ✅ [[Guide]](/docs/api/tutorials/domains.md#add-domains) | ✅ [[Guide]](/docs/api/tutorials/domains.md#add-domains) | ✅ |
-| Remove Domains from a Dataset | ✅ [[Guide]](/docs/api/tutorials/domains.md#remove-domains) | ✅ [[Guide]](/docs/api/tutorials/domains.md#remove-domains) | ✅ |
-| Create / Upsert Users | ✅ [[Guide]](/docs/api/tutorials/owners.md#upsert-users) | ✅ [[Guide]](/docs/api/tutorials/owners.md#upsert-users) | ✅ |
-| Create / Upsert Group | ✅ [[Guide]](/docs/api/tutorials/owners.md#upsert-group) | ✅ [[Guide]](/docs/api/tutorials/owners.md#upsert-group) | ✅ |
-| Read Owners of a Dataset | ✅ [[Guide]](/docs/api/tutorials/owners.md#read-owners) | ✅ [[Guide]](/docs/api/tutorials/owners.md#read-owners) | ✅ |
-| Add Owner to a Dataset | ✅ [[Guide]](/docs/api/tutorials/owners.md#add-owners) | ✅ [[Guide]](/docs/api/tutorials/owners.md#add-owners#remove-owners) | ✅ |
-| Remove Owner from a Dataset | ✅ [[Guide]](/docs/api/tutorials/owners.md#remove-owners) | ✅ [[Guide]](/docs/api/tutorials/owners.md) | ✅ |
-| Add Lineage | ✅ [[Guide]](/docs/api/tutorials/lineage.md) | ✅ [[Guide]](/docs/api/tutorials/lineage.md#add-lineage) | ✅ |
-| Add Column Level (Fine Grained) Lineage | 🚫 | ✅ [[Guide]](docs/api/tutorials/lineage.md#add-column-level-lineage) | ✅ |
-| Add Documentation (Description) to a Column of a Dataset | ✅ [[Guide]](/docs/api/tutorials/descriptions.md#add-description-on-column) | ✅ [[Guide]](/docs/api/tutorials/descriptions.md#add-description-on-column) | ✅ |
-| Add Documentation (Description) to a Dataset | ✅ [[Guide]](/docs/api/tutorials/descriptions.md#add-description-on-dataset) | ✅ [[Guide]](/docs/api/tutorials/descriptions.md#add-description-on-dataset) | ✅ |
-| Add / Remove / Replace Custom Properties on a Dataset | 🚫 | ✅ [[Guide]](/docs/api/tutorials/custom-properties.md) | ✅ |
-| Add ML Feature to ML Feature Table | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#add-mlfeature-to-mlfeaturetable) | ✅ |
-| Add ML Feature to MLModel | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#add-mlfeature-to-mlmodel) | ✅ |
-| Add ML Group to MLFeatureTable | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#add-mlgroup-to-mlfeaturetable) | ✅ |
-| Create MLFeature | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlfeature) | ✅ |
-| Create MLFeatureTable | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlfeaturetable) | ✅ |
-| Create MLModel | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlmodel) | ✅ |
-| Create MLModelGroup | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlmodelgroup) | ✅ |
-| Create MLPrimaryKey | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlprimarykey) | ✅ |
-| Create MLFeatureTable | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlfeaturetable)| ✅ |
-| Read MLFeature | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlfeature) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlfeature) | ✅ |
-| Read MLFeatureTable | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlfeaturetable) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlfeaturetable) | ✅ |
-| Read MLModel | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlmodel) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlmodel) | ✅ |
-| Read MLModelGroup | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlmodelgroup) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlmodelgroup) | ✅ |
-| Read MLPrimaryKey | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlprimarykey) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlprimarykey) | ✅ |
-| Create Data Product | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/create_dataproduct.py) | ✅ |
-| Create Lineage Between Chart and Dashboard | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_chart_dashboard.py) | ✅ |
-| Create Lineage Between Dataset and Chart | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_dataset_chart.py) | ✅ |
-| Create Lineage Between Dataset and DataJob | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_dataset_job_dataset.py) | ✅ |
-| Create Finegrained Lineage as DataJob for Dataset | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_datajob_finegrained.py) | ✅ |
-| Create Finegrained Lineage for Dataset | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_dataset_finegrained.py) | ✅ |
-| Create Dataset Lineage with Kafka | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_kafka.py) | ✅ |
-| Create Dataset Lineage with MCPW & Rest Emitter | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_mcpw_rest.py) | ✅ |
-| Create Dataset Lineage with Rest Emitter | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_rest.py) | ✅ |
-| Create DataJob with Dataflow | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_job_dataflow.py) [[Simple]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_job_dataflow_new_api_simple.py) [[Verbose]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_job_dataflow_new_api_verbose.py) | ✅ |
-| Create Programmatic Pipeline | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/programatic_pipeline.py) | ✅ |
+| Feature | GraphQL | Python SDK | OpenAPI |
+| -------------------------------------------------------- | ----------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- |
+| Create a Dataset | 🚫 | ✅ [[Guide]](/docs/api/tutorials/datasets.md) | ✅ |
+| Delete a Dataset (Soft Delete) | ✅ [[Guide]](/docs/api/tutorials/datasets.md#delete-dataset) | ✅ [[Guide]](/docs/api/tutorials/datasets.md#delete-dataset) | ✅ |
+| Delete a Dataset (Hard Delete) | 🚫 | ✅ [[Guide]](/docs/api/tutorials/datasets.md#delete-dataset) | ✅ |
+| Search a Dataset | ✅ [[Guide]](/docs/how/search.md#graphql) | ✅ | ✅ |
+| Read a Dataset Deprecation | ✅ | ✅ | ✅ |
+| Read Dataset Entities (V2) | ✅ | ✅ | ✅ |
+| Create a Tag | ✅ [[Guide]](/docs/api/tutorials/tags.md#create-tags) | ✅ [[Guide]](/docs/api/tutorials/tags.md#create-tags) | ✅ |
+| Read a Tag | ✅ [[Guide]](/docs/api/tutorials/tags.md#read-tags) | ✅ [[Guide]](/docs/api/tutorials/tags.md#read-tags) | ✅ |
+| Add Tags to a Dataset | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags-to-a-dataset) | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags-to-a-dataset) | ✅ |
+| Add Tags to a Column of a Dataset | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags-to-a-column-of-a-dataset) | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags-to-a-column-of-a-dataset) | ✅ |
+| Remove Tags from a Dataset | ✅ [[Guide]](/docs/api/tutorials/tags.md#remove-tags) | ✅ [[Guide]](/docs/api/tutorials/tags.md#add-tags#remove-tags) | ✅ |
