ANTLR(ANother Tool for Language Recognition)是一款强大的语法分析器生成工具,基于 LL(*) 分析技术。ANTLR 可以通过解析用户自定义的上下文无关文法,自动生成词法分析器、语法分析器。
ANTLR 支持多种代码生成目标,包括 Java、C++、C#、Python、Go、JavaScript、Swift 等。
ANTLR 是用 Java 编写的,安装 ANTLR 只需要从 ANTLR 官网 下载最新的 jar 包,并放在合适的位置。该 jar 包中包含 ANTLR 工具本体和运行 ANTLR 生成的 java 代码所需的运行时库。如果你需要运行 ANTLR 生成的其他语言的代码,需要从官网额外下载对应语言的运行时库。
从官网下载最新的 jar 包,放在合适的位置。如:
$ mkdir antlr && cd antlr
$ curl -O https://www.antlr.org/download/antlr-4.9.2-complete.jar你可以直接通过 Java 执行 jar 包的方式运行 ANTLR,如:
$ java -jar antlr-4.9.2-complete.jarANTLR 源文件的扩展名为 .g4。ANTLR 会读入 .g4 文件,并生成对应的词法分析程序和语法分析程序。
在 .g4 文件的开头,你需要给文件中定义的语法起个名字,这个名字必须和文件名相同。
// calc.g4
grammar calc;ANTLR 中的注释和 C 语言相同,都是用 // 与 /**/ 作为注释符号。
首先定义词法解析规则,ANTLR 约定词法解析规则以大写字母开头。和 bison 类似。ANTLR 使用 : 代表 BNF 文法中的 -> 或 ::=;同一终结符/非终结符的不同规则使用 | 分隔;使用 ; 表示一条终结符/非终结符的规则的结束。
// calc.g4
LPAREN: '(';
RPAREN: ')';
ADD: '+';
SUB: '-';
MUL: '*';
DIV: '/';
NUMBER: [0-9]+ | [0-9]+ '.' [0-9]* | [0-9]* '.' [0-9]+;
RET: '\r\n' | '\n' | '\r';
WHITE_SPACE: [ \t] -> skip; // -> skip 表示解析时跳过该规则然后定义语法解析规则。ANTLR 约定语法解析规则以小写字母开头,默认将第一个语法规则左部的非终结符作为语法的起始符号。
// calc.g4
calculator: line*;
line: expr RET;
expr: expr ADD term | expr SUB term | term;
term: factor | term MUL factor | term DIV factor;
factor: LPAREN expr RPAREN | NUMBER;前面提到,ANTLR 基于 LL(*) 分析技术,这是一种自顶向下的分析方法。在课程中我们会学到,自顶向下的分析方法不能处理具有左递归的文法。但在 ANTLR 的实现中有一些改进:如果直接左递归规则中存在一个非左递归的选项,那么它仍然是可以处理的,如 expr: expr ADD term | expr SUB term | term; 中的选项 term,但是 ANTLR 仍然不能处理没有非左递归选项的左递归规则以及间接左递归。
ANTLR 隐式地允许指定运算符优先级,规则中排在前面的选项优先级比后面的选项优先级更高,所以你甚至可以把文法改写成这样:
// calc.g4 calculator: line*; line: expr RET; expr: expr MUL expr | expr DIV expr | expr ADD expr | expr SUB expr | NUMBER | LPAREN expr RPAREN;
ANTLR 官方提供了一些常见语言的语法规则文件,见 https://github.com/antlr/grammars-v4
编写完成 ANTLR 的语法文件后,将 .g4 文件作为一项参数,运行 ANTLR,可生成对应的解析程序,并且默认生成 Java 代码。
$ java -jar antlr-4.9.2-complete.jar calc.g4如果你需要生成其他语言的代码,可以在运行 ANTLR 时通过 -Dlanguage= 来指定,如:
# 生成 C++ 代码
$ java -jar antlr-4.9.2-complete.jar -Dlanguage=Cpp calc.g4ANTLR 在完成语法分析后,会生成一棵程序对应的语法树。例如对于如下字符串:
1919 * 810.114
(5 - 1) * 4
生成的语法树如图所示:
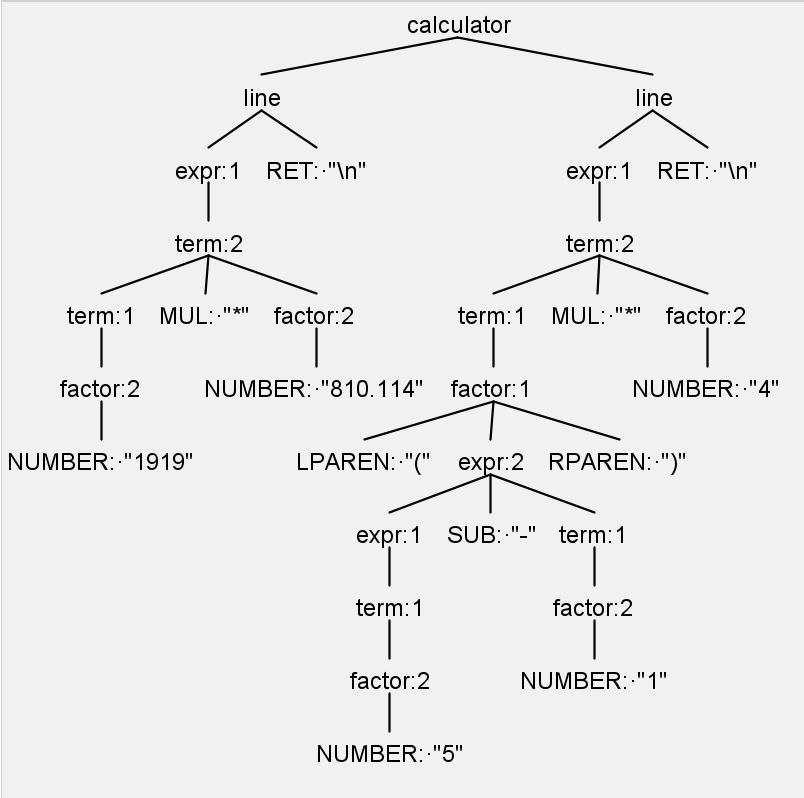
ANTLR 提供了 Listener 和 Visitor 两种模式来完成语法树的遍历,默认生成的是 Listener 模式的代码,如果要生成 Vistor 模式的代码,需要运行选项中加上 -visitor,如果要关闭生成 Listener 模式的代码,需要运行选项中加上 -no-listener。
下面以生成 Java 代码为例进行介绍。
上面的例子中,ANTLR 生成的文件包括 calc.interp、calc.tokens、calcBaseListener.java、calcLexer.interp、calcLexer.java、calcLexer.tokens、calcListener.java、calcParser.java(如果开启了 Visitor 模式,还包括 calcBaseVisitor.java 和 calcVisitor.java)。calcLexer.java 是词法分析程序,calcParser.java 是语法分析程序。*.tokens 文件中包括一系列 token 的名称和对应的值,用于词法分析和语法分析。*.interp 包含一些 ANTLR 内置的解释器需要的数据,用于 IDE 调试语法。