+| Create Glossary Terms | ✅ [[Guide]](/docs/api/tutorials/terms.md#create-terms) | ✅ [[Guide]](/docs/api/tutorials/terms.md#create-terms) | ✅ |
+| Read Terms from a Dataset | ✅ [[Guide]](/docs/api/tutorials/terms.md#read-terms) | ✅ [[Guide]](/docs/api/tutorials/terms.md#read-terms) | ✅ |
+| Add Terms to a Column of a Dataset | ✅ [[Guide]](/docs/api/tutorials/terms.md#add-terms-to-a-column-of-a-dataset) | ✅ [[Guide]](/docs/api/tutorials/terms.md#add-terms-to-a-column-of-a-dataset) | ✅ |
+| Add Terms to a Dataset | ✅ [[Guide]](/docs/api/tutorials/terms.md#add-terms-to-a-dataset) | ✅ [[Guide]](/docs/api/tutorials/terms.md#add-terms-to-a-dataset) | ✅ |
+| Create Domains | ✅ [[Guide]](/docs/api/tutorials/domains.md#create-domain) | ✅ [[Guide]](/docs/api/tutorials/domains.md#create-domain) | ✅ |
+| Read Domains | ✅ [[Guide]](/docs/api/tutorials/domains.md#read-domains) | ✅ [[Guide]](/docs/api/tutorials/domains.md#read-domains) | ✅ |
+| Add Domains to a Dataset | ✅ [[Guide]](/docs/api/tutorials/domains.md#add-domains) | ✅ [[Guide]](/docs/api/tutorials/domains.md#add-domains) | ✅ |
+| Remove Domains from a Dataset | ✅ [[Guide]](/docs/api/tutorials/domains.md#remove-domains) | ✅ [[Guide]](/docs/api/tutorials/domains.md#remove-domains) | ✅ |
+| Create / Upsert Users | ✅ [[Guide]](/docs/api/tutorials/owners.md#upsert-users) | ✅ [[Guide]](/docs/api/tutorials/owners.md#upsert-users) | ✅ |
+| Create / Upsert Group | ✅ [[Guide]](/docs/api/tutorials/owners.md#upsert-group) | ✅ [[Guide]](/docs/api/tutorials/owners.md#upsert-group) | ✅ |
+| Read Owners of a Dataset | ✅ [[Guide]](/docs/api/tutorials/owners.md#read-owners) | ✅ [[Guide]](/docs/api/tutorials/owners.md#read-owners) | ✅ |
+| Add Owner to a Dataset | ✅ [[Guide]](/docs/api/tutorials/owners.md#add-owners) | ✅ [[Guide]](/docs/api/tutorials/owners.md#add-owners#remove-owners) | ✅ |
+| Remove Owner from a Dataset | ✅ [[Guide]](/docs/api/tutorials/owners.md#remove-owners) | ✅ [[Guide]](/docs/api/tutorials/owners.md) | ✅ |
+| Add Lineage | ✅ [[Guide]](/docs/api/tutorials/lineage.md) | ✅ [[Guide]](/docs/api/tutorials/lineage.md#add-lineage) | ✅ |
+| Add Column Level (Fine Grained) Lineage | 🚫 | ✅ [[Guide]](docs/api/tutorials/lineage.md#add-column-level-lineage) | ✅ |
+| Add Documentation (Description) to a Column of a Dataset | ✅ [[Guide]](/docs/api/tutorials/descriptions.md#add-description-on-column) | ✅ [[Guide]](/docs/api/tutorials/descriptions.md#add-description-on-column) | ✅ |
+| Add Documentation (Description) to a Dataset | ✅ [[Guide]](/docs/api/tutorials/descriptions.md#add-description-on-dataset) | ✅ [[Guide]](/docs/api/tutorials/descriptions.md#add-description-on-dataset) | ✅ |
+| Add / Remove / Replace Custom Properties on a Dataset | 🚫 | ✅ [[Guide]](/docs/api/tutorials/custom-properties.md) | ✅ |
+| Add ML Feature to ML Feature Table | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#add-mlfeature-to-mlfeaturetable) | ✅ |
+| Add ML Feature to MLModel | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#add-mlfeature-to-mlmodel) | ✅ |
+| Add ML Group to MLFeatureTable | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#add-mlgroup-to-mlfeaturetable) | ✅ |
+| Create MLFeature | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlfeature) | ✅ |
+| Create MLFeatureTable | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlfeaturetable) | ✅ |
+| Create MLModel | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlmodel) | ✅ |
+| Create MLModelGroup | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlmodelgroup) | ✅ |
+| Create MLPrimaryKey | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlprimarykey) | ✅ |
+| Create MLFeatureTable | 🚫 | ✅ [[Guide]](/docs/api/tutorials/ml.md#create-mlfeaturetable) | ✅ |
+| Read MLFeature | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlfeature) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlfeature) | ✅ |
+| Read MLFeatureTable | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlfeaturetable) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlfeaturetable) | ✅ |
+| Read MLModel | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlmodel) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlmodel) | ✅ |
+| Read MLModelGroup | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlmodelgroup) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlmodelgroup) | ✅ |
+| Read MLPrimaryKey | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlprimarykey) | ✅ [[Guide]](/docs/api/tutorials/ml.md#read-mlprimarykey) | ✅ |
+| Create Data Product | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/create_dataproduct.py) | ✅ |
+| Create Lineage Between Chart and Dashboard | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_chart_dashboard.py) | ✅ |
+| Create Lineage Between Dataset and Chart | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_dataset_chart.py) | ✅ |
+| Create Lineage Between Dataset and DataJob | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_dataset_job_dataset.py) | ✅ |
+| Create Finegrained Lineage as DataJob for Dataset | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_datajob_finegrained.py) | ✅ |
+| Create Finegrained Lineage for Dataset | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_dataset_finegrained.py) | ✅ |
+| Create Dataset Lineage with Kafka | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_kafka.py) | ✅ |
+| Create Dataset Lineage with MCPW & Rest Emitter | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_mcpw_rest.py) | ✅ |
+| Create Dataset Lineage with Rest Emitter | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_emitter_rest.py) | ✅ |
+| Create DataJob with Dataflow | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_job_dataflow.py) [[Simple]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_job_dataflow_new_api_simple.py) [[Verbose]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/lineage_job_dataflow_new_api_verbose.py) | ✅ |
+| Create Programmatic Pipeline | 🚫 | ✅ [[Code]](https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/examples/library/programatic_pipeline.py) | ✅ |
diff --git a/docs/automations/ai-docs.md b/docs/automations/ai-docs.md
new file mode 100644
index 00000000000000..bbec33f3bcae64
--- /dev/null
+++ b/docs/automations/ai-docs.md
@@ -0,0 +1,36 @@
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
+
+# AI Documentation
+
+
+
+:::info
+
+This feature is currently in closed beta. Reach out to your Acryl representative to get access.
+
+:::
+
+With AI-powered documentation, you can automatically generate documentation for tables and columns.
+
+
+
+
+
+## Configuring
+
+No configuration is required - just hit "Generate" on any table or column in the UI.
+
+## How it works
+
+Generating good documentation requires a holistic understanding of the data. Information we take into account includes, but is not limited to:
+
+- Dataset name and any existing documentation
+- Column name, type, description, and sample values
+- Lineage relationships to upstream and downstream assets
+- Metadata about other related assets
+
+Data privacy: Your metadata is not sent to any third-party LLMs. We use AWS Bedrock internally, which means all metadata remains within the Acryl AWS account. We do not fine-tune on customer data.
+
+## Limitations
+
+- This feature is powered by an LLM, which can produce inaccurate results. While we've taken steps to reduce the likelihood of hallucinations, they can still occur.
diff --git a/docs/automations/ai-term-suggestion.md b/docs/automations/ai-term-suggestion.md
new file mode 100644
index 00000000000000..27d1716cfc372c
--- /dev/null
+++ b/docs/automations/ai-term-suggestion.md
@@ -0,0 +1,72 @@
+import FeatureAvailability from '@site/src/components/FeatureAvailability';
+
+# AI Glossary Term Suggestions
+
+
+
+:::info
+
+This feature is currently in closed beta. Reach out to your Acryl representative to get access.
+
+:::
+
+The AI Glossary Term Suggestion automation uses LLMs to suggest [Glossary Terms](../glossary/business-glossary.md) for tables and columns in your data.
+
+This is useful for improving coverage of glossary terms across your organization, which is important for compliance and governance efforts.
+
+This automation can:
+
+- Automatically suggests glossary terms for tables and columns.
+- Goes beyond a predefined set of terms and works with your business glossary.
+- Generates [proposals](../managed-datahub/approval-workflows.md) for owners to review, or can automatically add terms to tables/columns.
+- Automatically adjusts to human-provided feedback and curation (coming soon).
+
+## Prerequisites
+
+- A business glossary with terms defined. Additional metadata, like documentation and existing term assignments, will improve the accuracy of our suggestions.
+
+## Configuring
+
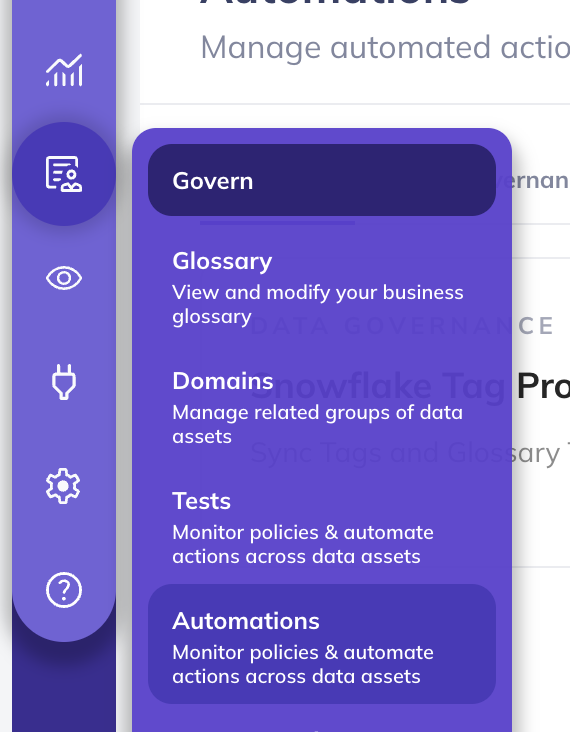
+1. **Navigate to Automations**: Click on 'Govern' > 'Automations' in the navigation bar.
+
+
+
+
+
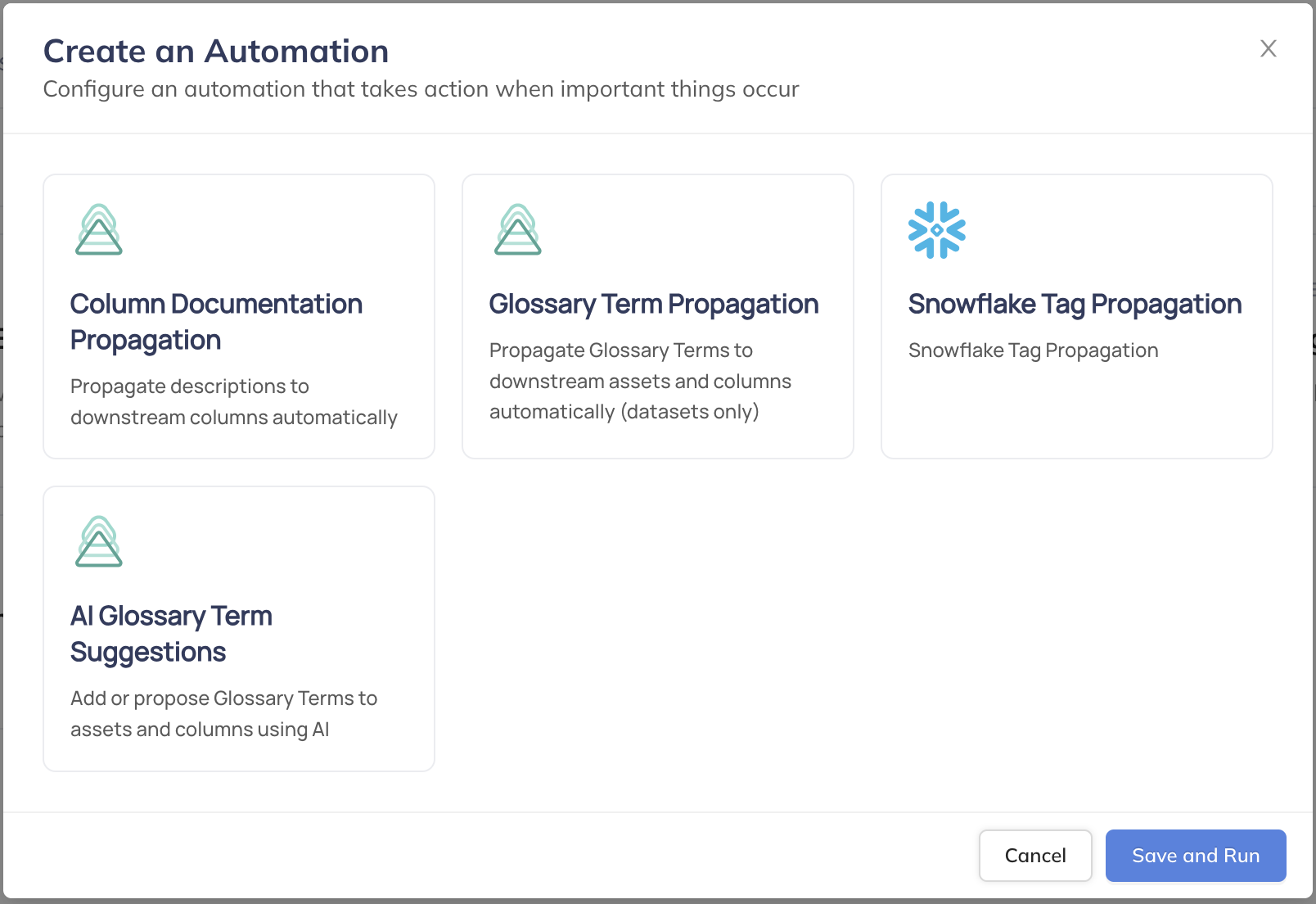
+2. **Create the Automation**: Click on 'Create' and select 'AI Glossary Term Suggestions'.