我们重点关注 calcListener.java 和 calcVisitor.java,它们是 Listener 模式和 Visitor 模式的接口,calcBaseListener.java 和 calcBaseVisitor.java 分别是对应接口的默认实现。
在使用 ANTLR 生成的代码时,你需要定义一个类继承 BaseListener 或 BaseVisitor,在其中重写遍历到每个节点时所调用的方法,完成从语法树翻译到 IR 的翻译工作。
Listener 模式中为每个语法树节点定义了一个 enterXXX 方法和一个 exitXXX 方法,如 void enterExpr(calcParser.ExprContext ctx) 和 void exitExpr(calcParser.ExprContext ctx)。遍历语法树时,程序会自动遍历所有节点,遍历到一个节点时调用 enter 方法,离开一个节点时调用 exit 方法,你需要在 enter 和 exit 方法中实现翻译工作。
Vistor 模式中为每个语法树节点定义了返回值类型为泛型的 visitXXX 方法,如 T visitExpr(calcParser.ExprContext ctx)。遍历语法树时,你需要调用一个 Visitor 对象的 visit 方法遍历语法树的根节点,visit 方法会根据传入的节点类型调用对应的 visitXXX 方法,你需要在 visitXXX 方法中实现翻译工作。在翻译工作中,你可以继续调用 visit 方法来手动遍历语法树中的其他节点。
我们可以发现:Listener 模式中方法没有返回值,而 Vistor 模式中方法的返回值是一个泛型,类型是统一的,并且两种模式中的方法都不支持传参。在我们需要手动操纵返回值和参数时,可以定义一些属性用于传递变量。
Listener 模式中会按顺序恰好遍历每个节点一次,进入或者退出一个节点的时候调用你实现的对应方法。而 Vistor 模式中对树的遍历是可控的,你可以遍历时跳过某些节点或重复遍历一些节点,因此在翻译时推荐使用 Visitor 模式。
为了运行 ANTLR 生成的代码,你需要在 CLASSPATH 中加入 ANTLR 的运行时库,Java 版本的运行时库包含在之前下载的 antlr-4.9.2-complete.jar 包中。
编写打印语法树的代码如下:
// Main.java
import org.antlr.v4.runtime.tree.ParseTree;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
public class Main {
public static void main(String[] args) {
String input = "1919 * 810\n" + "123.456 - 654.321\n" + "4. * .6\n" + "1 + 1 * 4\n" + "(5 - 1) * 4\n";
CharStream inputStream = CharStreams.fromString(input); // 获取输入流
calcLexer lexer = new calcLexer(inputStream);
CommonTokenStream tokenStream = new CommonTokenStream(lexer); // 词法分析获取 token 流
calcParser parser = new calcParser(tokenStream);
ParseTree tree = parser.calculator(); // 获取语法树的根节点
System.out.println(tree.toStringTree(parser)); // 打印字符串形式的语法树
}
}在 CLASSPATH 中加入了 ANTLR 的运行时库后,你可以直接使用 javac 来编译 Main.java。
$ echo $CLASSPATH
.:/usr/local/lib/antlr-4.9.2-complete.jar:
$ ls
Main.java calc.tokens calcBaseVisitor.java calcLexer.java calcListener.java calcVisitor.java
calc.interp calcBaseListener.java calcLexer.interp calcLexer.tokens calcParser.java calculator.iml
$ javac Main.java运行程序,打印出字符串形式的语法树。
$ java Main
(calculator (line (expr (term (term (factor 1919)) * (factor 810))) \n) (line (expr (expr (term (factor 123.456))) - (term (factor 654.321))) \n) (line (expr (term (term (factor 4.)) * (factor .6))) \n) (line (expr (expr (term (factor 1))) + (term (term (factor 1)) * (factor 4))) \n) (line (expr (term (term (factor ( (expr (expr (term (factor 5))) - (term (factor 1))) ))) * (factor 4))) \n))在 IDE 中的运行可以自行查阅相关资料
在官网下载 ANTLR C++ Runtime 源文件,将 runtime/src/ 下的代码复制到你认为合适的位置。
编写打印语法树的代码如下:
// main.cpp