+
+
+
+
+
+3. **Configure the Automation**: Fill in the required fields to configure the automation.
+ The main fields to configure are (1) what terms to use for suggestions and (2) what entities to generate suggestions for.
+
+
+
+
+
+4. Once it's enabled, that's it! You'll start to see terms show up in the UI, either on assets or in the proposals page.
+
+
+
+
+
+## How it works
+
+The automation will scan through all the datasets matched by the configured filters. For each one, it will generate suggestions.
+If new entities are added that match the configured filters, those will also be classified within 24 hours.
+
+We take into account the following metadata when generating suggestions:
+
+- Dataset name and description
+- Column name, type, description, and sample values
+- Glossary term name, documentation, and hierarchy
+- Feedback loop: existing assignments and accepted/rejected proposals (coming soon)
+
+Data privacy: Your metadata is not sent to any third-party LLMs. We use AWS Bedrock internally, which means all metadata remains within the Acryl AWS account. We do not fine-tune on customer data.
+
+## Limitations
+
+- A single configured automation can classify at most 10k entities.
+- We cannot do partial reclassification. If you add a new column to an existing table, we won't regenerate suggestions for that table.
diff --git a/docs/automations/snowflake-tag-propagation.md b/docs/automations/snowflake-tag-propagation.md
index bdc80376dfb484..c708e40cbdd81e 100644
--- a/docs/automations/snowflake-tag-propagation.md
+++ b/docs/automations/snowflake-tag-propagation.md
@@ -1,4 +1,3 @@
-
import FeatureAvailability from '@site/src/components/FeatureAvailability';
# Snowflake Tag Propagation Automation
@@ -20,22 +19,22 @@ both columns and tables back to Snowflake. This automation is available in DataH
1. **Navigate to Automations**: Click on 'Govern' > 'Automations' in the navigation bar.
-
-
+
+
2. **Create An Automation**: Click on 'Create' and select 'Snowflake Tag Propagation'.
-
-
+
+
-3. **Configure Automation**: Fill in the required fields to connect to Snowflake, along with the name, description, and category.
-Note that you can limit propagation based on specific Tags and Glossary Terms. If none are selected, then ALL Tags or Glossary Terms will be automatically
-propagated to Snowflake tables and columns. Finally, click 'Save and Run' to start the automation
+3. **Configure Automation**: Fill in the required fields to connect to Snowflake, along with the name, description, and category.
+ Note that you can limit propagation based on specific Tags and Glossary Terms. If none are selected, then ALL Tags or Glossary Terms will be automatically
+ propagated to Snowflake tables and columns. Finally, click 'Save and Run' to start the automation
-
-
+
+
## Propagating for Existing Assets
@@ -46,13 +45,13 @@ Note that it may take some time to complete the initial back-filling process, de
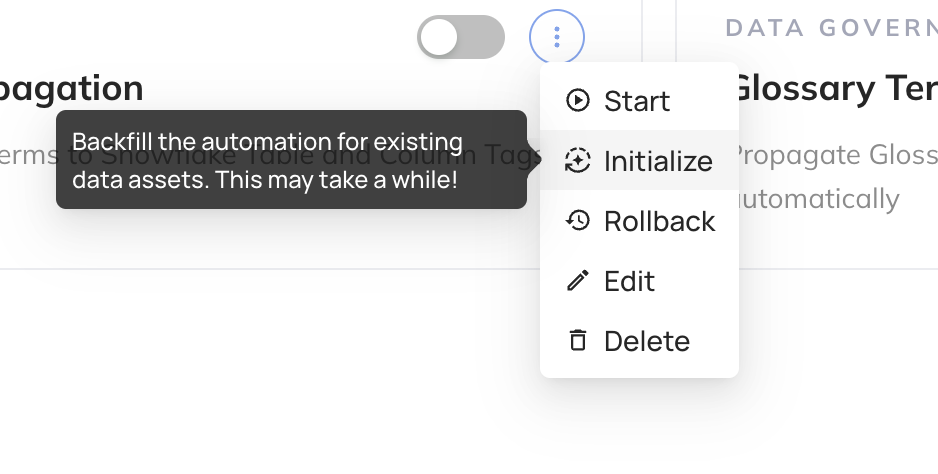
To do so, navigate to the Automation you created in Step 3 above, click the 3-dot "More" menu
-
+
and then click "Initialize".
-
+
This one-time step will kick off the back-filling process for existing descriptions. If you only want to begin propagating
@@ -68,21 +67,21 @@ that you no longer want propagated descriptions to be visible.
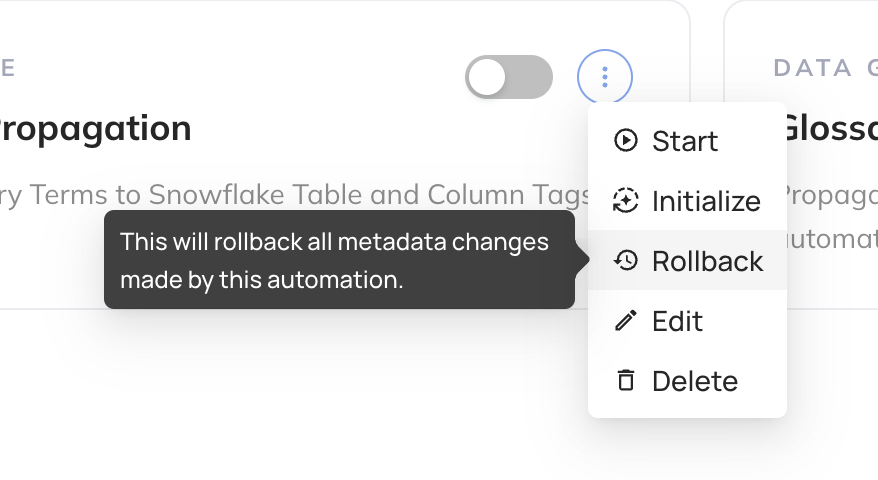
To do this, navigate to the Automation you created in Step 3 above, click the 3-dot "More" menu
-
+
and then click "Rollback".
-
+
This one-time step will remove all propagated tags and glossary terms from Snowflake. To simply stop propagating new tags, you can disable the automation.
## Viewing Propagated Tags
-You can view propagated Tags (and corresponding DataHub URNs) inside the Snowflake UI to confirm the automation is working as expected.
+You can view propagated Tags (and corresponding DataHub URNs) inside the Snowflake UI to confirm the automation is working as expected.
-
-
+
+
diff --git a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
index d1c7e996dd03dc..c1d5b306f187dc 100644
--- a/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
+++ b/metadata-ingestion-modules/airflow-plugin/src/datahub_airflow_plugin/datahub_listener.py
@@ -383,13 +383,11 @@ def on_task_instance_running(
return
logger.debug(
- f"DataHub listener got notification about task instance start for {task_instance.task_id} of dag {task_instance.dag_run.dag_id}"
+ f"DataHub listener got notification about task instance start for {task_instance.task_id} of dag {task_instance.dag_id}"
)
- if not self.config.dag_filter_pattern.allowed(task_instance.dag_run.dag_id):
- logger.debug(
- f"DAG {task_instance.dag_run.dag_id} is not allowed by the pattern"
- )
+ if not self.config.dag_filter_pattern.allowed(task_instance.dag_id):
+ logger.debug(f"DAG {task_instance.dag_id} is not allowed by the pattern")
return
if self.config.render_templates:
diff --git a/metadata-ingestion/src/datahub/ingestion/api/source.py b/metadata-ingestion/src/datahub/ingestion/api/source.py
index 85ae17ddf65291..586b1c610dc756 100644
--- a/metadata-ingestion/src/datahub/ingestion/api/source.py
+++ b/metadata-ingestion/src/datahub/ingestion/api/source.py
@@ -37,6 +37,7 @@
from datahub.ingestion.api.source_helpers import (
auto_browse_path_v2,
auto_fix_duplicate_schema_field_paths,
+ auto_fix_empty_field_paths,
auto_lowercase_urns,
auto_materialize_referenced_tags_terms,
auto_status_aspect,
@@ -444,6 +445,7 @@ def get_workunit_processors(self) -> List[Optional[MetadataWorkUnitProcessor]]:
partial(
auto_fix_duplicate_schema_field_paths, platform=self._infer_platform()
),
+ partial(auto_fix_empty_field_paths, platform=self._infer_platform()),
browse_path_processor,
partial(auto_workunit_reporter, self.get_report()),
auto_patch_last_modified,
diff --git a/metadata-ingestion/src/datahub/ingestion/api/source_helpers.py b/metadata-ingestion/src/datahub/ingestion/api/source_helpers.py
index 372aef707f232f..748d8a8e52a793 100644
--- a/metadata-ingestion/src/datahub/ingestion/api/source_helpers.py
+++ b/metadata-ingestion/src/datahub/ingestion/api/source_helpers.py
@@ -394,6 +394,50 @@ def auto_fix_duplicate_schema_field_paths(
)
+def auto_fix_empty_field_paths(
+ stream: Iterable[MetadataWorkUnit],
+ *,
+ platform: Optional[str] = None,
+) -> Iterable[MetadataWorkUnit]:
+ """Count schema metadata aspects with empty field paths and emit telemetry."""