#include "calcLexer.h"
#include "calcParser.h"
#include <iostream>
using namespace std;
using namespace antlr4;
int main(int argc, char *argv[]) {
string input("1919 * 810\n123.456 - 654.321\n4. * .6\n1 + 1 * 4\n(5 - 1) * 4\n");
ANTLRInputStream inputStream(input);
calcLexer lexer(&inputStream);
CommonTokenStream tokenStream(&lexer);
calcParser parser(&tokenStream);
tree::ParseTree *tree = parser.calculator();
cout << tree->toStringTree(&parser) << endl;
return 0;
}编写 CMakeLists.txt 如下:
# CMakeLists.txt
project(antlr-calculator CXX)
cmake_minimum_required(VERSION 3.1)
file(GLOB_RECURSE DIR_SRC "src/*.cpp")
file(GLOB_RECURSE DIR_LIB_SRC "third_party/*.cpp")
include_directories(src/)
include_directories(third_party/antlr-runtime)
add_executable(main ${DIR_SRC} ${DIR_LIB_SRC})使用 cmake 来构建项目:
$ mkdir build && cd build
$ cmake ..
$ make运行程序,打印出字符串形式的语法树。
$ ./main
(calculator (line (expr (term (term (factor 1919)) * (factor 810))) \n) (line (expr (expr (term (factor 123.456))) - (term (factor 654.321))) \n) (line (expr (term (term (factor 4.)) * (factor .6))) \n) (line (expr (expr (term (factor 1))) + (term (term (factor 1)) * (factor 4))) \n) (line (expr (term (term (factor ( (expr (expr (term (factor 5))) - (term (factor 1))) ))) * (factor 4))) \n))可参考 https://github.com/kobayashi-compiler/kobayashi-compiler
下面我们将以 Java 为例,介绍如何基于 ANTLR 生成的代码实现一个四则运算计算器。
首先定义一个 Visitor 类,继承 calcBaseVisitor,类型参数决定了所有 visitXXX 方法的返回值类型,这里设为 Void。所有的 visitXXX 方法默认调用父类对象的对应方法。
// Visitor.java
public class Visitor extends calcBaseVisitor<Void> {
@Override
public Void visitCalculator(calcParser.CalculatorContext ctx) {
return super.visitCalculator(ctx);
}
@Override
public Void visitLine(calcParser.LineContext ctx) {
return super.visitLine(ctx);
}
@Override
public Void visitExpr(calcParser.ExprContext ctx) {
return super.visitExpr(ctx);
}
@Override
public Void visitTerm(calcParser.TermContext ctx) {
return super.visitTerm(ctx);
}
@Override
public Void visitFactor(calcParser.FactorContext ctx) {
return super.visitFactor(ctx);
}
}在每个非终结符对应的方法处,填写我们需要编译器在语法树上遍历到该非终结符对应的节点时执行的动作。
public class Visitor extends calcBaseVisitor<Void> {
private double nodeValue = 0.0;
@Override
public Void visitCalculator(calcParser.CalculatorContext ctx) {
// 调用默认的 visit 方法即可
return super.visitCalculator(ctx);
}
@Override
public Void visitLine(calcParser.LineContext ctx) {
// visit expr 对应的子节点,输出 nodeValue
visit(ctx.expr());
System.out.println(" = " + nodeValue);
return null;
}
@Override
public Void visitExpr(calcParser.ExprContext ctx) {
switch (ctx.children.size()) {
case 1 -> {
// 有 1 个子节点,表示匹配的规则是 expr -> term,直接 visit term 对应的子节点
visit(ctx.term());
}
case 3 -> {
// 有 3 个子节点,表示匹配的规则是 expr -> expr ADD term | expr SUB term
// visit expr 和 term 对应的子节点,获取节点对应的值,根据运算符是 ADD 或 SUB 进行不同运算
double lhs = 0.0, rhs = 0.0, result = 0.0;
visit(ctx.expr());
lhs = nodeValue;
visit(ctx.term());
rhs = nodeValue;
if (ctx.ADD() != null) {
result = lhs + rhs;
} else {
result = lhs - rhs;
}
nodeValue = result;
}
}
return null;
}
@Override
public Void visitTerm(calcParser.TermContext ctx) {
switch (ctx.children.size()) {
case 1 -> {
// 有 1 个子节点,表示匹配的规则是 term -> factor,直接 visit factor 对应的子节点
visit(ctx.factor());
}
case 3 -> {
// 有 3 个子节点,表示匹配的规则是 term -> term MUL factor | term DIV factor
// visit term 和 factor 对应的子节点,获取节点对应的值,根据运算符是 MUL 或 DIV 进行不同运算
double lhs = 0.0, rhs = 0.0, result = 0.0;
visit(ctx.term());
lhs = nodeValue;
visit(ctx.factor());
rhs = nodeValue;
if (ctx.MUL() != null) {
result = lhs * rhs;
} else {
result = lhs / rhs;
}
nodeValue = result;
}
}
return null;
}
@Override
public Void visitFactor(calcParser.FactorContext ctx) {
switch (ctx.children.size()) {
case 1 -> {
// 有 1 个子节点,表示匹配的规则是 factor -> NUMBER,将 NUMBER 对应的字符串转换成数字
nodeValue = Double.parseDouble(ctx.NUMBER().getText());
}
case 3 -> {
// 有 3 个子节点,表示匹配的规则是 factor -> LPAREN expr RPAREN,直接 visit expr 对应的子节点
visit(ctx.expr());
}
}
return null;
}
}修改 Main.java,使用我们编写的 Visitor。
// Main.java
import org.antlr.v4.runtime.tree.ParseTree;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
public class Main {
public static void main(String[] args) {
String input = "1919 * 810\n" + "123.456 - 654.321\n" + "4. * .6\n" + "1 + 1 * 4\n" + "(5 - 1) * 4\n";
CharStream inputStream = CharStreams.fromString(input);
calcLexer lexer = new calcLexer(inputStream);
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
calcParser parser = new calcParser(tokenStream);
ParseTree tree = parser.calculator();
Visitor visitor = new Visitor();
visitor.visit(tree);
}
}编译运行代码,输出结果如下:
1919*810
= 1554390.0
123.456-654.321
= -530.865
4.*.6
= 2.4
1+1*4
= 5.0
(5-1)*4
= 16.0
在 ANTLR 生成的代码中,每个 Context 都是语法树上的一个节点类。
每个节点的子节点对象可以通过调用节点的对应名称方法来获得,如一个 ExprContext 对象调用 expr() 方法,根据规则 expr: expr ADD term | expr SUB term | term;,当该 ExprContext 对象对应的规则是 expr: expr ADD term | expr SUB term; 时,expr() 返回对应的子节点;当该 ExprContext 对象对应的规则是 expr: term; 时,expr() 返回 null。
每个 Context 都有一个 accept 方法接受 visitor,访问该节点。 calcBaseVisitor 继承的 AbstractParseTreeVisitor 类中,将 accept 方法封装成了一个 visit 方法,接受一个节点作为参数,访问该节点;AbstractParseTreeVisitor 中还实现了一个 visitChildren 方法,遍历一个节点的所有子节点。
你可以在 ANTLR 官网 了解关于 ANTLR 的更多知识