+
+ total_schema_aspects = 0
+ schemas_with_empty_fields = 0
+ empty_field_paths = 0
+
+ for wu in stream:
+ schema_metadata = wu.get_aspect_of_type(SchemaMetadataClass)
+ if schema_metadata:
+ total_schema_aspects += 1
+
+ updated_fields: List[SchemaFieldClass] = []
+ for field in schema_metadata.fields:
+ if field.fieldPath:
+ updated_fields.append(field)
+ else:
+ empty_field_paths += 1
+
+ if empty_field_paths > 0:
+ logger.info(
+ f"Fixing empty field paths in schema aspect for {wu.get_urn()} by dropping empty fields"
+ )
+ schema_metadata.fields = updated_fields
+ schemas_with_empty_fields += 1
+
+ yield wu
+
+ if schemas_with_empty_fields > 0:
+ properties = {
+ "platform": platform,
+ "total_schema_aspects": total_schema_aspects,
+ "schemas_with_empty_fields": schemas_with_empty_fields,
+ "empty_field_paths": empty_field_paths,
+ }
+ telemetry.telemetry_instance.ping(
+ "ingestion_empty_schema_field_paths", properties
+ )
+
+
def auto_empty_dataset_usage_statistics(
stream: Iterable[MetadataWorkUnit],
*,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/delta_lake/source.py b/metadata-ingestion/src/datahub/ingestion/source/delta_lake/source.py
index 6a52d8fdd89057..98133ca69011e7 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/delta_lake/source.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/delta_lake/source.py
@@ -223,15 +223,14 @@ def ingest_table(
)
customProperties = {
- "number_of_files": str(get_file_count(delta_table)),
"partition_columns": str(delta_table.metadata().partition_columns),
"table_creation_time": str(delta_table.metadata().created_time),
"id": str(delta_table.metadata().id),
"version": str(delta_table.version()),
"location": self.source_config.complete_path,
}
- if not self.source_config.require_files:
- del customProperties["number_of_files"] # always 0
+ if self.source_config.require_files:
+ customProperties["number_of_files"] = str(get_file_count(delta_table))
dataset_properties = DatasetPropertiesClass(
description=delta_table.metadata().description,
diff --git a/metadata-ingestion/src/datahub/ingestion/source/preset.py b/metadata-ingestion/src/datahub/ingestion/source/preset.py
index e51520898103d6..6f53223e000f1b 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/preset.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/preset.py
@@ -56,7 +56,7 @@ class PresetConfig(SupersetConfig):
def remove_trailing_slash(cls, v):
return config_clean.remove_trailing_slashes(v)
- @root_validator
+ @root_validator(skip_on_failure=True)
def default_display_uri_to_connect_uri(cls, values):
base = values.get("display_uri")
if base is None:
diff --git a/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py b/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
index 4b7f710beed08f..4df64c80bad8a8 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/redshift/lineage_v2.py
@@ -334,19 +334,26 @@ def _process_view_lineage(self, lineage_row: LineageRow) -> None:
)
def _process_copy_command(self, lineage_row: LineageRow) -> None:
- source = self._lineage_v1._get_sources(
+ logger.debug(f"Processing COPY command for lineage row: {lineage_row}")
+ sources = self._lineage_v1._get_sources(
lineage_type=LineageCollectorType.COPY,
db_name=self.database,
source_schema=None,
source_table=None,
ddl=None,
filename=lineage_row.filename,
- )[0]
+ )
+ logger.debug(f"Recognized sources: {sources}")
+ source = sources[0]
if not source:
+ logger.debug("Ignoring command since couldn't recognize proper source")
return
s3_urn = source[0].urn
-
+ logger.debug(f"Recognized s3 dataset urn: {s3_urn}")
if not lineage_row.target_schema or not lineage_row.target_table:
+ logger.debug(
+ f"Didn't find target schema (found: {lineage_row.target_schema}) or target table (found: {lineage_row.target_table})"
+ )
return
target = self._make_filtered_target(lineage_row)
if not target:
diff --git a/metadata-ingestion/src/datahub/ingestion/source/redshift/query.py b/metadata-ingestion/src/datahub/ingestion/source/redshift/query.py
index affbcd00b5107b..39370b93b561c5 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/redshift/query.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/redshift/query.py
@@ -283,6 +283,34 @@ def alter_table_rename_query(
AND SYS.query_text ILIKE '%alter table % rename to %'
"""
+ @staticmethod
+ def list_copy_commands_sql(
+ db_name: str, start_time: datetime, end_time: datetime
+ ) -> str:
+ return """
+ select
+ distinct
+ "schema" as target_schema,
+ "table" as target_table,
+ c.file_name as filename
+ from
+ SYS_QUERY_DETAIL as si
+ join SYS_LOAD_DETAIL as c on
+ si.query_id = c.query_id
+ join SVV_TABLE_INFO sti on
+ sti.table_id = si.table_id
+ where
+ database = '{db_name}'
+ and si.start_time >= '{start_time}'
+ and si.start_time < '{end_time}'
+ order by target_schema, target_table, si.start_time asc
+ """.format(
+ # We need the original database name for filtering
+ db_name=db_name,
+ start_time=start_time.strftime(redshift_datetime_format),
+ end_time=end_time.strftime(redshift_datetime_format),
+ )
+
@staticmethod
def additional_table_metadata_query() -> str:
raise NotImplementedError
@@ -317,12 +345,6 @@ def list_insert_create_queries_sql(
) -> str:
raise NotImplementedError
- @staticmethod
- def list_copy_commands_sql(
- db_name: str, start_time: datetime, end_time: datetime
- ) -> str:
- raise NotImplementedError
-
class RedshiftProvisionedQuery(RedshiftCommonQuery):
@staticmethod
@@ -536,34 +558,6 @@ def list_insert_create_queries_sql(
end_time=end_time.strftime(redshift_datetime_format),
)
- @staticmethod
- def list_copy_commands_sql(
- db_name: str, start_time: datetime, end_time: datetime
- ) -> str:
- return """
- select
- distinct
- "schema" as target_schema,
- "table" as target_table,
- filename
- from
- stl_insert as si
- join stl_load_commits as c on
- si.query = c.query
- join SVV_TABLE_INFO sti on
- sti.table_id = tbl
- where
- database = '{db_name}'
- and si.starttime >= '{start_time}'
- and si.starttime < '{end_time}'
- order by target_schema, target_table, starttime asc
- """.format(
- # We need the original database name for filtering
- db_name=db_name,
- start_time=start_time.strftime(redshift_datetime_format),
- end_time=end_time.strftime(redshift_datetime_format),
- )
-
@staticmethod
def temp_table_ddl_query(start_time: datetime, end_time: datetime) -> str:
start_time_str: str = start_time.strftime(redshift_datetime_format)
@@ -941,33 +935,6 @@ def list_insert_create_queries_sql(
# when loading from s3 using prefix with a single file it produces 2 lines (for file and just directory) - also
# behaves like this when run in the old way
- @staticmethod
- def list_copy_commands_sql(
- db_name: str, start_time: datetime, end_time: datetime
- ) -> str:
- return """
- select
- distinct
- "schema" as target_schema,
- "table" as target_table,
- c.file_name
- from
- SYS_QUERY_DETAIL as si
- join SYS_LOAD_DETAIL as c on
- si.query_id = c.query_id
- join SVV_TABLE_INFO sti on
- sti.table_id = si.table_id
- where
- database = '{db_name}'
- and si.start_time >= '{start_time}'
- and si.start_time < '{end_time}'
- order by target_schema, target_table, si.start_time asc
- """.format(
- # We need the original database name for filtering
- db_name=db_name,
- start_time=start_time.strftime(redshift_datetime_format),
- end_time=end_time.strftime(redshift_datetime_format),
- )
# handles "create table IF ..." statements wrong probably - "create command" field contains only "create table if" in such cases
# also similar happens if for example table name contains special characters quoted with " i.e. "test-table1"
diff --git a/metadata-ingestion/src/datahub/ingestion/source/superset.py b/metadata-ingestion/src/datahub/ingestion/source/superset.py
index 858281f880359a..4e40407fba9086 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/superset.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/superset.py
@@ -243,6 +243,8 @@ def get_platform_from_database_id(self, database_id):
return "athena"
if platform_name == "clickhousedb":
return "clickhouse"
+ if platform_name == "postgresql":
+ return "postgres"
return platform_name
@lru_cache(maxsize=None)
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py b/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
index 52934f9f72a70e..5f2709fe426605 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
@@ -613,7 +613,9 @@ def add_known_lineage_mapping(
upstream_urn: The upstream dataset URN.
downstream_urn: The downstream dataset URN.
"""
-
+ logger.debug(
+ f"Adding lineage to the map, downstream: {downstream_urn}, upstream: {upstream_urn}"
+ )
self.report.num_known_mapping_lineage += 1
# We generate a fake "query" object to hold the lineage.
diff --git a/metadata-ingestion/tests/unit/test_mlflow_source.py b/metadata-ingestion/tests/unit/test_mlflow_source.py
index ae5a42bad229d2..d213dd92352e62 100644
--- a/metadata-ingestion/tests/unit/test_mlflow_source.py
+++ b/metadata-ingestion/tests/unit/test_mlflow_source.py
@@ -1,6 +1,6 @@
import datetime
from pathlib import Path
-from typing import Any, TypeVar, Union
+from typing import Any, Union
import pytest
from mlflow import MlflowClient
@@ -11,8 +11,6 @@
from datahub.ingestion.api.common import PipelineContext
from datahub.ingestion.source.mlflow import MLflowConfig, MLflowSource
-T = TypeVar("T")
-
@pytest.fixture
def tracking_uri(tmp_path: Path) -> str:
@@ -46,7 +44,7 @@ def model_version(
)
-def dummy_search_func(page_token: Union[None, str], **kwargs: Any) -> PagedList[T]:
+def dummy_search_func(page_token: Union[None, str], **kwargs: Any) -> PagedList[str]:
dummy_pages = dict(
page_1=PagedList(items=["a", "b"], token="page_2"),
page_2=PagedList(items=["c", "d"], token="page_3"),
diff --git a/metadata-io/src/main/java/com/linkedin/metadata/entity/EntityServiceImpl.java b/metadata-io/src/main/java/com/linkedin/metadata/entity/EntityServiceImpl.java
index 34c98bba01af4e..00feb547ca3300 100644
--- a/metadata-io/src/main/java/com/linkedin/metadata/entity/EntityServiceImpl.java
+++ b/metadata-io/src/main/java/com/linkedin/metadata/entity/EntityServiceImpl.java
@@ -1357,6 +1357,7 @@ private Stream ingestProposalSync(
return IngestResult.builder()
.urn(item.getUrn())
.request(item)
+ .result(result)
.publishedMCL(result.getMclFuture() != null)
.sqlCommitted(true)
.isUpdate(result.getOldValue() != null)
diff --git a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/controller/GenericEntitiesController.java b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/controller/GenericEntitiesController.java
index 7e7929e7f27d37..7427f293c848f5 100644
--- a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/controller/GenericEntitiesController.java
+++ b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/controller/GenericEntitiesController.java
@@ -170,6 +170,9 @@ protected abstract E buildGenericEntity(
@Nonnull UpdateAspectResult updateAspectResult,
boolean withSystemMetadata);
+ protected abstract E buildGenericEntity(
+ @Nonnull String aspectName, @Nonnull IngestResult ingestResult, boolean withSystemMetadata);
+
protected abstract AspectsBatch toMCPBatch(
@Nonnull OperationContext opContext, String entityArrayList, Actor actor)
throws JsonProcessingException, InvalidUrnException;
@@ -560,8 +563,11 @@ public ResponseEntity createAspect(
@PathVariable("entityName") String entityName,
@PathVariable("entityUrn") String entityUrn,
@PathVariable("aspectName") String aspectName,
+ @RequestParam(value = "async", required = false, defaultValue = "false") Boolean async,
@RequestParam(value = "systemMetadata", required = false, defaultValue = "false")
Boolean withSystemMetadata,
+ @RequestParam(value = "createIfEntityNotExists", required = false, defaultValue = "false")
+ Boolean createIfEntityNotExists,
@RequestParam(value = "createIfNotExists", required = false, defaultValue = "true")
Boolean createIfNotExists,
@RequestBody @Nonnull String jsonAspect)
@@ -591,24 +597,38 @@ public ResponseEntity createAspect(
opContext.getRetrieverContext().get().getAspectRetriever(),
urn,
aspectSpec,
+ createIfEntityNotExists,
createIfNotExists,
jsonAspect,
authentication.getActor());
- List results =
- entityService.ingestAspects(
+ Set results =
+ entityService.ingestProposal(
opContext,
AspectsBatchImpl.builder()
.retrieverContext(opContext.getRetrieverContext().get())
.items(List.of(upsert))
.build(),
- true,
- true);
+ async);
- return ResponseEntity.of(
- results.stream()
- .findFirst()
- .map(result -> buildGenericEntity(aspectName, result, withSystemMetadata)));
+ if (!async) {
+ return ResponseEntity.of(
+ results.stream()
+ .filter(item -> aspectName.equals(item.getRequest().getAspectName()))
+ .findFirst()
+ .map(
+ result ->
+ buildGenericEntity(aspectName, result.getResult(), withSystemMetadata)));
+ } else {
+ return results.stream()
+ .filter(item -> aspectName.equals(item.getRequest().getAspectName()))
+ .map(
+ result ->
+ ResponseEntity.accepted()
+ .body(buildGenericEntity(aspectName, result, withSystemMetadata)))
+ .findFirst()
+ .orElse(ResponseEntity.accepted().build());
+ }
}
@Tag(name = "Generic Aspects")
@@ -789,6 +809,7 @@ protected abstract ChangeMCP toUpsertItem(
@Nonnull AspectRetriever aspectRetriever,
Urn entityUrn,
AspectSpec aspectSpec,
+ Boolean createIfEntityNotExists,
Boolean createIfNotExists,
String jsonAspect,
Actor actor)
diff --git a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v2/controller/EntityController.java b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v2/controller/EntityController.java
index 28537b849b68ab..7bec052a9fd5d2 100644
--- a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v2/controller/EntityController.java
+++ b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v2/controller/EntityController.java
@@ -232,6 +232,20 @@ protected GenericEntityV2 buildGenericEntity(
withSystemMetadata ? updateAspectResult.getNewSystemMetadata() : null)));
}
+ @Override
+ protected GenericEntityV2 buildGenericEntity(
+ @Nonnull String aspectName, @Nonnull IngestResult ingestResult, boolean withSystemMetadata) {
+ return GenericEntityV2.builder()
+ .urn(ingestResult.getUrn().toString())
+ .build(
+ objectMapper,
+ Map.of(
+ aspectName,
+ Pair.of(
+ ingestResult.getRequest().getRecordTemplate(),
+ withSystemMetadata ? ingestResult.getRequest().getSystemMetadata() : null)));
+ }
+
private List toRecordTemplates(
@Nonnull OperationContext opContext,
SearchEntityArray searchEntities,
@@ -278,14 +292,25 @@ protected ChangeMCP toUpsertItem(
@Nonnull AspectRetriever aspectRetriever,
Urn entityUrn,
AspectSpec aspectSpec,
+ Boolean createIfEntityNotExists,
Boolean createIfNotExists,
String jsonAspect,
Actor actor)
throws URISyntaxException {
+
+ final ChangeType changeType;
+ if (Boolean.TRUE.equals(createIfEntityNotExists)) {
+ changeType = ChangeType.CREATE_ENTITY;
+ } else if (Boolean.TRUE.equals(createIfNotExists)) {
+ changeType = ChangeType.CREATE;
+ } else {
+ changeType = ChangeType.UPSERT;
+ }
+
return ChangeItemImpl.builder()
.urn(entityUrn)
.aspectName(aspectSpec.getName())
- .changeType(Boolean.TRUE.equals(createIfNotExists) ? ChangeType.CREATE : ChangeType.UPSERT)
+ .changeType(changeType)
.auditStamp(AuditStampUtils.createAuditStamp(actor.toUrnStr()))
.recordTemplate(
GenericRecordUtils.deserializeAspect(
diff --git a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/OpenAPIV3Generator.java b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/OpenAPIV3Generator.java
index e33ad24a6c2486..d179ea8f3a0682 100644
--- a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/OpenAPIV3Generator.java
+++ b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/OpenAPIV3Generator.java
@@ -1100,6 +1100,28 @@ private static PathItem buildSingleEntityAspectPath(
new Operation()
.summary(String.format("Create aspect %s on %s ", aspect, upperFirstEntity))
.tags(tags)
+ .parameters(
+ List.of(
+ new Parameter()
+ .in(NAME_QUERY)
+ .name("async")
+ .description("Use async ingestion for high throughput.")
+ .schema(new Schema().type(TYPE_BOOLEAN)._default(false)),
+ new Parameter()
+ .in(NAME_QUERY)
+ .name(NAME_SYSTEM_METADATA)
+ .description("Include systemMetadata with response.")
+ .schema(new Schema().type(TYPE_BOOLEAN)._default(false)),
+ new Parameter()
+ .in(NAME_QUERY)
+ .name("createIfEntityNotExists")
+ .description("Only create the aspect if the Entity doesn't exist.")
+ .schema(new Schema().type(TYPE_BOOLEAN)._default(false)),
+ new Parameter()
+ .in(NAME_QUERY)
+ .name("createIfNotExists")
+ .description("Only create the aspect if the Aspect doesn't exist.")
+ .schema(new Schema().type(TYPE_BOOLEAN)._default(true))))
.requestBody(requestBody)
.responses(new ApiResponses().addApiResponse("201", successPostResponse));
// Patch Operation
diff --git a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/controller/EntityController.java b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/controller/EntityController.java
index c7d8c72f8a1c39..55cf310be3438d 100644
--- a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/controller/EntityController.java
+++ b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/controller/EntityController.java
@@ -328,6 +328,24 @@ protected GenericEntityV3 buildGenericEntity(
.build()));
}
+ @Override
+ protected GenericEntityV3 buildGenericEntity(
+ @Nonnull String aspectName, @Nonnull IngestResult ingestResult, boolean withSystemMetadata) {
+ return GenericEntityV3.builder()
+ .build(
+ objectMapper,
+ ingestResult.getUrn(),
+ Map.of(
+ aspectName,
+ AspectItem.builder()
+ .aspect(ingestResult.getRequest().getRecordTemplate())
+ .systemMetadata(
+ withSystemMetadata ? ingestResult.getRequest().getSystemMetadata() : null)
+ .auditStamp(
+ withSystemMetadata ? ingestResult.getRequest().getAuditStamp() : null)
+ .build()));
+ }
+
private List toRecordTemplates(
@Nonnull OperationContext opContext,
SearchEntityArray searchEntities,
@@ -472,16 +490,27 @@ protected ChangeMCP toUpsertItem(
@Nonnull AspectRetriever aspectRetriever,
Urn entityUrn,
AspectSpec aspectSpec,
+ Boolean createIfEntityNotExists,
Boolean createIfNotExists,
String jsonAspect,
Actor actor)
throws JsonProcessingException {
JsonNode jsonNode = objectMapper.readTree(jsonAspect);
String aspectJson = jsonNode.get("value").toString();
+
+ final ChangeType changeType;
+ if (Boolean.TRUE.equals(createIfEntityNotExists)) {
+ changeType = ChangeType.CREATE_ENTITY;
+ } else if (Boolean.TRUE.equals(createIfNotExists)) {
+ changeType = ChangeType.CREATE;
+ } else {
+ changeType = ChangeType.UPSERT;
+ }
+
return ChangeItemImpl.builder()
.urn(entityUrn)
.aspectName(aspectSpec.getName())
- .changeType(Boolean.TRUE.equals(createIfNotExists) ? ChangeType.CREATE : ChangeType.UPSERT)
+ .changeType(changeType)
.auditStamp(AuditStampUtils.createAuditStamp(actor.toUrnStr()))
.recordTemplate(
GenericRecordUtils.deserializeAspect(
diff --git a/metadata-service/services/src/main/java/com/linkedin/metadata/entity/IngestResult.java b/metadata-service/services/src/main/java/com/linkedin/metadata/entity/IngestResult.java
index d3f8b507bb14ac..f8b76db110c08f 100644
--- a/metadata-service/services/src/main/java/com/linkedin/metadata/entity/IngestResult.java
+++ b/metadata-service/services/src/main/java/com/linkedin/metadata/entity/IngestResult.java
@@ -2,6 +2,7 @@
import com.linkedin.common.urn.Urn;
import com.linkedin.metadata.aspect.batch.BatchItem;
+import javax.annotation.Nullable;
import lombok.Builder;
import lombok.Value;
@@ -10,6 +11,7 @@
public class IngestResult {
Urn urn;
BatchItem request;
+ @Nullable UpdateAspectResult result;
boolean publishedMCL;
boolean processedMCL;
boolean publishedMCP;
 +
+  +
+  +
+  +
+  +
+ +
+ +
+  +
+  +
+  +
+